Before Review
본 리뷰에서 다루는 VideoMAE는 말 그대로 MAE를 Video로 가져온 느낌입니다. Image 기반의 MAE가 등장하고 거의 4~5개월 만에 등장한 것이라 볼 수 있습니다. 정말 빠르네요! 방법론 자체는 Image MAE를 거의 그대로 차용을 하였습니다. 그래서 비디오 데이터 자체의 특성만을 이해하면 방법론의 이해는 어려운 편이 아닙니다.
리뷰 시작하도록 하겠습니다.
Preliminaries
Masked AutoEncoder(MAE)
저의 지난 리뷰에서 내용을 가져왔습니다.
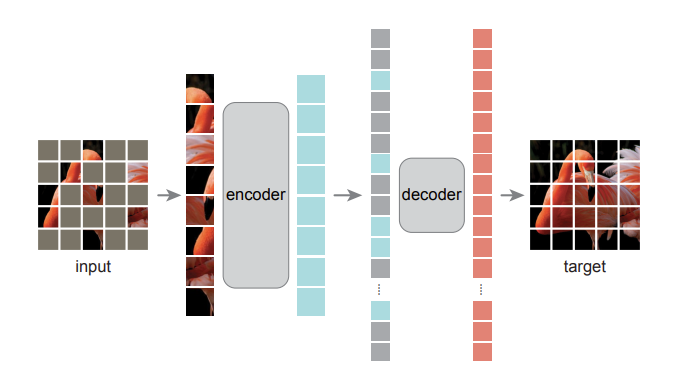
Patch 단위로 나뉜 입력에 대해서 Random으로 마스킹을 진행합니다. 가장 왼쪽 그림에서 input 부분을 보면 군데군데 비어있는 것을 확인하실 수 있을 것입니다. 그리고 여기서 마스킹되지 않은 visible token에 대해서만 ViT encoder를 태워줍니다. 그림으로 보면 확인할 수 있습니다.
이렇게 ViT encoder을 거쳐서 나온 visible token 들과 마스킹된 token들을 모두 모아 디코더의 입력으로 넣어줍니다. 이때 모든 token 들에는 positional embedding이 더해져서 디코더의 입력으로 들어갑니다. 위치 정보 역시 추론 과정에서 중요하기 때문이겠죠.
디코더에서는 reconstruction이 일어나는 데 최종적으로 디코더를 거쳐서 나온 output은 원래 이미지와 동일한 사이즈로 reshape 될 수 있도록 만들어진다고 보시면 됩니다. 결국 인코딩하는 과정은 원래 visible token에서 어떤 정보에 집중을 해야 하는 지를 학습한다고 보면 되고 디코딩 과정에서는 인코딩 된 visible 정보를 토대로 비어있는 정보를 어떻게 복원해야 하는지 학습한다고 볼 수 있겠습니다.
Bernoulli Distribution
베르누이 시행은 두 가지의 결과만이 존재하는 시행을 의미합니다. 동전 던지기 같은 것이 예로 들 수 있죠. 이때 베르누이 시행은 독립 시행입니다. 동전 던지기를 여러 번 한다고 해서 앞의 결과가 나의 시행에 영향을 주지 않는 것과 동일합니다.

확률 분포는 아래와 같습니다. 두 가지 결과만이 존재하기 때문에 $ p $ 아니면 $1-p $입니다. 베르누이 분포가 VideoMAE에서 마스크 생성 시 사용된다고 하여 한번 정리해 봤습니다.
Introduction
Transformer가 2017년 처음 등장하고 BERT, GPT 등등 여러 발전이 있었습니다. 요즘 등장하는 Chat-GPT를 보고 있으면, Transformer의 등장이 딥러닝 연구에 큰 획을 그었다고 해도 과언이 아닐 정도라 볼 수 있을 거 같습니다. NLP의 성공적인 흐름에 따라 Computer Vision에도 VisionTransformer (ViT)라는 것이 등장하였습니다.
21년도에 등장한 이 ViT는 Vision 분야에서 Image Classification, Object Detection-Segmentation-Tracking, Semantic Segmentation, Depth Estimation, Video Recognition 등등 정말 다양한 분야에서 활용되고 있습니다. Multi Head Self Attention(MSA)은 visual content(spatial, temporal) 들의 global dependency를 modeling 하는 데 탁월함을 보였습니다. 또한 inductive bias 역시 attention mechanism에 의해 효과적으로 줄일 수 있었습니다.
그런데 ViT는 학습시키는 데 어려움이 존재한다는 문제가 있었습니다. 더군다나 Video Vision Transformer 들은 이미지로 사전 학습된 VisionTransformer를 가지고 학습해야 성능이 어느 정도 나왔다는 문제점이 존재했습니다. 따라서 비디오 데이터를 가지고도 Video VisionTransformer를 scratch 방식으로 학습할 수 있는 연구가 필요한 시점이었습니다.
이때 고려해야 할 사항은 비디오 데이터의 양은 일반적으로 이미지 데이터에 비해 적은 경우가 많기 때문에 Transformer를 scratch로 학습 시키는 것이 더욱 어려운 상황입니다.
이에 저자는 텍스트 그리고 이미지 도메인에서 이미 성공적으로 연구된 Masking Modeling을 가지고 VideoMAE를 제안합니다. 비디오 클립의 일정 부분을 Masking 하고 다시 원래 비디오 클립을 reconstruction 하는 과정을 통해 일반적인 비디오 데이터의 특성을 관통하는 표현을 얻을 수 있는 것이죠.
하지만 여기서 비디오 데이터와 이미지 데이터 간의 차이를 이해할 필요가 있습니다. 비디오 데이터는 이미지 프레임의 집합으로 이루어진 데이터입니다. 그래서 비디오 데이터의 semantic information은 인접한 프레임의 자연스러운 변화로 인해 발생합니다. 이때 비디오를 30 fps를 가지고 인코딩 되었다고 하면 1초에 30 프레임을 가지고 있는 데이터입니다. 따라서 인접한 프레임끼리는 정말 별 차이가 없는 경우가 대다수입니다. 이러한 데이터의 구조적 차이로 인해 저자는 VideoMAE를 설계할 때 단순히 ImageMAE와 동일한 구조를 사용하면 안 된다고 주장합니다.
저자는 비디오 데이터에 최적화된 VideoMAE를 제안함과 동시에 이전 Masking 연구들(Text, Image)에서는 다뤄지지 않은 발견을 하나 주장합니다. 바로 데이터의 quantity 보다 quality가 더 중요하다는 것입니다. 이 주장에 대한 설명은 실험 파트에서 자세히 다루도록 하겠습니다.
이제 방법론적인 얘기를 시작해 보도록 하겠습니다.
Proposed Method
일단 정적인 이미지와는 다른 비디오의 특성에 대해서 알아보도록 하겠습니다. 프레임의 밀집된 집합으로 구성된 비디오 데이터의 특성을 저자는 두 가지 관점으로 정리하였습니다.
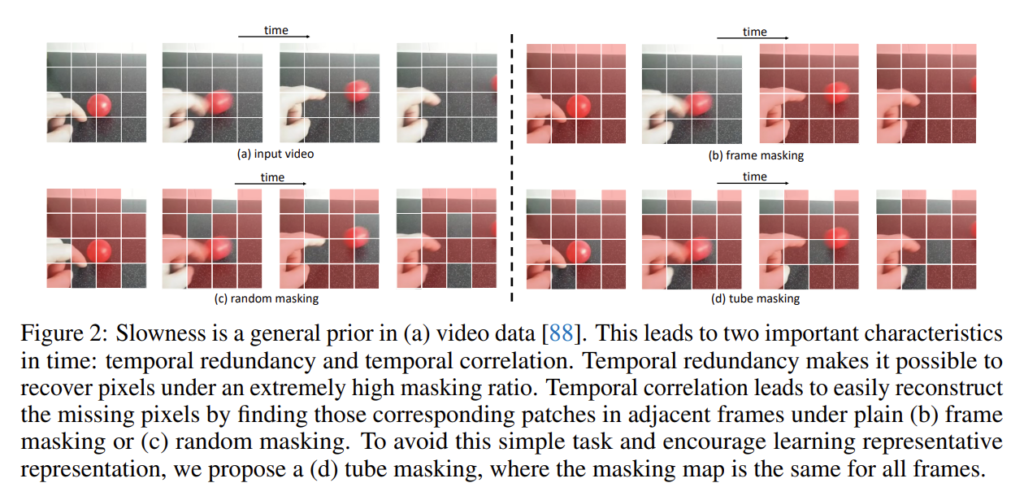
"Temporal redundancy : There are frequently captured frames in a video.
The semantics vary slowly in the temporal dimension"
비디오는 이미지에 비해서도 특히 정보가 너무 많습니다. 따라서 프레임을 많이 보는 것은 모델이 학습하는 입장에서 난도가 낮아지겠죠. 정보가 많이 없는 상태에서 학습을 해야 high-level understanding 능력을 기를 수 있다고 볼 수 있습니다.
따라서 저자는 제안하는 VideoMAE에 대해서 masking ratio를 90%~95%까지 적용하여 학습을 진행했다고 합니다. 또한 temporal redundancy는 motion information을 희미하게 만듭니다. 중첩되는 인접한 프레임을 계속 보면 motion의 변화가 극적으로 나타나지 않습니다. 동영상을 계속 보고 있는 것보다는 깜빡깜빡 보는 것이 더욱 dynamic 하게 변화하겠죠.
이러한 맥락에 따라 저자는 ImageMAE가 75%를 masking 한 것에 비해 VideoMAE는 masking ratio를 90%~95%까지 적용하여 학습을 진행했다고 합니다.
"Temporal correlation : Videos could be viewed as the temporal extension of static appearance,
and therefore there exists an inherent correspondence between adjavent frames"
프레임이 밀집되어 있다 보니 인접한 프레임끼리는 어느 정도 상관관계를 가지겠죠. 이러한 temporal correlation이 masking and reconstruction 과정에서 information leakage를 초래할 수 있다고 합니다.
무슨 의미냐면 인접한 프레임끼리는 중첩된 픽셀들이 많습니다. 중첩된 픽셀들이 많기 때문에 프레임들을 그냥 random masking 하면 사실 인접한 프레임들 모아서 masking 안된 부분만 모아도 쉽게 reconstruction을 수행할 수 있습니다.
따라서 인접한 프레임끼리 masking을 진행할 때는 동일한 위치에서 수행해야 모델이 좀 더 학습에 난이도를 느끼고 high-level semantic information을 학습할 수 있다는 주장입니다.

그림 (c)를 보면 random masking을 수행하고 있는데 여기서 인접한 4개의 프레임에 대해서 masking 되지 않은 영역만 모아도 원래 클립을 쉽게 유추할 수 있습니다. 즉, masking 된 부분에 집중을 하지 못하고 reasoning 능력이 길러지지 않는다는 주장이죠.
따라서 그림 (d)처럼 tube masking이라 해서 인접한 4개의 프레임에 대해 masking 되는 영역을 동일하게 가져가면 모델 입장에서는 쉽지 않게 즉, non-trival 하게 학습을 진행할 수 있습니다.
tube masking을 만드는 과정은 베르누이 분포를 따른다고 합니다. 뭐 0.9 아니면 0.1 이겠네요.
아래의 그림은 전체 구조도를 나타내고 있는데 기존 MAE와 거의 동일합니다.
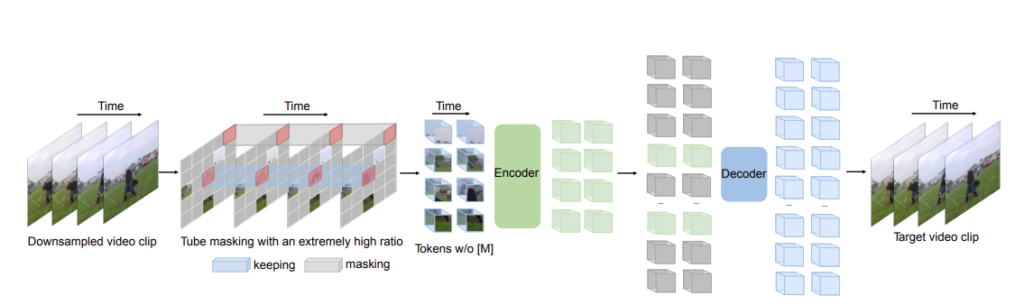
여기서 Backbone으로는 vanilla-ViT를 사용하는데 attention 메커니즘으로는 joint space-time attention를 적용하였다고 합니다. Space-Time attention 은 제곱의 연산량을 가져가지만 앞서 masking을 90% 정도 진행하기 때문에 attention으로부터 발생하는 cost를 줄일 수 있다고 합니다.
제안하는 VideoMAE는 이게 전부입니다. Encoder, Decoder의 구조적 디테일은 appendix에 있다고 하니 궁금하신 분들은 찾아보시길 바랍니다.
Experiments
다음은 실험 부분입니다. 이번 논문도 실험 분석 내용이 조금 많네요.
Ablation Studies
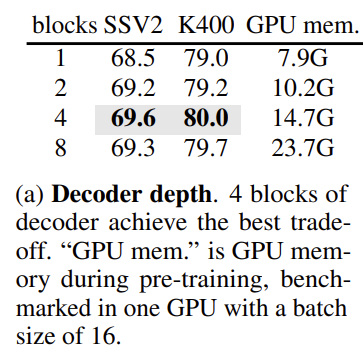
Decoder Design
별다른 내용은 없고 ImageMAE와는 다르게 VideoMAE에서는 decoder의 depth에 따른 유의미한 성능 차이가 존재하네요. width 같은 경우는 테이블에 나와있지 않지만 Encoder의 절반을 default로 사용한다고 합니다. ImageMAE와 동일하게 비대칭적인 encoder-decoder 구조를 가지고 있으며 decoder는 lightweight로 가볍게 가져간다고 합니다.
Masking Strategy
본 논문의 main contribution 중 하나였던 tube mask에 대한 ablation입니다. 일단 극도로 높은 masking 비율인 90%를 사용하는 것이 효과적임을 알 수 있고 plain-random masking 보다는 tube masking이 더 효과가 높은 것을 볼 수 있습니다. 앞서 저자가 주장한 것과 동일하게 random masking은 학습의 난이도를 낮추기 때문에 효과적인 표현을 학습할 수 없다고 했는데 본 실험을 통해 확인할 수 있었습니다.

Reconstruction target
Reconstruction의 대상도 ablation 했습니다. 우선 center frame 하나 만을 예측하는 것은 가장 낮은 성능을 보여주고 있습니다. 성능을 보니 frame 하나 만을 예측하는 것은 trivial solution에 수렴하는 모양입니다. 클립을 예측할 때는 stride에 민감하게 반응하는 것을 확인할 수 있습니다. 음 여기서는 뭔가 큰 의미를 찾기 어려워 보입니다.

Pre-training Strategy
꽤나 중요한 실험입니다. 하나씩 살펴보면 우선 scratch로 학습하는 것은 정말 낮은 성능을 보여주는데 이는 scratch로부터 학습하는 것의 어려움을 보여주는 지표인 것 같네요. 다음으로 ImageNet21 K를 가지고 지도 학습 방식으로 사전 학습을 했다고 합니다. 여기서 ImageNet21K + Kinetics400을 같이 사용하면 61.8->65.2 만큼 성능이 향상되는 것을 볼 수 있습니다. 하지만 VideoMAE 구조를 가지고 Kinetics 만을 가지고 사전 학습을 하면 가장 우수한 성능을 보여주고 있습니다. 이를 통해 기존의 VideoVision Transformer의 학습 어려움을 해결했다는 주장을 할 수 있을 것 같습니다.

Pre-training Dataset
여기서도 비슷한 결과를 보여줍니다. ImageMAE에 비해서는 더 좋은 성능을 보여주고 있습니다. 그런데 Kinetics로 학습하고 SSV2로 finetuning을 하면 SSV2로 사전 학습을 한 것에 비해 성능이 조금 하락하고 있습니다. 이는 pretrain 데이터와 finetuning 데이터가 다를 때 발생하는 이슈에 대해서는 조금 이따 다시 설명하도록 하겠습니다.

Loss function
Loss 함수는 그냥 MSE Loss가 가장 좋다고 합니다. 별 다른 추가 설명은 따로 없었습니다.

Main Results and Analysis
VideoMAE : data-efficient learner
여기서는 scratch 학습 그리고 contrastive pretraing 방식인 MoCo v3 그리고 VideoMAE를 비교하고 있습니다. 일단 VideoMAE가 모든 데이터 셋에 대해서 가장 좋은 성능을 보여주고 있는데 여기서 한 가지 흥미로운 점은 UCF101이나 HMDB51과 같은 데이터의 수가 적은 데이터셋일 때 VideoMAE는 여전히 건재한 성능을 보여준다는 점입니다.
학습 데이터의 수가 적은 상황에서도 효과적으로 사전 학습을 진행할 수 있다는 것은 확실히 강점으로 볼 수 있을 것 같습니다.

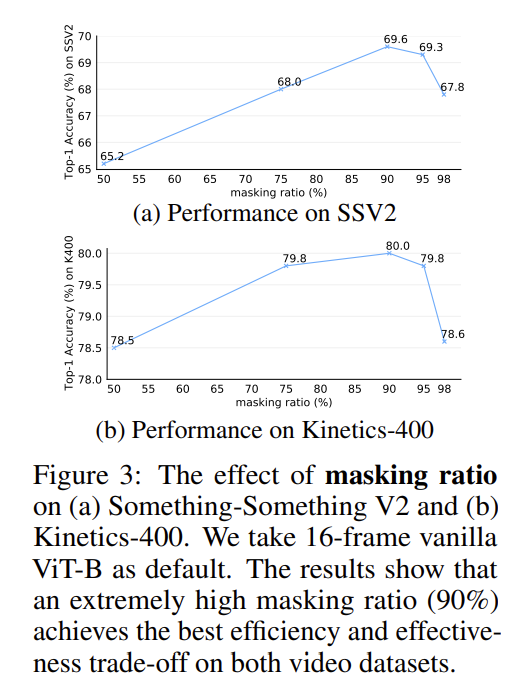
High masking ratio
ImageMAE에서도 했던 ablation과 동일합니다. masking ratio에 따른 성능 비교인데 두 데이터 셋에서 모두 90% 일 때 가장 좋은 성능을 보여주고 있습니다. 이 정도로 지워줘야 temporal redundancy와 temporal correlation 문제를 해결할 수 있다는 것이 맞는 것 같네요.
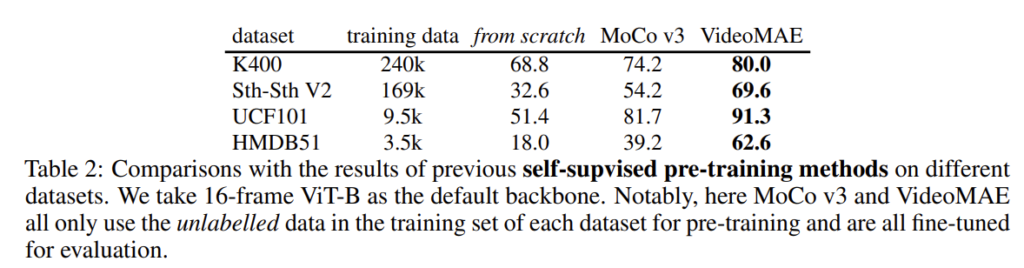
Transfer learning : quality vs quantity
아래의 테이블(4)을 보면 feature transferability를 볼 수 있습니다. Kinetics로 사전 학습 하고 다른 데이터 셋으로 finetuning 했을 때의 결과입니다. 모든 상황에서 MoCo v3 보다 나은 결과를 보여주기 때문에 저자는 feature transferability가 더 좋다고 주장하지만 저는 개인적으로 애초에 VideoMAE의 기본 성능 자체가 높은 거 때문이 아닌가라는 생각이 드네요. 진실은 알 수 없지만 뭔가 조금 애매한 것 같네요..

다음은 꽤 흥미로운 실험입니다. 우선 위의 테이블(4)과 아래의 테이블(2)을 비교하면 SSV2 데이터 셋에 대해서는 pretrain data와 finetuning data를 동일하게 학습하는 것이 성능이 더 높고 UCF101과 HMDB51는 pretrain data와 finetuning data를 다르게 학습하는 것이 성능이 더 높게 나옵니다.
자 이렇게 데이터 셋에 따라 뭔가 반대의 양상을 보여주고 있어 저자는 한 가지 실험을 준비합니다. Large-scale dataset인 SSV2에서 사전 학습 데이터 셋의 양과 학습 시간을 다르게 해서 실험을 진행합니다. 즉, Kinetics로 사전 학습하고 SSV2로 finetuning 하는 상황에서 사전 학습하는 Kinetics의 양을 바꿔가면서 실험을 진행했다는 의미입니다.
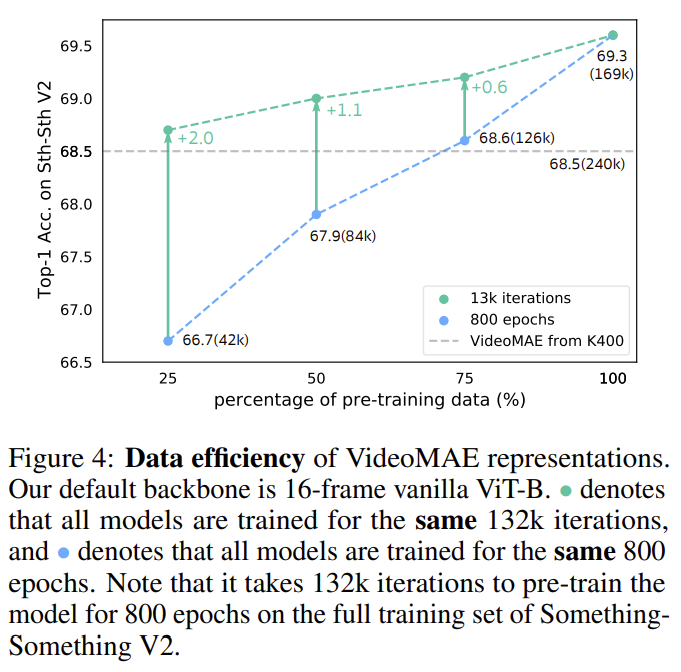
결과는 사전 학습 데이터의 양을 줄여도 학습 시간을 충분히 가져가면 오히려 성능이 더 높아지는 경향을 보여주고 있습니다. 이를 통해 domain shift(Kinetics->SSV2) 역시 중요한 요인이지만 데이터의 '질'도 중요하다는 것을 보여주고 있습니다. Kinetics의 양을 1/4 정도로 줄여도 전부 사용하는 것보다 더 높은 성능을 달성할 수 있는 것을 보아 VideoMAE는 적은 데이터의 상황에서도 효과적으로 학습할 수 있다는 것을 다시 한번 보여주고 있습니다.
Transfer learning : downstream action detection

다음은 AVA 데이터 셋을 이용한 action detection에 대한 down stream task에 대한 실험입니다. action recognition 말고도 더 복잡한 detection task에서 효과적인 표현을 보여주고 있습니다. 또한 모델을 scale-up 시켜도 성능이 향상되는 것을 보아 detection task에서도 model의 scalability가 보장되는 것을 볼 수 있습니다.
Comparison with the state of the art

SSV2에서의 action recognition에 대한 down stream benchmarking입니다. 다른 방법론 대비 FLOPs를 더 적게 가져가면서 더 높은 성능을 보여주고 있습니다. 더군다나 다른 방법론은 extra data를 사용해야만 SSV2에서 어느 정도 수렴을 하는 반면 VideoMAE는 별다른 extra data 없이도 좋은 성능을 보여주고 있다는 점이 인상 깊습니다.

Kinetics에서도 동일한 경향성을 보여주고 있습니다.
Conclusion
일단 MAE를 VideoMAE로 최적화시켜줬다는 것에 감사하며 코드는 감사히 먹도록 하겠습니다. 그리고 실험에서 보여주는 performance 역시 인상 깊었던 것 같습니다. 실험 부분에서 보여주는 성능이 인상 깊어 저도 돌려보려고 하는데 실험에 GPU가 64개 필요하다고 합니다. 그래서 일단 각을 한번 보고 V100 8장 정도로 타협할 수 있는 수준이라면 한번 돌려보려고 합니다.
리뷰 읽어주셔서 감사합니다.



