Before Review
제가 이전에 VideoMAE를 리뷰한 적이 있습니다. VideoMAE는 MAE가 나오고 얼마 지나지 않아서 NIPS 2022에 개제가 되었는데 이번에는 CVPR 2023에 바로 version2 공개가 됐네요.
A100 80G 64장을 가지고 pretrain을 진행했다고 하는데 여전히 엄두가 나지 않는 GPU 자원입니다.
이번 논문도 VideoMAE처럼 굉장히 간단하지만 VideoMAE나 MAE를 모른다면 읽기 어려울 수 있으므로 익숙지 않은 분들은 저의 지난 리뷰를 먼저 참고하시길 바랍니다.
Introduction
요즘 인공지능 분야에서 핫한 토픽은 뭘까요? Generative AI, Multimodal 등등 있지만 결국 이들은 하나로 묶어줄 수 있는 키워드가 있습니다. 바로 Foundation Model입니다.
Foundation Model 은 보통 라벨이 없는 원시 데이터를 바탕으로 Self-Supervised Learning을 초 대규모로 진행하여 광범위한 down-stream task에 응용이 가능한 인공지능 모델을 의미합니다. 기존에 Single-Task를 target으로 한 (예를 들어 ImageNet을 Classification 용도로 사전학습한 모델) 모델들은 다양한 down-stream task에서 generalization이 어렵다는 한계가 있죠.

아직 Vision Domain에서는 갈길이 좀 남아 있는 것 같지만, Text Domain에서는 LLM 연구 (e.g., ChatGPT)들이 큰 성과를 거두고 있죠. 개인적으로 저는 연구를 하는 관점에서 직접적인 활용은 하지 않지만 문장 번역, 오탈자 수정 등 영어 작문 할 때만큼은 요긴하게 사용하고 있습니다.
CLIP과 Statble Diffusion 기술이 합쳐진 DALL-E 역시 image-text data에 기반한 Foundation Model 중 하나라고 볼 수 있습니다.
아직까지 저는 필요한 figure를 직접 만들고 있는데 기술이 좀 더 정교해지면 저도 본격적으로 활용해 볼 생각은 있습니다.
본 논문에서도 Large-Language Model(LLM) 연구들은 이미 data size나 model capacity를 잘 scaling 하여 현재 놀라운 퍼포먼스들을 보여주고 있다고 서술합니다. 그리고 이러한 노하우가 기업들의 핵심 기술이 되는 것이겠죠.
하지만 Vision Domain에서 scaling 연구는 아직 활발하게 이루어지지 않고 있다고 저자는 얘기합니다. 특히 Image Data에 비해 Video Data는 더 어려운 상황입니다. 텍스트 데이터나 이미지 데이터에 비해 볼륨이 너무 크기 때문이죠. 본 논문의 저자들은 이러한 어려움을 극복하고자 간단하지만 효과적인 VideoMAE scaling 방법을 제안합니다.
저자가 밝히는 VideoMAE의 한계는 아래와 같습니다.
"First, we find computational cost and memory consumption is the bottleneck of scaling
VideoMAE on the current GPUs with limited memory"
비록 VideoMAE가 극단적으로 높은 masking ratio (90~95%)와 비대칭적인 인코더 디코더 구조를 가져가기 때문에 어느 정도 사전학습 단계의 효율성을 가져갔다고는 하지만 ViT-g와 같이 비디오 데이터에서는 다뤄진 적 없는 수십억의 파라미터를 가지는 모델을 사전학습 할 때는 여전히 효율성 측면에서 문제가 생긴다고 합니다. 따라서 저자는 학습 단계에서의 효율성을 추구하기 위해 간단하지만 효과적인 dual masking을 제안합니다.
"Second, MAE is still demanding for large data and billion-level video transformer
tends to overfit on relatively small data"
다음으로 MAE 기반의 사전학습은 정말 많은 데이터를 필요로 하고 finetune 단계에서 small data에 대해서는 여전히 overfit 한다는 주장입니다. 비디오에서 사용되는 Kinetics 400은 0.24M 개의 비디오를 학습 데이터로 사용하는 반면에 이미지에서 사용되는 ImageNet-22k는 14.2M 이미지를 가지고 있습니다. 저자는 이러한 문제를 극복하기 위해 Kinetics만 활용하는 것이 아니라 다른 공공 데이터도 모두 활용할 수 있는 HybridDataset을 제안합니다.
"Finally, it is still unknown how to adapt the billion level pre-trained model by VideoMAE"
마지막으로 수십억의 파라미터를 가지고 사전학습된 VideoMAE를 어떻게 finetune 해야 하는지에 대해서는 자세히 연구된 것이 없다는 것입니다. 나이브하게 billion-level로 사전학습된 VideoMAE를 굉장히 작은 small dataset을 가지고 finetuning 하는 것은 sub-optimal 할 것이라는 주장입니다. 실제로 이미지 도메인에서 intermediate fine-tuning 기법들이 연구되고 있는 지금, 저자도 비디오를 위해서 이러한 부분을 고민했다고 합니다.
그렇다면 이제 저자는 위의 문제점들을 해결하기 위한 방법으로는 무엇을 고안했는지 알아보도록 하겠습니다.
Approach
Revisiting VideoMAE
논문에 있는 설명을 하는 것보다, 저의 지난 리뷰에서 일부분 내용을 발췌하였습니다.
“Temporal redundancy : There are frequently captured frames in a video.
The semantics vary slowly in the temporal dimension”
비디오는 이미지에 비해 정보가 매우 많이 존재합니다. 따라서 프레임을 많이 보는 것은 모델이 학습하는 입장에서 난도가 낮아지겠죠. 정보가 많이 없는 상태에서 학습을 해야 high-level understanding 능력을 기를 수 있다고 볼 수 있습니다. 따라서 저자가 제안하는 VideoMAE에서는 대해서 masking ratio를 90%~95%까지 적용하여 학습을 진행했다고 합니다. 또한 temporal redundancy는 motion information을 희미하게 만듭니다. 중첩되는 인접한 프레임을 계속 보면 motion의 변화가 극적으로 나타나지 않습니다. 동영상을 계속 보고 있는 것보다는 깜빡깜빡 보는 것이 더욱 dynamic 하게 변화하겠죠.
이러한 맥락에 따라 저자는 ImageMAE가 75%를 masking 한 것에 비해 VideoMAE는 masking ratio를 90%~95%까지 적용하여 학습을 진행했다고 합니다.
“Temporal correlation : Videos could be viewed as the temporal extension of static appearance,
and therefore there exists an inherent correspondence between adjavent frames”
프레임이 밀집되어 있다 보니 인접한 프레임끼리는 어느 정도 상관관계를 가지겠죠. 이러한 temporal correlation이 masking and reconstruction 과정에서 information leakage를 초래할 수 있다고 합니다. 무슨 의미냐면 인접한 프레임끼리는 중첩된 픽셀들이 많습니다. 중첩된 픽셀들이 많기 때문에 프레임들을 그냥 random masking 하면 사실 인접한 프레임들 모아서 masking 안된 부분만 모아도 쉽게 reconstruction을 수행할 수 있습니다. 따라서 인접한 프레임끼리 masking을 진행할 때는 동일한 위치에서 수행해야 모델이 좀 더 학습에 난이도를 느끼고 high-level semantic information을 학습할 수 있다는 주장입니다.
Dual Masking for VideoMAE
비록 VideoMAE가 masking을 90%나 진행하고 디코더를 가볍게 가져감으로 연산량을 많이 줄인 것은 사실이지만 계속 얘기했던 것처럼 billion-level의 초거대 model을 사전학습 시킬 때는 bottleneck이 발생합니다. 따라서 현재의 VideoMAE 구조는 더욱 효율적으로 변화해야 하는 것이죠.
저자는 이를 위해 Dual Masking을 제안합니다.

원래 VideoMAE를 생각해 보도록 하겠습니다.
Encoder는 90%에 해당되는 높은 masking ratio를 가지는 tube mask를 통해서 처리하는 token이 많지 않습니다. 하지만 Decoder는 상황이 조금 다르죠. Visible, Invisible Token을 모두 입력으로 받기 때문에 Encoder에 비해서는 들어오는 데이터의 양이 10배 더 많습니다.
저자는 이러한 비 효율적인 구조를 해결하고자 Decoder에도 마스킹을 제안합니다.
예를 들어 100개의 토큰이 있다고 가정한다면 Masking을 두 번 하는 것이죠. 한 번은 Encoder를 위해 한번은 Decoder를 위해
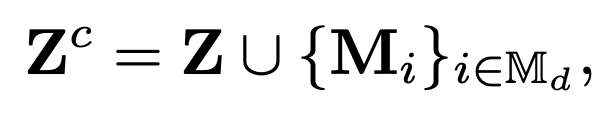
Z는 Encoder에서 나온 Latent Feature입니다. 즉, Encoder Masking 과정에서 Masking 되지 않고 남아있는 token들이 Encoder를 거쳐서 나온 것입니다. Mi는 Decoder Masking 과정에서 Masking 되지 않고 남아있는 learnable token입니다. 그리고 이렇게 두 번 마스킹된 것들을 합쳐서 Decoder의 입력으로 넣어주는 것입니다.
이제 VideoMAE v2의 디코더는 저 Zc를 가지고 reconstruction을 진행합니다. 기존의 모든 token을 사용하는 것보다 디코더가 처리하는 양이 줄었기 때문에 효율적이라고 볼 수 있겠죠.
나머지는 이제 모두 동일합니다. Zc를 가지고 reconstruction 한 다음에 MSE Loss를 통해서 학습을 진행합니다.
Scaling VideoMAE
Model scaling
이번 VideoMAE v2는 기존 VideoMAE에 비해 좀 더 효율성을 추구했기 때문에 model scaling up 과정에서도 한 번도 다뤄져 본 적이 없는 ViT-g에 대해서도 scaling을 성공했다고 합니다.
Data scaling
기존 VideoMAE는 Kinetics라는 비교적 작은 데이터 셋에서만 사전학습을 한 반면에 저자는 universal pretrain model을 만들고자 data diversity를 늘리기 위해 UnlabeledHybrid라는 데이터 셋을 제안한다고 합니다.
General Webs, Youtube, Instagram, Movies 등의 소스를 활용하여 데이터를 구축했다고 합니다. 기존 Kinetics가 0.24M 개의 비디오를 가지고 있던 반면 새롭게 구축된 UnlabeledHybrid는 1.35M 개의 비디오를 사용한다도 합니다. 거의 6배가 늘었네요.
Video Transformer를 이 정도 규모의 데이터셋으로 사전학습 하는 것은 아직 다뤄져 본 적이 없기 때문에 저자는 의미가 있다고 주장하네요.
Progressive training
기존 VideoMAE는 finetune을 사전학습 끝나고 바로 진행하였는데 VideoMAE v2는 model scale도 그렇고 data scale도 상황이 조금 달라졌으니 좀 더 점진적인 방식을 제안합니다.
Target으로 하는 작은 데이터 셋으로 바로 finetune 하는 것보다 좀 더 큰 규모의 라벨 데이터셋으로 supervision을 주고 그다음에 진짜 finetune을 하는 것이죠. 여기서는 labeledhybrid라는 데이터 셋을 제안합니다. 사실 Kinetics 400, 600, 700 합친 것이긴 합니다. 이 labeledhybrid를 가지고 post-pretrain을 하고 나서야 우리가 target으로 하는 downstream task에 대해서 finetune을 진행합니다.
논문의 내용은 다 설명했고 이제 실험 분석 파트로 넘어가 보도록 하겠습니다.
Experiments
일단 먼저 VideoMAE V2의 core design에 대한 실험을 보도록 하겠습니다. 그다음에 3가지 down stream task에 대한 finetuning 성능을 확인하면 될 것 같습니다.
Main Results
Results on dual masking
일단 저자가 VideoMAE에 대해서 원복을 진행했을 때 기존의 성능보다 조금 더 높은 70.28의 성능으로 원복을 했다고 합니다. 그다음에 두 가지 마스킹 전략을 디코더에 적용해 보았다고 합니다. Frame Masking과 Random Masking입니다. Frame Masking은 단순히 프레임 절반을 Masking 하여 날리는 것이고 Random Masking은 고정된 Tube Masking이 아닌 정말 Random Masking입니다.
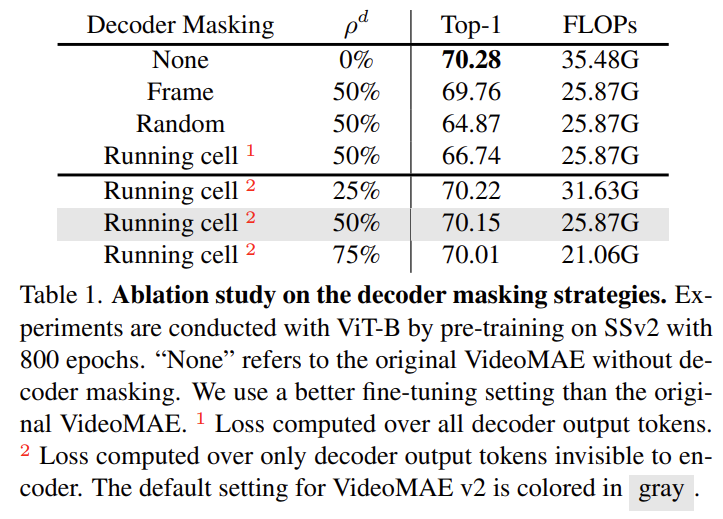
Frame Masking과 Random Masking은 기존 VideoMAE에 비해 성능이 꽤 많이 떨어지는 것을 확인할 수 있습니다. 그럼 Dual Masking을 했을 때의 결과를 살펴보도록 하겠습니다. Running cell 부분을 보면 되는데 숫자 1이 적혀있는 실험은 Dual Masking을 했지만 Loss 계산은 전부 다 했을 때입니다. 숫자 2가 적혀있는 실험은 Dual Masking을 통해 실제 Loss 계산에서도 일부분만 진행한 것을 의미합니다.
결과적으로 Dual Masking을 진행하고 Decoder Masking을 50% 진행했을 때 기존 VideoMAE와 거의 근접한 성능을 달성한 것을 확인할 수 있습니다. 정확도가 70.28->70.15 수준으로 유지시키면서 FLOPs가 많이 줄어들었으니 효과적이라고 볼 수 있겠네요.

또한 학습 시간관점에서도 Dual Masking을 진행하는 것이 1.5~1.7배 정도 더 빠르다는 것을 보여주고 있습니다. 한정된 GPU memory를 가진 상황에서는 거대 모델을 학습시키기 위해서는 이러한 지표 역시 중요하게 작용하죠.
Results on data scaling
기존 VideoMAE v1과의 차이를 주목해서 살펴보면 VideoMAE v1은 Kinetics를 활용하여 사전학습 하거나 SSV2를 활용하여 사전학습한 반면에 VideoMAE v2는 새롭게 구축된 거대 데이터셋인 UnlabeledHybrid를 가지고 사전학습 하였습니다. 더욱 풍부한 데이터셋을 사전학습에 사용한 결과 모든 model scale에서 더 좋은 performance를 보여주고 있습니다.


단순하게 데이터를 많이 썼으니깐 성능이 더 좋겠지라고 생각할 수 있겠지만 학습 과정에서의 효율성을 생각해 보면 분명히 의미 있는 결과라고 생각합니다.
Results on progressive pre-training
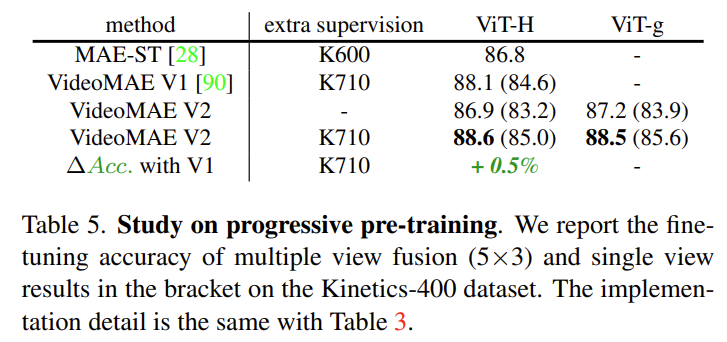
저자가 제안한 progressive pre-training 방식에 대한 실험입니다. 즉, finetune을 바로 하는 것이 아니라 사전 학습 끝나고도 대용량의 supervision을 토대로 성능을 boosting 하는 것입니다. 실제로 extra supervision을 주는 것이 주지 않는 것에 비해 86.9->88.6의 향상을 일으켰습니다. VideoMAE v1에 대해서 extra supervision을 줬을 때와 비교해도 88.1->88.6으로 더 좋은 성능을 보여주고 있습니다.
좋은 게 좋은 거라고 pretrain도 대용량으로 하고 post-pretrain도 대용량으로 해버리니 성능이 안 좋을 수가 없겠네요.
Performance on Downstream Tasks
Generality를 확인하기 위한 Downstream task에서의 성능 지표입니다.

Task 별로 알차게 SoTA를 찍어주었네요. 특히나 Action Detection 부분에서 Optical Flow를 쓰지 않고도 SoTA를 찍은 것은 꽤나 고무적인 것 같습니다.
Conclusion
인공지능 모델이 점점 거대해지면서 이제는 scaling 연구들이 중요해지고 있는 것 같습니다. 이러한 상황에서 본 논문은 굉장히 간단하지만 효율적인 dual masking 기법을 제안하여 우수함을 입증한 연구였던 것 같습니다.
리뷰 읽어주셔서 감사합니다.



