Before Review
이번 리뷰는 Self-Supervised 기반의 Video Representation Learning 논문을 읽었습니다. Video Scene Segmentation을 위한 논문이지만, 결국 Long-Term 비디오를 이해한다는 관점에서 저의 연구 방향에 도움이 될 것 같아 리뷰하게 되었습니다.
KAUST라고 해서 사우디아라비아에 있는 대학이 있는데 유독 비디오 관련 논문에서 많이 보이네요.
그럼 리뷰 시작하도록 하겠습니다.
Introduction
Video Scene Segmentation은 제가 이전에 [CVPR 2021] Temporally-Weighted Hierarchical Clustering for Unsupervised Action Segmentation라는 논문을 리뷰한 적이 있습니다.
비디오의 프레임 내부의 픽셀 단위로 Segmentation이 아니라 Temporal 축에 대해서 Segmentation을 진행하는 것입니다.
장면이 등장할 때마다 구분할 수 있어야 하기 때문에 꽤나 어려운 Task라 볼 수 있습니다. Long-Term 비디오의 전체 스토리 라인을 알아야 장면을 구분할 수 있는 능력이 생기겠죠. 하지만 Long-Term 비디오를 제대로 이해하는 것은 아직 어려운 상황입니다.

보시면 대화하는 장면과 비행기 전투 장면이 번갈아가면서 등장합니다. 때문에 Video Secene 이해하는 것이 더 어렵게 예측 불가능하다고 볼 수 있습니다.
어려운 난이도 때문에 지도 학습으로 task를 진행할 경우 프레임마다 라벨링이 필요하기 때문에 보통은 Unsupervised나 Self-Supervised로 하는 것 같습니다. 이전에 제가 리뷰했던 논문은 계층적 군집화(Hierarchical Clustering) 기반으로 frame들을 grouping 하면서 action을 구분하는 방법이었습니다.
이번 논문은 Video Scene Segmentation으로 Action Segmentation과 거의 동일하다고 보면 됩니다. 아마 task 자체는 action이 조금 더 semantic 한 정보를 요구하는 반면 Scene Segmentation은 visual 적인 정보를 요구하기 때문에 Video Scene Segmentation이 조금 더 쉬울 거라고 생각이 드네요.
본격적인 얘기를 하기 전에 잠시 비디오를 구성하는 계층적 요소에 대해서 살펴보도록 하겠습니다. 좀 더 자세하게는 비디오를 구성하는 의미론적 단위(semantic granularity)에 대해서 알아보겠습니다.
Snippet or Clip
보통 고정된 길이를 가지는 프레임의 연속된 집합입니다. 비디오 관련 논문에서는 보통 3D CNN Encoder를 많이 사용하고 여기에 들어가는 입력이 Snippet(=Clip) 단위로 고정된 시간 차원의 프레임 텐서가 들어갑니다.
Shot
단일 카메라로 찍힌 프레임의 연속으로, 카메라나 장면에 대해서 별다른 방해나 전환이 없는 프레임의 집합입니다. Snippet(=Clip)의 연속으로도 이루어졌다고 볼 수 있습니다.
Scene
Shot의 연속으로 보통 짧은 story line을 만들 수 있는 정도의 프레임 집합체로 정의합니다. Scene의 정의가 조금 의미론적이라 모호하게 느껴질 수 있을 것 같습니다. 결국 여러개의 Shot으로 구성된 Scene을 구분하는 것은 Challenging 한 Task입니다.
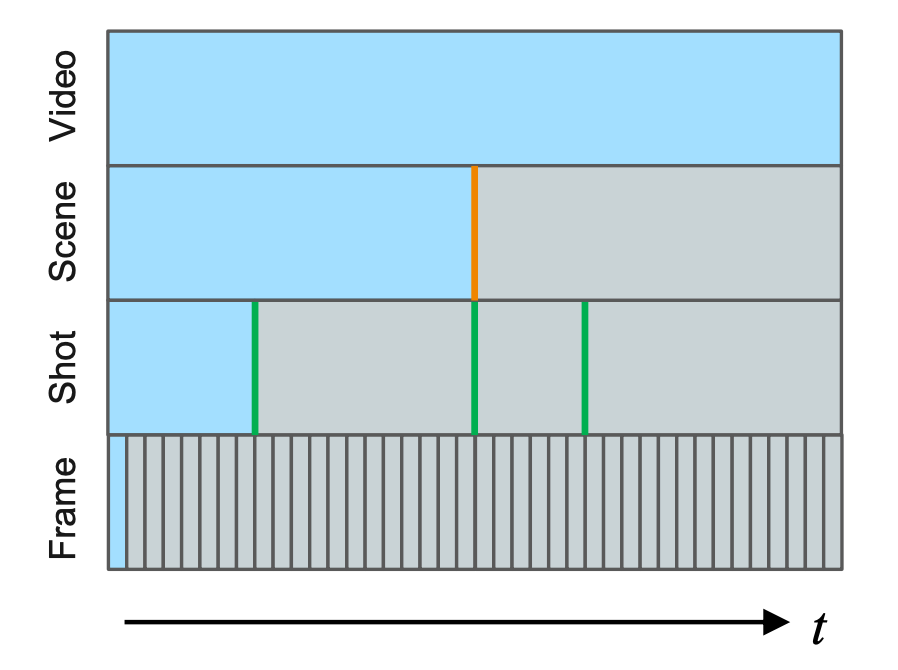
저자는 이렇게 Video Scene Segmentation을 Self-Supervised 기반으로 학습하는 연구를 진행했습니다.
처음인지는 모르겠지만 논문에 Video Scene Segmentation 분야에 Self-Supervised 기법을 도입하는 것은 연구가 많이 진행되지 않았다고 하네요.
결국 저자가 제안하는 방법의 핵심은 "정말로 비슷한 Scene에 대해서 Representation Learning을 진행하자." 입니다.
그래서 저자는 Scene의 Consistency를 기반으로 Positive sampling / Negative sampling을 할 수 있는 방식을 제안하였고 이를 downstream task인 Video Scene Segmentation에 효과적으로 전달할 수 있는 temporal modeling 방법까지 제안합니다.
마지막으로 fair 하고 reasonable 한 비교를 위해 pretraining과 evaluation단계에서 통일성을 가지고 평가를 진행했다고 합니다.
전체적인 논문 컨셉은 이러하고 이제 제안된 방법론에 대해서 알아보도록 하겠습니다.
Methodology
본 논문의 전체 framework는 아래 그림과 같습니다.

Representation Learning Stage가 있고 Video Scene Segmentation Stage가 존재합니다.
Representation Learning Stage에서는 Video에서 Scene끼리의 Consistency를 기반으로 비슷한 Scene에 대해서는 feature representation이 비슷해지고, 다른 Scene에 대해서는 feature representation이 구별되는 것을 목표로 학습이 진행됩니다.
Video Scene Segmentation Stage에서는 서로 다른 Scene에 대해서 feature 간 구별력이 생겼으니 scene에 대해서 직접적으로 segmentation을 하는 down-stream task stage입니다.
우선 Representation Learning Stage부터 보도록 하죠.
Consistency based Representation Learning
방금 전에도 간단하게 설명했지만 Self-Supervised 기반의 Representation Learning은 query shot과 이와 유사한 positive sample에 대해서 feature representation이 유사해지고, query shot과 이와 유사하지 않은 negative sample에 대해서 feature representation이 달라지는 것을 목표로 합니다.
본격적인 설명을 하기에 앞서 몇 가지 용어 정리하고 시작하겠습니다.
- $Query(Q)=Aug_{Q}(X)$ : 쿼리는 $Q$로 정의합니다.
- $Key(K)=Aug_{K}(X)$ : 키는 $K$로 정의합니다.
- $MAP(i)$ : positive sampling을 위한 mapping function입니다. 아래의 예시를 보면 무슨 얘기인지 이해할 수 있습니다.
결국 가장 중요한 것은 positive sample과 negative sample을 얼마나 효과적으로 잘 추출할 것인지가 중요합니다. 일단 몇 가지 전통적인 positive sample selection 방법에 대해서 짚고 넘어가도록 하겠습니다.
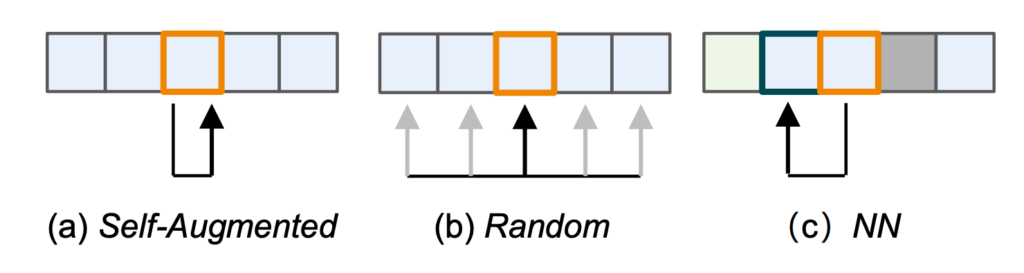
Self-Augmented
말 그대로 동일한 shot을 가지고 변형을 가해 positive sample을 만들어 내는 방식입니다. 쿼리 shot에 대해서 동일한 프레임을 참조하기 때문에 mapping function은 아래와 같이 identity function입니다.
$MAP_{SA}(i)=i$
Random Selection
인접한 두 개의 shot을 선택해서 positive sample이라고 가정하는 방법입니다. 대체적으로 맞지만 인접한 shot이 다른 contents를 포함하고 있는 경우에는 잘못된 representation을 학습할 수도 있습니다. mapping function은 $n$이라는 window size 만큼 정의가 되는데 윈도우 사이즈가 비디오의 길이를 초과하는 경우에 대해서 예외처리를 해주기 위해 max라는 연산으로 정의가 됩니다.
$MAP_{RS}(i)=max(i+j,0),j\in \{ -n,-n+1,\ldots ,n-1,n\} $
$i$ 번째 shot이 있을 때 앞뒤로 $n$개의 shot에 대해서는 positive sample이라는 것입니다. 다만 $i-n$ 번째 shot이 비디오에 존재하지 않을 때는 가장 처음의 shot인 0번째 shot을 참조하겠다는 의미입니다.
Nearest Neighborhood(NN) Selection
앞서 두 방법론에 비해서는 제일 효과적이라고 생각이 드는 방식입니다. Query shot과 제일 representation distance가 가까운 shot을 positive sample이라고 가정하는 방법입니다. 다만 distance를 모두 계산하고 정렬을 해야 하니 연산 복잡도는 조금 올라가겠네요. Mapping function은 가장 representation이 max가 되는 sample를 찾는 $argmax$ 함수로 정의됩니다.
$MAP_{NN}(i)=\arg \max_{j\in I_{M}} f\left( Q[i]\mid \theta_{Q} \right) \cdot f\left( Q[max(j,0\right) ]\mid \theta_{Q} )$
여기서 $I_{M}=\{ i-m,\ldots ,i-1,i+1,\ldots ,i+m\} $은 $NN$ selection을 위한 후보군에 대한 indices라 보면 됩니다. 그리고 $m$이 search region size가 되고 $2m+1$이 sliding window에 대한 크기입니다.
Scene Consistency Selection
위의 방법론들의 방식은 몇 가지 문제점을 가지고 있습니다.
- 같은 장면에서 비슷한 shot이 멀리 존재할 수 있습니다. 그렇게 되어 버리면 random selection 입장에서는 치명적입니다. 같은 장면에 있는 shot을 다른 장면이라 구분하게 되어버리기 때문입니다.
- 같은 장면에서 만들어진 shot끼리 representation이 비슷해야 하고, 다른 장면에 있는 shot에 대해서는 representation이 달라져야 합니다. 하지만 Self-Augmented나 Random Selection은 이러한 목적에 부족한 sampling 방식입니다.
- $NN$ Selection 또한 Representation을 기반으로 Selection을 하지만 trivial(자명해)에 빠질 위험이 있습니다. 자명하게 같은 shot에 대해서 representation이 같아지니, 같은 장면이지만 의미론적으로 다른 shot에 대해서는 약해질 수 있습니다.
저자가 제안하는 scene-consistency based selection 방식은 batch 단위의 online clustering 방식에 기반하여 positive sampling을 진행합니다. 여기서 Clustering 방식은 K-Means를 사용했다고 하네요. Query shot이 속한 Cluster의 Center를 찾아야 하기 때문에 Center 들 중 가장 거리가 가까운 Center를 찾아야 합니다. 따라서 mapping 함수는 아래와 같이 정의되겠네요.
$MAP_{SC}(i)=\arg \min_{j\in I_{C}} \parallel f(Q[i]\mid \theta_{Q} )-f(Q[j]\mid \theta_{Q} )\parallel_{2} $
여기서 $I_{C}=\{ ic_{1},ic_{2},\ldots ,ic_{n_{class}}\} $로 Cluster의 Center들을 나타내는 indices입니다. K-Means Clustering이 거리 기반 군집화 방법론이기 때문에 Center 들 중에서 가장 L2-distance가 가까운 Center가 Positive Sample입니다. 또한 저자는 Center와 Self-Augmented를 합치는 Soft-Center도 학습에 Positive Sample로서 사용해 주었다고 합니다.
$k_{Soft-SC}=\gamma k_{SA}+(1-\gamma )k_{SC}$
$k_{SA}$는 Self-Augmented Selection을 통해 만들어지는 positive sample이고 $k_{SC}$는 Scene Consistency를 통해 만들어지는 positive sample입니다.
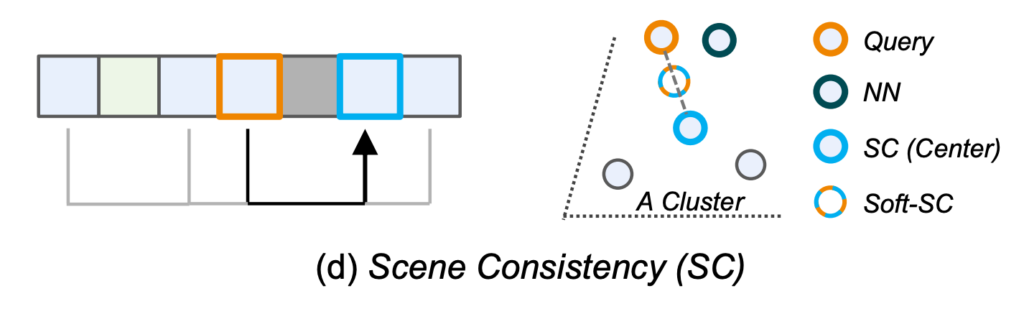
그림으로 보면 위와 같습니다. A라는 Cluster가 있을 때 Cluster의 Center와 Center와 본인의 augmented view를 가지고 만들어지는 Soft-Center를 Positive Sample로 정의하고 있습니다.
Scene Consistency Data Augmentation
학습 초반에는 불안정한 모습이 있기 때문에 너무 과한 color augmentation은 모델입장에서 혼란스러울 수 있다고 합니다.
이렇게 되면 Positive sampling에서도 불안정한 모습을 보이는 데 이는 모델이 semantic 한 정보에 집중하는 것이 아니라 visual 한 정보에 초점이 맞춰져서 그렇다고 합니다. 따라서 저자는 Asymmetric Augmentation을 제안합니다. 간단하게 Query에 대해서는 color transformation을 하지 않고 Key에 대해서는 color transform을 하는 것입니다.
Pytorch-버전의 pseudo code는 아래와 같습니다.

Query Encoder에서는 ColorJitter, RandomGrayscale이 빠진 것을 확인할 수 있습니다.
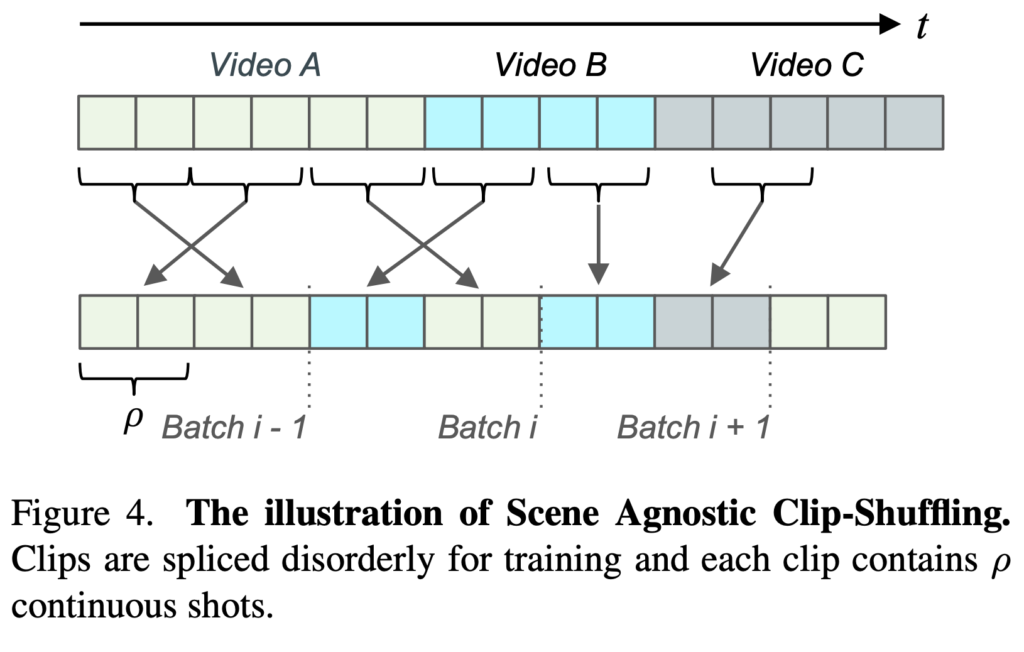
Scene Agnostic Clip-Shuffling
저자는 또한 제한적인 데이터셋의 양을 극복하기 위해 비디오를 조금 섞어주는 augmentation을 해주는데 예를 들어 Video A, Video B, Video C가 저렇게 존재할 때 p개의 연속적인 shot단위로 다시 shuffle 해줘서 Batch를 새롭게 구성하는 augmentation을 해주었다고 합니다.
Negative Sampling
사용하는 Self-Supervised Learning framework에 맞춰 Negative를 정의하면 된다고 합니다. SimCLR 같은 경우는 같은 배치 내에서 Positive가 아닌 sample을 모두 negative로 정의하고 MoCo 같은 경우는 Memory Bank를 이용한 negative sample queue를 사용하고 있습니다. BYOL이나 SimSiam은 negative sample을 사용하지 않고 대신 더욱 non-trival positive sample을 찾는 방식으로 진행된다고 합니다.
- With Negative Samples : $L_{con}=-log\left( \frac{\sum\nolimits_{k\in \left\{ k^{+}\right\} } e^{sim\left( \left( q,k\right) /\tau \right) }}{\sum\nolimits_{k\in \{ k^{+},k^{-}\} } e^{sim\left( (q,k)/\tau \right) }} \right) $
- Without Negative Samples : $L_{con}=-2\sum_{k\in \{ k^{+}\} } (sim(P_{\theta }(q),k_{SG})+sim(P_{\theta }(k),q_{SG}))$
Negative가 있을 때는 InfoNCE Loss를 사용해주고 있는 모습이고, 아래의 Loss는 SimSiam에서 사용하는 Loss랑 비슷한 거 같네요..?
Experiments
Comparison with Existing Methods
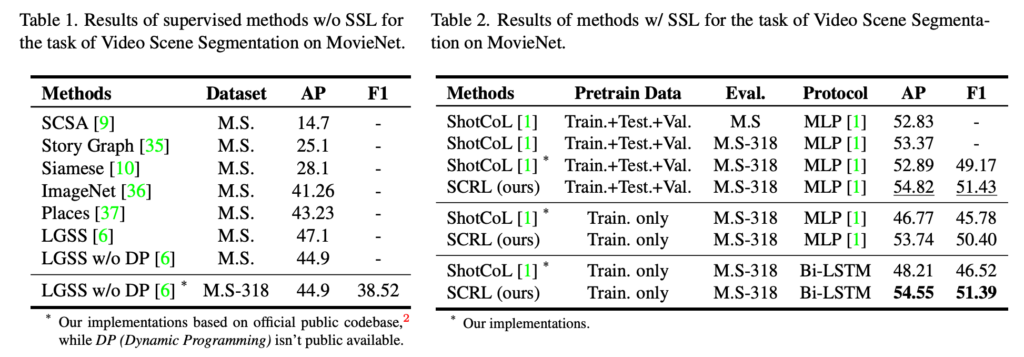
Supervised Learning 방식으로의 비교와 Self-Supervised Learning 방식으로의 비교를 보여주는 두 테이블입니다. 왼쪽의 테이블은 지도학습 방법론들과 본인들이 제안한 방법론을 지도학습으로 학습시켰을 때의 benchmark입니다. 궁금한 건 Dataset이 MS와 MS-318이 있는데 간단히 말해서 MS-318이 annotation이 더 많습니다. 그런데 AP는 왜 동일한지 궁금하네요.. 무튼 그러한 의문은 뒤로하고 동일한 데이터셋인 MS 내에서 다른 지도학습 방법론들에 비해 AP는 가장 높은 성능을 보여주고 있습니다.
오른쪽 table을 보면 결국 AP면에서 SOTA인건 맞는데 Pretrain Data를 Train, Test, Val 모두 사용했을 때는 다른 방법론들과 큰 차이가 나지 않는다는 것이 조금 아쉽네요.
Ablation Study
Positive Sample Selection
먼저 논문의 핵심이라 볼 수 있었던 Positive Sample Selection에 대한 ablation입니다.

Self-Augmented 방식이 성능이 가장 낮고, Scene Consistency 기반의 방식이 가장 높은 성능을 보여주는 것을 확인할 수 있었습니다.
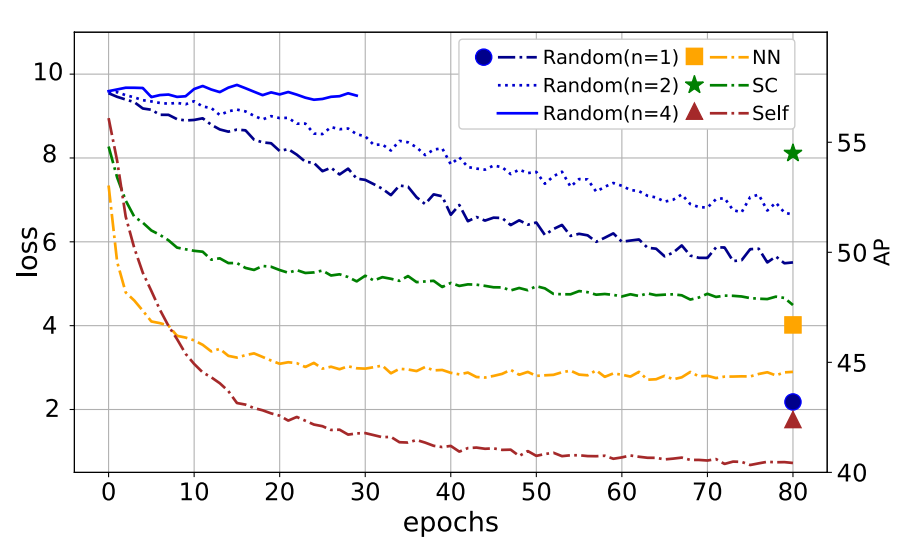
Nearest Neighbor(NN) 방식과 성능차이가 많이 나는 편은 아닌데 epoch별 Loss 함수를 그려보면 NN 방식이 빠르게 수렴하는 것을 확인할 수 있습니다. 이는 앞서 언급한 대로 trival solution에 빠르게 수렴을 하기 때문에 upper bound가 생긴다고 볼 수 있습니다. Scene Consistency 방식은 적당한 convergence rate를 가지고 수렴하면서 가장 높은 성능을 보여주고 있습니다.
Scene Agnostic Clip-Shuffling

위에서 잠시 언급했던 shuffling 방법에 대한 ablation입니다. NN 방식이든 Scene Consistency 방식이든 AP를 의미 있는 정도의 수준으로 향상할 수 있었네요.
Multiple Positive Samples
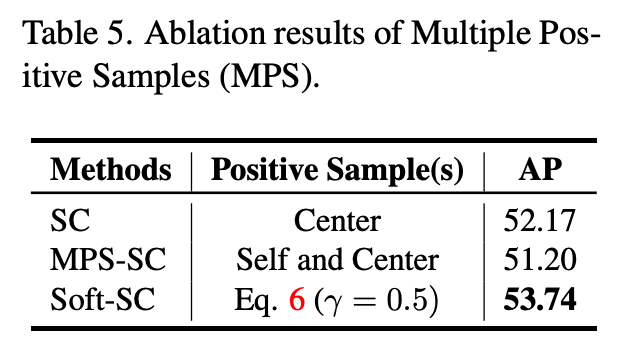
Soft-Center에 대한 ablation인데 최종적으로 단순히 Center만을 사용하는 것보다 Self-Augmented + Center의 Convex Combination이 가장 좋은 성능을 보여주고 있습니다.
Analysis of the Proposed Method
Performance of different Self-Supervised Learning framework

다양한 SSL framework 내에서의 실험입니다. 각 방법론마다 성능의 변화가 좀 크긴 한데 최종적으로 momentum update 기반의 MoCo가 가장 좋은 성능을 보여줍니다. 사실 SimCLR, MoCo, BYOL 논문을 자세히 읽어본 적은 없어 여기에 대해서는 추가적인 저의 설명을 드리기 좀 어려울 것 같습니다.
Visualization of Shot Retrieval
가장 흥미롭게 봤던 부분입니다. 아무래도 그간 Video Retrieval 논문을 쓰다 보니 관련된 실험에 눈이 좀 가네요.

994라는 shot ID를 가지는 shot에 대해서 shot끼리 유사도를 계산했을 때 Top-5를 검색한 결과입니다. Scene Consistency가 확실히 동일한 장면에 대한 shot을 검색했다는 느낌이 가장 강하게 오네요. NN이나 Self 같은 경우는 다른 장면에서 따온 shot인 것들도 몇 개 보입니다. Image-Net은 그냥 다양한 보트의 shot을 검색했네요.
이 정도의 visualization을 확인해보고 나니, 나중에 Video Retrieval 연구를 할 때 본 논문의 컨셉을 적용시켜 볼 수 있을 것 같습니다.
Conclusion
우선, Video Scene Segmentation이라는 낯선 연구 분야의 논문을 읽어봤는데 생각보다 괜찮았네요. 여러 가지 insight를 얻어갈 수 있었습니다. 다만 Contribution이 조금은 약하다고 생각이 드네요.
SSL framework 역시 이전에 제안된 MoCo 방식을 사용했고 본 논문의 가장 핵심은 Positive Sampling 방식을 Scene Consistency 기반으로 설계했다인데, method 측면에서 novelty가 그렇게 강한가 싶기는 하네요.
무튼 이것으로 리뷰 마치도록 하겠습니다. 감사합니다.



