Preliminaries
본 논문을 이해하기 위해서는 가우시안 혼합 모델(Mixture of Gaussian)이 무엇인지 이해해야 합니다.
Gaussian Mixture Model
우선 가우시안 혼합 모델이라 불리는 수학적 테크닉에 대해서 알아보도록 하겠습니다. 예를 들어 아래와 같은 데이터의 분포가 있다고 생각해 보겠습니다.

왼쪽 사진을 보면 전체 데이터의 분포를 하나의 가우시안 분포로 근사하여 설명하고 있습니다. 그래서 그런지 전체 데이터를 완전하게 설명하기에는 조금 부족해 보입니다. 가우시안 분포 중앙 부분에는 실제로 데이터가 별로 없기 때문입니다. 오른쪽 사진을 보면 전체 데이터의 분포를 두개의 가우시안 분포로 근사하여 설명하고 있습니다. 앞서서 하나의 분포로만 설명한 것에 비해 이번에는 데이터 분포를 그럭저럭 잘 설명할 수 있을 것 같습니다.
이렇듯 가우시안 분포 등의 기본적인 분포들의 선형 결합으로 만들어지는 확률 모델들을 혼합 분포(Mixture Distributuin), 혼합 모델(Mixture Model)이라 합니다. 가우시안 분포를 가지고 선형 결합을 하면 가우시안 혼합 모델이 되는 것이죠.
충분히 많은 숫자의 가우시안 분포를 사용하고 각 분포들의 평균과 공분산 선형 결합의 계수들을 조절하면 거의 모든 연속 밀도를 임의의 정확도로 근사하는 것이 가능하다는 것이 혼합 모델의 아이디어입니다.
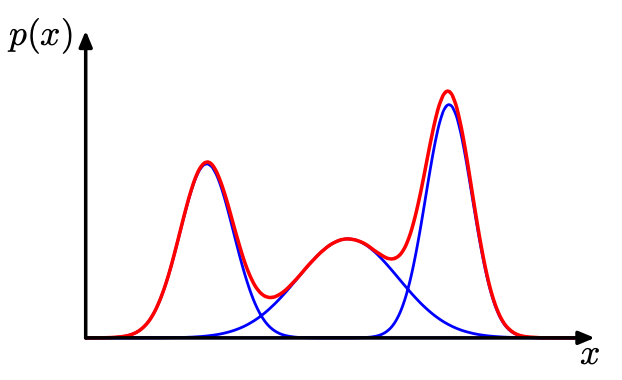
이런 식으로 말이죠. 결국 어떤 데이터의 분포이든 가우시안 분포를 통해 근사를 시킬 수 있다는 것입니다.
- $p(x)=\sum^{K}_{k=1} \pi_{k} N(x|\mu_{k} ,\sum\nolimits_{k} )$
위의 수식은 x라는 데이터에 대한 확률 밀도를 정의한 것입니다. K개의 가우시안 밀도의 중첩이라 볼 수 있죠.
여기서는 3가지의 파라미터를 추정해야 하는데 그것들은 아래와 같습니다.
- 혼합 계수 ($\pi_{k}$) : 임의의 k번째 가우시안 분포가 선택될 확률입니다.
- 평균 ($\mu_{k}$) : 임의의 k번째 가우시안 분포의 평균을 의미합니다.
- 공분산 ($\sum\nolimits_{k}$) : 임의의 k번째 가우시안 분포의 공분산을 의미합니다.
그래서 GMM(Gaussian Mixture Model)을 fitting 시킨다는 것은 주어진 데이터 분포 $X=[x_{1},x_{2},\ldots ,x_{n}]$에 대해서 최적의 파라미터 $\pi_{k}, \mu_{k}, \sum\nolimits_{k}$를 찾는 것과 동일합니다.
위의 매개변수를 찾는 방법은 최대 가능도 방법도 있지만 상황이 조금 복잡해진다고 합니다. 그래서 또 다른 강력한 알고리즘인 기댓값 최대화라는 알고리즘도 있는데 해당 알고리즘 까지는 본 리뷰에서 다루지 않도록 하겠습니다.
Introduction
논문의 첫 문장은 아래와 같이 시작합니다.
"Video is the vitality of the Internet, which means that understanding video content is essential for the most modern artificial intelligence (AI) agents."
비디오 데이터를 이해하는 것은 인공지능 분야에서 그만큼 중요하게 작용하고 있습니다. 더욱이 비지도학습(Unsupervised Learning)이나 자기 지도학습(Self-Supervised Learning)을 통해 비디오 데이터로 부터 시공간적 특징량(spatio-temporal representations)를 얻는 것은 컴퓨터 비전 연구에서 많은 주목을 받고 있습니다. 비디오 데이터는 특히 라벨링이 어렵기 때문에 이러한 비지도학습 기반의 접근이 중요하게 다뤄지고 있습니다.
이러한 연구 주제의 목표는 일반적인 시각 콘텐츠(visual contents)로부터 일반적인 특징을 얻는 것입니다. 이때 우리가 얻고 싶은 특징량은 단순한 특징량이 아니라 행동 분류(action recogniton), 행동 탐지(action detection), 비디오 검색(video retrieval)등에 도움이 되는 특징량입니다. 하지만 비지도학습(Unsupervised Learning)이나 자기 지도학습(Self-Supervised Learning) 기반의 video representation 연구는 정적인 이미지에 비해 아직 어려운 포인트가 많습니다.
자기지도학습(Self-Supervised Learning)기반의 video representation 연구는 크게 두 가지 흐름으로 분류됩니다.
우선, 비디오의 일관성과 관련된 pretext task를 사용하여 학습하는 방법이 있습니다. Temporal ordering, optical flow, spatiotemporal statistics 그리고 playback rate 등 다양한 pretext task들이 고안되어 비디오의 시공간적 특징을 학습하는 연구들이 많이 제안되었습니다. 하지만 이러한 방식의 한계점은 얻어지는 특징이 general 하지 않고 task-specific 하다는 것입니다.
다음으로 contrastive learning을 이용하는 것입니다. 이 방법의 장점은 데이터의 sub-properties에 상관없이 instance discrimination을 학습시킬 수 있다는 것입니다. 이전의 연구들은 각각의 비디오를 하나의 "instance"로 정의하고 비디오를 구성하는 clip들을 embedding space 내에 존재하는 하나의 결정적인 포인트(deterministic points)로 정의합니다. 이때 contrastive objectives를 통해 positive point들은 가까이 당겨지고 negative point들은 멀어진다는 점입니다. 이때 positve pair는 주로 같은 비디오로부터 나온 clip들 혹은 같은 clip이지만 augmented 된 clip을 사용하기도 합니다. 그리고 negative pair는 다른 비디오로부터 나온 clip으로 보통 사용합니다. 좀 더 학습을 고도화하기 위해 이전의 연구들은 pair를 좀 더 잘 구성하기 위한 augmentation을 연구하기도 했습니다.
하지만 위에서 설명한 deterministic representation은 세 가지 측면에서 한계점을 가지고 있습니다. 한계점을 논하기 전에 본 논문에서 제안하는 probablistic representation과의 차이를 그림을 통해 확인해 보도록 하겠습니다.

이전의 연구들 deterministic embedding 방식은 비디오 클립을 하나의 벡터로 projection 하여 embedding space 내에서 정확히 하나의 point로 mapping 시킵니다. 하지만 본 논문에서 제안하는 probabilistic embedding 방식은 비디오 클립을 가우시안 분포로 projection하여 embedding space 내에서 존재하는 확률 분포로 mapping 시킵니다. 그리고 클립들이 모여 구성되는 비디오를 가우시안 혼합 모델로 근사 시키는 것이죠.
그렇다면 어째서 deterministic embedding 방식이 적합하지 않을까요?
"First, representing the complicated and sophisticated video distribution as a set of deterministic points is insufficient to learn discriminative video representations."
우선 복잡하고 정교한 비디오를 deterministic point의 집합으로 표현하는 것은 충분하지 않다는 주장입니다. 이미지와는 다르게 비디오는 노이지 한 temporal dynamics와 redundant 한 정보를 많이 포함하기 때문에 데이터 자체의 uncertainty가 높은 편입니다. 따라서 deterministic 한 방법 말고 probablistic 한 방법이 더욱 적합할 수 있다는 주장입니다.
"Second, improper sampling and transformation techniques to generate different views can cause performance fluctuation according to downstream tasks"
부적합한 sampling 방식이나 transformation 방식은 오히려 비디오 콘텐츠를 손상시켜 downstream task에서의 성능을 하락시킬 수 있습니다. 일반적인 deterministic embedding을 위해 pair를 구성할 때 sampling 방식이나 transformation 방식이 많이 사용되기 때문입니다.
"Third, they often neglect common components that are likely to contain valid correspondences between semantically adjacent instances (e.g. same category, but different videos), leading to limited discrimination performance of learned representations."
서로 다른 비디오 간의 semantic-relation은 고려되지 않았다는 것 역시 한계로 작용합니다. 결국 저자는 앞서 설명한 한계점을 극복하기 위해 비디오 클립 자체를 확률 변수로 사용하는 stochastic embedding space를 제안합니다. 결국 비디오는 여러 개의 가우시안 분포의 혼합 모델로써 혼합 분포를 가지게 되고 이러한 서로 다른 비디오 즉, 서로 다른 혼합 분포들끼리의 확률 거리(probabilistic distance)를 통해 positive, negative pair를 구성합니다.
더욱이 비디오 데이터는 근본적으로 uncertainty가 높은 데이터인 만큼 이것을 다루기 위해 저자는 uncertainty-based stochastic contrastive loss를 제안합니다. 결국 uncertainty를 이용함으로써 학습 샘플의 노이즈를 줄이고 학습 과정에서 부적절한 pair를 줄이는 것을 기대한다고 보시면 됩니다.
그렇다면 이제 제안된 method가 어떻게 구성되어 있는지 확인해 보도록 하겠습니다.
Method
Probabilistic Video Embedding
자 그러면 Probabilistic Video Embedding이 어떻게 이루어지는지 확인해 보도록 하겠습니다.
우선 단일 비디오 기준으로 비디오는 여러 클립들의 집합으로 구성되어 있습니다. 그리고 보통은 3D Encoder를 통해 클립을 vector로 임베딩 시키게 됩니다.
- $V=\left\{ c_{1},\ldots ,c_{N}\right\} $
- $v_{c_{n}}=f\left( c_{n};\theta \right) $
그리고 이 clip-level의 feature를 가지고 가우시안 분포를 생성해야 합니다.
가우시안 분포를 결정할 때 필요한 것은 무엇인가요? 일변량 가우시안 분포라면 평균, 분산이 되며 다변량 가우시안 분포라면 평균 벡터, 공분산 행렬이 필요합니다. 여기서는 다변량을 사용하기 때문에 평균 벡터, 공분산 행렬을 추정해야 합니다. 평균 벡터, 공분산 행렬을 추정할 수 있다면 아래와 같이 확률 분포를 결정할 수 있습니다.

데이터를 가지고 가우시안 분포를 결정할 때는 보통 최대우도법(MLE)을 사용하지만 여기서는 신경망을 이용하여 평균 벡터와 공분산 행렬을 구할 수 있는 함수를 모델링하였습니다.
- $\mu =g_{\mu }\left(v_{c_{n}}\right)=\text{L}_{2}\text{Norm}(\text{LayerNorm}(\text{FC}\left(v_{c_{n}}\right)))\in \mathbb{R}^{D}$
- $\sum=\text{diag}\left(g_{\sigma}\left(v_{c_{n}}\right)\right)=\text{diag}\left(\text{FC}\left(v_{c_{n}}\right)\right)\in \mathbb{R} ^{D}$
여기서 평균 벡터와 공분산 행렬을 추정할 때 사용되는 FC layer는 parameter를 공유하지 않습니다.
그리고 난 다음에 $N$개의 클립에 대해서 위와 같은 과정을 반복하면 일단 $N$개의 가우시안 분포를 추정할 수 있습니다. 이제 우리는 단일 비디오에 대해서 비디오에 대한 혼합 분포를 가우시안 혼합모델로 결정합니다.
- $p\left(z\mid V\right)=\sum^{N}_{n=1} \mathcal{N}\left(z;g_{\mu}\left(v_{c_{n}}\right),\text{diag}\left(g_{\sigma}\left(v_{c_{n}}\right)\right)\right) $
비디오에 대해서 혼합 분포를 추정하고 난 다음에는 K개의 새로운 embedding feature를 생성합니다. 이때 새로운 embedding feature를 생성하는 방법은 아래와 같습니다.
- $z^{(k)}=\sigma(V)\odot \epsilon^{(k)}+\mu(V)$
여기서 $\epsilon^{(k)}$은 가우시안 분포로 독립 항등 방식으로 샘플링된 random vector입니다. 그리고 $\sigma(V)\, \mu(V)$는 각각 $p\left(z\mid V\right)$의 평균과 분산입니다. 결국 하나의 비디오를 설명할 수 있는 혼합 분포가 있고 이 혼합 분포의 평균과 공분산이 존재할 때 평균과 분산을 조금씩 바꾸어가며 K개의 새로운 embedding feature를 생성한다는 의미입니다.
이때 $\sigma(V), \mu(V)$를 어떻게 구하는지 궁금해서 supplementary를 찾아보니 계산과정이 나와있더군요. 한번 정리해 보도록 하겠습니다.
우선 $N$의 클립 중 특정한 $n$번째 클립이 있을 때 우리는 clip feature를 가우시안 분포로 근사 했기 때문에 확률 밀도 함수를 정의할 수 있습니다.
$f_{c_{n}}(z)$를 $n$번째 클립의 확률 밀도 함수(probability density function, PDF)라 정의하겠습니다. 이때 확률 밀도 함수를 결정짓는 파라미터는 $\mu_{n}\in \mathbb{R}^{D} , \sigma_{n}^{2}\in \mathbb{R}^{D}$ 각 평균과 공분산이 됩니다.
이때 혼합 모델의 확률 밀도 함수는 N개의 확률 밀도 함수의 평균으로 계산할 수 있습니다.
- $f_{V}(z)=\frac{1}{N}\sum_{n=1}^{N}f_{c_{n}}(z)$
그리고 가우시안 혼합 모델의 평균인 $\mu(V)$는 평균 공식을 이용해서 구할 수 있습니다.
- $\mu(V) =\int zf_{V}\left( z\right) dz$
- $\mu(V) =\frac{1}{N} \sum_{n} \int zf_{c_{n}}\left( z\right) dz$
- $\mu(V) =\frac{1}{N} \sum_{n} \mu_{n} $
평균을 구하는 연산 자체가 선형적인 연산이다 보니 결국 평균들의 평균으로 혼합 분포의 평균이 결정되는 모습입니다.
다음으로 분산입니다. 분산은 제곱의 평균 - 평균의 제곱이라는 공식을 통해서 계산할 수 있었습니다.
- $\sigma^{2}_{V} =\int z^{2}f_{V}(z)dz-\mu^{2}_{V} $
- $\sigma^{2}_{V} =\frac{1}{N} \sum_{n} \int z^{2}f_{c_{n}}(z)dz-\mu^{2}_{V} $
- $\sigma^{2}_{V} =\frac{1}{N} \sum_{n} \left( \sigma^{2}_{n} +\mu^{2}_{n} \right) -\mu^{2}_{V} $
여기서 이해가 가지 않았던 부분은 $\int z^{2}f_{c_{n}}(z)dz=\left( \sigma^{2}_{n} +\mu^{2}_{n} \right) $ 이 부분인데 아무리 찾아봐도 관련 내용이 나오질 않아 일단 넘어갔습니다.
- $\sigma^{2}_{V} =\frac{1}{N} \sum_{n} \left( \sigma^{2}_{n} +\mu^{2}_{n} \right) -(\frac{1}{N} \sum_{n} \mu_{n} )^{2}$
이렇게 해서 $\sigma(V), \mu(V)$를 찾을 수 있었습니다.

위의 과정을 정리하면 그림과 같습니다. 아직 probability distance를 계산하는 과정과 stochastic contrastive loss를 계산하는 과정을 설명하지 않았지만 비디오를 가우시안 혼합 모델로 근사하고 다시 K개의 stochastic embedding feature를 얻는 과정을 살펴봤습니다.
Mining Positive and Negative Pairs
Deterministic representation 과는 다르게 probabilistic representation을 위해서는 euclidean distance가 아니라 probability distance를 가지고 embedded distribution과의 유사도를 계산합니다. 여기서 사용하는 지표가 Bhattacharyya distance를 사용한다고 합니다. 두 연속확률 분포의 유사도를 비교할 때 평균과 분산을 동시에 고려한 지표라고 생각하면 됩니다. 아래와 같이 정의됩니다.
- $dist\left( z^{(k)}_{i},z^{(k^{\prime })}_{j}\right) =\frac{1}{4} (\log \left( \frac{1}{4} \left( \frac{\sigma^{2}_{i} }{\sigma^{2}_{j} } +\frac{\sigma^{2}_{j} }{\sigma^{2}_{i} }+2\right)\right))+\lambda \cdot \frac{\left( z^{(k)}_{i}-z^{(k^{\prime })}_{j}\right)^{T} \left( z^{(k)}_{i}-z^{(k^{\prime })}_{j}\right) }{\sigma^{2}_{i} +\sigma^{2}_{j} } $
참 복잡하게 생겼습니다. 이 복잡하게 정의되는 거리 지표를 사용하는 이유는 아래와 같습니다.

여기서 분포를 보면 $X_{1}$, $X_{2}$ 그리고 $X_{3}$이 있습니다. $X_{1}$과 $X_{2}$ 간의 유사도와 $X_{2}$과 $X_{3}$ 간의 유사도는 뭐가 더 높을까요? 모양이 비슷하게 생겼다고 해서 유사도가 높은 것이 아니라 겹치는 영역이 더 많아야 유사하다고 볼 수 있습니다.
$X_{2}$는 $X_{1}$과 겹치는 구간이 더 많기 때문에 $X_{3}$에 비해 $X_{1}$과 더 유사하다고 볼 수 있습니다. 그런데 보통 많이 사용하는 평균 간의 Euclidean distance는 이러한 유사도 관계를 보장해주지 못합니다.
따라서 저자는 Bhattacharyya distance를 통해 평균과 분산을 동시에 고려하여 두 확률 분포 간의 유사도를 정의합니다.
위에서 설명한 거리는 클립으로부터 정의되는 가우시안 분포 간의 유사도를 측정하는 방법이며 이제는 비디오 간의 유사도를 측정하는 방법을 정의하겠습니다. 위에서 비디오를 가우시안 혼합 모델로 정의하고 이를 다시 reparameterization을 통해 K개의 stochastic embedding feature를 계산한다고 했습니다.
그리고 두 비디오로부터 K개의 stochastic embedding feature를 일대일 대응 방식으로 거리를 비교하고 평균 내는 방식으로 비디오 간 유사도를 측정하고 있습니다.
- $\text{dist}(\mathcal{V}_{i},\mathcal{V}_{j})\approx \frac{1}{K^{2}} \sum^{K}_{k} \sum^{K}_{k^{\prime }} \text{dist}\left( z^{(k)}_{i},z^{(k^{\prime })}_{j}\right)$
비디오 간 이제 positive, negative 관계는 임계치 처리를 통해 얻어집니다.
- $\mathcal{P}=\{ \left( \mathcal{V}_{i},\mathcal{V}_{j}\right) \mid \text{dist}(\mathcal{V}_{i},\mathcal{V}_{j})<\tau \} $
비디오 간 유사도를 통해 threshold $\tau$ 보다 작은 비디오들을 positive로 정의합니다. 당연히 negative는 그 반대겠네요. 이제 이 pair를 통해서 stochastic contrastive loss를 통해 학습을 진행합니다.
Stochastic Contrastive Loss
제안하는 방식으로 distance를 구하고 비디오간 유사도를 통해서 비디오끼리 positive, negative를 구성했습니다. 이때 우리는 deterministic 하게 embedding 한 것이 아니라 stochastic 하게 embedding을 했기 때문에 우리가 평소에 사용하던 InfoNCE Loss는 사용할 수 없습니다.
하지만 목적 자체는 비슷하겠죠. 서로 positive pair 관계에 있는 비디오 들은 그 비디오를 구성하는 가우시안 분포들끼리 서로 유사해지게 만드는 것입니다.
하지만 위에서 만든 pair는 분명히 noise 합니다. Positive pair라고 계산 됐지만 실제로는 negative의 관계일 수 있고, 그 반대도 역시 발생할 수 있습니다.
따라서 이러한 uncertainty에 대해서 penalty를 주기 위한 장치도 필요합니다. 즉, 제안되는 Loss 함수는 일단
- probabilistic distance 기반으로 정의되는 pair를 바탕으로 contrastive learning을 수행할 수 있어야 합니다.
- 동시에 uncertainty가 높은 두 비디오의 상황에서는 앞선 (1)의 영향력을 줄여야 합니다.
무슨 말인지 조금 애매할 수 있으니 이제 수식적으로 접근해 보도록 하겠습니다.
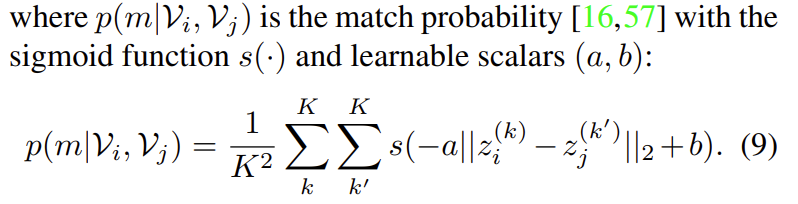
일단 서로 다른 두 비디오 간의 match probability부터 계산하는 방식에 대해서 살펴보도록 하겠습니다.
앞서 $z^{(k)}$는 $z^{(k)}=\sigma(V)\odot \epsilon^{(k)}+\mu(V)$ 이렇게 정의된다고 했었습니다. GMM을 통해서 얻은 video representation의 self-augmented embedding입니다. 비디오마다 $K$개의 embedding을 sampling 했기 때문에 수식을 보면 $O(K^{2})$의 복잡도를 가지고 있습니다.
결국 $s(-a\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}+b)$을 $K^{2}$번 더하고 평균 내주고 있습니다.
- $s$는 sigmoid 함수입니다. 어떤 값이 입력으로 들어오든 일단 0~1 사이로 변환하여 줍니다.
- $a$와 $b$는 학습 가능한 parameter입니다. 자세한 이유는 나와있지 않지만, 아마도 sigmoid 함수를 사용할 때 너무 saturation 되는 것을 방지하기 위해 사용하는 것 같습니다.
- $\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}$은 sampling 된 embedding 끼리의 Euclidean distance입니다.
우리가 원하는 상황을 가정해 보겠습니다. Positive/Negative pair가 잘 구성되었고 GMM을 통해 Video distribution이 잘 생성되었기를 바라고 있겠죠.
이는 서로 Positive 관계에 있는 두 비디오로부터 나온 augmented embedding들은 유사한 표현력을 가져야 함을 의미합니다. 또한 Negative 관계에 있는 두 비디오로부터 나온 augmented embedding들은 유사하지 않은 표현력을 가져야 함을 의미합니다.
따라서 Loss 함수는 아래와 같이 설계되어야 합니다.
Positive Pair
- Positive 관계에 있는 비디오는 $\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}$는 작아지는(0으로) 방향으로 학습되어야 합니다.
- 이는 $-a\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}+b$가 $b$에 가까워지는 방향입니다.
- $b$가 적당히 큰 값으로 수렴되면 sigmoid 함수 개형에 따라 $s(-a\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}+b)$는 1에 수렴하게 됩니다.
Negative Pair
- Negative 관계에 있는 비디오는 $\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}$는 커지는(무한대로) 방향으로 학습되어야 합니다.
- 이는 $-a\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}+b$가 음의 무한대에 가까워지는 방향입니다.
- $-a\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}+b$가 음의 무한대에 가까워지면 sigmoid 함수 개형에 따라 $s(-a\left|z_{i}^{(k)}-z_{j}^{(k)} \right|_{2}+b)$는 0에 수렴하게 됩니다.
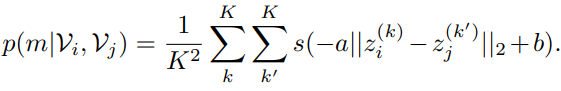
결국 위에서 정의되는 matching probability $p(m|\mathcal{V}_{i},\mathcal{V}_{j})$는 Positive Pair에 대해서는 1로 수렴하고 Negative Pair에 대해서는 0으로 수렴합니다.
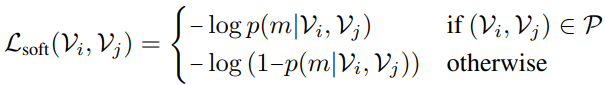
그리고 위의 soft contrastive loss를 보면
- Positive Pair에 대해서는 $-\log(p(m|\mathcal{V}_{i},\mathcal{V}_{j}))$가 작아져야 하니, $p(m|\mathcal{V}_{i},\mathcal{V}_{j})$가 1로 수렴하는 방향을 가지고 있습니다.
- Negative Pair에 대해서는 $-\log(1-p(m|\mathcal{V}_{i},\mathcal{V}_{j}))$가 작아져야 하니, $p(m|\mathcal{V}_{i},\mathcal{V}_{j})$가 0으로 수렴하는 방향을 가지고 있습니다.
정확히 우리가 원하는 방향과 일치합니다. 하지만 여기서 고려해야 할 것이 하나 있습니다. Probability Distance로 정의한 Positive/Negative Pair가 불안정할 수 있다는 것입니다. GMM을 구성하는 각 가우시안 분포의 통계치를 학습하는 구조이기 때문에 당연히 노이즈가 생길 수 있습니다.
이를 방지하기 위한 regularization 아이디어는 아래와 같습니다.
"Positive Pair라 할지라도 두 비디오 분포의 편차가 크다면, soft contrastive loss의 영향력을 줄이고 두 비디오의 편차를 줄이는 방향으로 학습하자."
무슨 말인지 애매하니 다시 수식으로 보도록 하겠습니다.

$L_{soft}$에 두 비디오 분포의 편차가 곱이 역수로 곱해져 있습니다. 두 비디오 분포의 편차가 크면 분모가 커지고 Loss의 크기가 작아져 학습에 영향력이 줄어들겠죠.
두 비디오 분포의 편차가 큰 상황에서는 $\frac{1}{2}(\log(\sigma_{i}^{2})+\log(\sigma_{j}^{2})))$가 큰 값을 가지게 되고 이를 작아지게 하는 방향으로 학습이 되니, 편차를 줄이는 방향으로 학습됩니다.
이렇게 정의되는 stochastic contrastive loss는 결국 positive pair라 할지라도 편차가 큰, uncertainty가 큰 상황을 control 하기 위한 regularization term까지 고려하여 정의가 됩니다.
Total Objectives
추가적인 KL regularization term까지 정리하고 total loss 함수를 정리하도록 하겠습니다. 비디오 분포를 학습하는 과정에서 covariance matrix가 0으로 붕괴되는 것을 방지하기 위한 regularization term을 추가했다고 합니다.
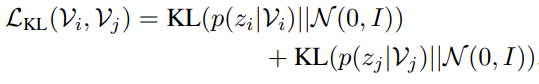
위의 regularization term을 통해 비디오의 분포가 평균이 0이고 공분산 행렬이 단위행렬인 정규분포와 비슷해질 수 있습니다. 아마 이 regularization은 강하게 할 것 같지는 않습니다. Implementation detail을 찾아보니 $\beta$는 $10^{-4}$을 사용한다고 하네요.
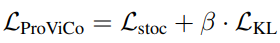
최종 Loss는 위와 같습니다.
Experiments
Action Recognition
Linear evaluation on Kinetics-400
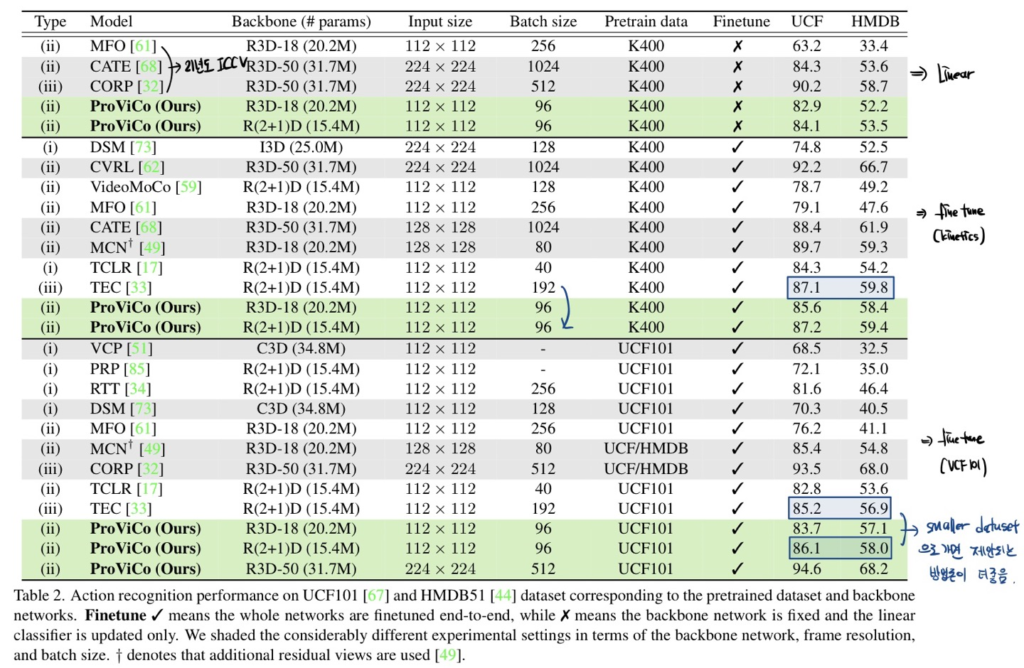
Kinetics-400에서의 Action recognition linear evaluation입니다. Linear evaluation은 사전학습된 백본은 고정시키고 마지막에 linear layer만 다시 학습시키는 것입니다. 아래 테이블에서 회색으로 칠해진 방법론들은 백본의 크기가 다르기 때문에 직접적인 비교는 어렵고 하얀색으로 칠해진 방법론들과 비교하면 됩니다.
대표적으로 21년도 CVPR에 나온 방법론인 $\rho MoCo$와 비교했을 때 동일한 백본 대비 Linear evaluation 성능을 8.5%나 향상했습니다.

Linear evaluation on UCF101 and HMDB51

위에 보이는 MFO, CATE, CORP는 모두 21년도 ICCV에 발표된 연구들입니다. 본 논문에서 제안하는 ProViCo는 더 적은 배치 사이즈와 입력 사이즈를 가져가면서도 우수한 성능을 보여주고 있습니다.
Finetuning on UCF101 and HMDB51
일단 테이블의 두 번째 단락을 보면 Kinetics-400으로 finetuning 시켰을 때의 성능입니다. 회색 라인은 사실 fair comparison이 아니기 때문에 큰 의미는 없고 두 번째 단락에서 TEC라는 방법론과 비교하면 동일 백본 대비 더 적은 배치사이즈를 가져갔을 때 비슷한 성능을 보여주고 있습니다.
다음으로 테이블의 세 번째 단락을 보면 UCF101, HMDB51과 같은 더 작은 데이터 셋으로 finetuning 시켰을 때의 성능입니다. 동일하게 TEC라는 방법론과 비교하면 더 적은 데이터 셋에서는 제안되는 방법론이 더 우수함을 보여주고 있습니다.
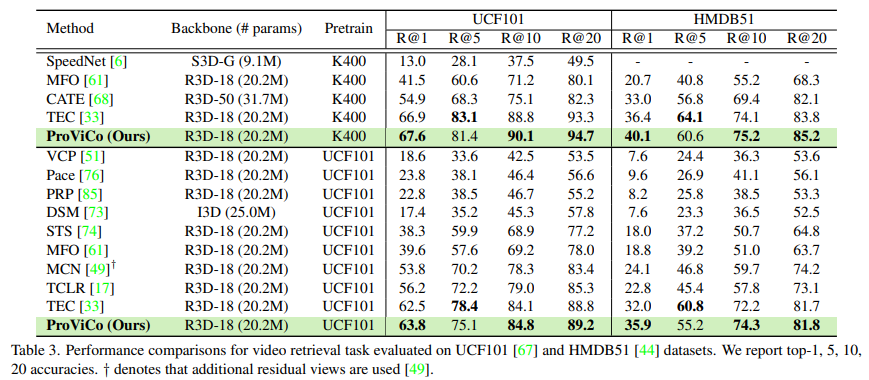
Video Retrieval
Video Retrieval에서도 벤치마킹을 진행했습니다. 제안되는 probablistic approach가 matching task에서도 좋은 표현을 학습시킨다고 주장하고 있네요. 다만 의아한 게 Recall@5에서만 성능이 조금 떨어지네요..?
Ablation Study and Analysis
Ablation을 다룰 예정인데 단순 hyper-parameter에 대한 실험은 크게 의미가 없는 것 같아 리뷰에는 제외했습니다.
저자는 학습 과정에서 uncertainty와 discriminability of representation 간의 관계를 분석하였습니다. 실험은 Video Retrieval에 대해서 진행했다고 합니다.
학습 과정 중 10 epoch 마다 모든 비디오의 uncertainty를 평균 내고 Recall@1을 평균 냈습니다. 아래 그림 중 왼쪽의 그래프를 보면 accuracy는 올라가면서 uncertainty는 낮아지고 있습니다. 근데 사실 이건 당연한 결과일 수밖에 없는 것이 loss term 중 uncertainty에 대한 regularization을 넣었기 때문에 uncertainty는 무조건 낮아지는 것이 아닌가 생각이 드네요.
오른쪽 그래프는 uncertainty level을 일부러 강하게 했을 때 Recall이 떨어지고 있습니다.
이를 토대로 performance와 uncertainty 간의 negative correlation이 있다고 주장합니다.
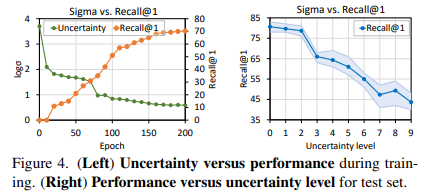
Main Paper에서 다루는 ablation은 이게 끝인데 개인적으로는 Loss 함수에 있는 uncertainty에 대한 regularization term에 대해서 ablation이 무조건 있었어야 하지 않나 싶습니다. 뭔가 좀 찜찜한 기분이 드네요.
Conclusion
개인적으로 비디오 클립을 하나의 feature vector로 임베딩 시키는 것이 아니라 probability distribution으로 매핑시킨 아이디어 참신했던 논문이었습니다. 저자가 밝히는 본 논문의 한계는 바로 Untrimmed Video의 상황입니다.
Untrimmed Video의 상황에서는 더욱 uncertainty가 커지고 background의 영향을 받기 때문에 Untrimmed video의 상황에서도 확률적인 접근을 통해 positive/negative pair를 잘 구성하는 것이 future work라 밝히고 있습니다.
리뷰 마무리하도록 하겠습니다. 감사합니다.



