Before Review
이번 논문은 self-supervised 기반의 video representation learning 논문을 읽게 되었습니다.
지난 리뷰랑 비슷한 점이 많습니다. 지난 리뷰 background erasing은 background를 추가하여 오히려 motion pattern에 집중할 수 있는 contrastive learning framework를 제안하였습니다.
본 논문도 비슷한 흐름으로 진행됩니다. 그럼 리뷰 시작하도록 하겠습니다.
Preliminaries
Bayesian theorem
- $P(H\mid E)=\frac{P(E\mid H)P(H)}{P(E)} $
베이즈 정리는 사전 확률과 사후 확률의 관계를 나타내는 정리입니다. 자세하게 정리된 포스팅 글이 있어 링크 달아두겠습니다.
- $P(H)$ : 사전 확률(prior probability)은 어떠한 사건이 발생했다는 주장 혹은 가설에 대한 확률을 의미합니다. 예를 들면 코로나에 걸렸을 확률이 되겠네요. 현재의 정보를 기초로 하는 초기 확률이라 생각하면 됩니다.
- $P(H\mid E)$ : 사후 확률(posterior probability)은 새로운 정보나 근거를 토대로 갱신된 확률을 의미합니다. 예를 들면 질병이 양성이라고 판단받았을 때 코로나 바이러스에 걸렸을 확률이라고 생각하면 될 것 같습니다.
그래서 베이즈 정리는 사전 확률 $P(H)$가 원래 있었을 때 우리가 어떤 사건$(E)$을 관찰한 뒤에 나의 주장에 대해서 관측된 사건을 토대로 갱신된 신뢰도를 계산하는 방법입니다.
베이즈 정리를 제대로 이해하기 위해서는 베이지안 주의의 철학에 대해서 간단하게 알아볼 필요가 있습니다. 베이지안 주의의 반대되는 관점은 빈도 주의(frequency)라고 우리에게 익숙한 연역적 사고에 기반한 주의입니다. 동전의 앞면이 나올 확률이 50%라는 것을 빈도 주의에서는 100번의 동전을 던졌을 때 50번은 앞면이 나온다는 얘기이죠.
하지만 베이즈 정리에서는 확률을 주장에 대한 신뢰도로 해석합니다. 동전의 앞면이 나올 확률이 50%라는 것은 동전의 앞면이 나왔다는 주장의 신뢰도가 50%라는 것입니다. 베이지안 관점의 통계학에서는 경험에 기반한 귀납적 사고가 기본 철학이 되며 확률을 경험에 기반한 선험적인 혹은 불확실성을 내포하는 수치를 기반으로 정의하고 거기에 추가 정보를 바탕으로 확률을 갱신하는 구조를 취합니다.
초기의 사전 확률로부터 추가적인 정보를 통해 사후 확률로 확률을 갱신하고 조금 더 진리에 다가갈 수 있다는 철학이 베이즈 정리에 녹아있다고 보면 되겠습니다.
Contrastive Learning
Contrastive Learning에 대해서도 간단하게 정리하도록 하겠습니다.
Contrastive Learning은 기본적으로 label이 없는 상황에서 자주 사용합니다. Self-Supervised 기법 중 가장 활발하게 연구가 되고 있는 학습 방법이기도 합니다. 핵심은 모든 데이터를 하나의 instance로 여긴다는 점입니다. 이미지 데이터를 예시로 든다면 1000장의 학습 데이터가 있다면 1000개의 서로 다른 Instance가 존재한다고 보는 것이죠.
같은 강아지 사진이라도 다른 학습 데이터라면 다른 개체로 가정하는 것입니다. 그리고 여기서 무엇을 하냐면 데이터를 가지고 장난을 칩니다. 데이터를 회전하거나 자르거나 노이즈를 가하는 등 원래 이미지에서 조금의 변형을 준 새로운 데이터를 생성합니다.

위의 강아지 사진에서 crop이 가해져서 변형된 사진이 얻어지는 것을 사진을 통해 확인할 수 있습니다. 이렇게 하나의 데이터부터 변형이 이뤄진 데이터에 대해서는 positive sample이라 정의합니다. 원래 데이터가 가지고 있는 content 정보는 유지가 되었기 때문입니다.
그래서 라벨이 없는 상황에서의 최선은 positive sample 끼리는 적어도 콘텐츠 정보가 같다는 사실을 모델에게 알려주는 것입니다. negative sample은 그냥 다른 데이터를 전부 negative로 정의합니다. 그런데 positive sample 끼리는 콘텐츠 정보가 같다는 사실을 모델은 어떻게 이해할 수 있을 까요?
바로 둘의 feature representation이 비슷해지게 만들어주는 것입니다.
Positive sample 끼리 feature representation이 비슷해지고, negative sample 끼리 feature representation이 멀어지는 Loss 함수만 설계할 수 있다면, 모델은 결국 라벨이 없는 상황에서도 데이터를 나름 이해할 수 있는 학습을 할 수 있게 되는 것입니다. 이것이 바로 contrative Learning이라고 볼 수 있습니다.
Positive sample 끼리 feature representation이 비슷해지고, negative sample 끼리 feature representation이 멀어지는 loss 함수는 무엇일까요? 다양한 contrastive Loss가 존재하지만 가장 많이 사용하는 InfoNCE Loss에 대해서 간략하게 설명하도록 하겠습니다.
Loss 함수의 formulation은 아래와 같습니다.
- $L=-\frac{1}{N} \sum^{N}_{i=1} log\left( \frac{exp(f(x)\cdot f(x^{+}))}{exp(f(x)\cdot f(x^{+})+\sum^{N-1}_{j=1} exp(f(x)\cdot f(x^{-}))} \right) $
Loss가 작아지는 방향은 결국 $log$ 안의 값이 1에 수렴하도록 학습이 되어야 합니다. 1에 수렴하는 방향은 두 가지의 방향성을 띠고 있습니다.
- $exp(f(x)\cdot f(x^{+})$ 가 무작정 커지는 방향 : 이 방향이라면 분모 분자에서 $exp(f(x)\cdot f(x^{+})$의 영향력이 가장 크기 때문에 분수 값 자체는 1에 수렴합니다. 이는 positive pair끼리 feature similarity가 커지는 방향이죠.
- $\sum^{N-1}_{j=1} exp(f(x)\cdot f(x^{-}))$가 무작정 작아지는 방향 : 이 방향이라면 분모 분자에서 $\sum^{N-1}_{j=1} exp(f(x)\cdot f(x^{-}))$이 0에 수렴하기 때문에 분수 전체 값은 1에 수렴합니다. 이는 negative pair 끼리 feature similarity가 작아지는 방향이죠.
이렇게 InfoNCE Loss를 통해 contrastive learning을 진행할 수 있습니다. 무튼 contrastive learning에 대한 간단한 설명은 여기서 마치고 본격적인 리뷰를 시작하도록 하겠습니다.
Introduction
Image분야에서 self-supervised learning이 활발하게 연구가 되고 있습니다. Video 분야에서도 이에 발맞추어 여러 연구자들이 열심히 연구하고 있는 상황이죠. Self-supervised learning 연구가 활발하게 되고 있는 이유는 역시 generalization 관점이 큰 것 같습니다. 다양한 down-stream task에서 잘 동작하기 위해서는 사전 학습이 중요하게 작용합니다. 하지만 사전 학습을 supervised 기반으로 진행해 버리면 다양한 down-stream task에 적용하기에 까다로워집니다. 이유는 task가 바뀔 때마다 annotation이 필요하기 때문이겠죠.
즉, annotation 없이 일단 사전 학습 자체는 self-supervised 기반으로 진행해야 다양한 task에 접목이 가능하다는 이야기입니다.
이러한 상황에서 video 분야에서 self-supervised representation learning은 다양한 목적을 가진채 연구가 되고 있습니다. 하지만 그중 action domain을 위한 사전 학습을 고려하면, 요즘 연구의 흐름은 background bias를 없애는 것을 목표로 하고 있습니다.
Action을 이해할 때는 visual information 보다는 motion pattern이 더 중요하게 작용합니다. 지난 리뷰에서도 이러한 문제를 지적한 논문이 있었죠. 러닝 머신 위에서 춤을 추고 있으면 우리의 모델이 그냥 달린다고 예측해버린다는 문제점이 바로 이러한 background bias입니다. 체육관과 러닝머신이라는 background visual information만 보고 예측을 해버리는 것이죠.
그렇다면 이러한 문제가 발생하는 이유는 무엇일까요?
- Background가 일반적으로 영상의 대부분을 차지합니다. 그렇기 때문의 모델은 당연히 background에 focus 할 수밖에 없습니다.
- 애초에 비디오에서 motion이 극적으로 변하는 부분이 많지 않습니다.

사진을 보면 초록색 영역이 background이고 빨간색 영역이 motion(foreground)입니다. 이 두 클립을 positive pair로 구성하면 모델은 당연히 background에 치중이 되겠네요.
이러한 상황에서 저자는 직관적이면서 간단한 아이디어를 제안합니다. 영상에서 motion인 부분의 영역을 추출하고 여기에 다양한 background를 적용시켜 positive pair를 생성합니다. 즉, background는 달라도 motion이 똑같은 video pair를 만드는 것입니다. 그리고 contrastive loss를 통해 두 비디오의 feature representation이 비슷해지게 만드는 것이 핵심입니다.
결국 action을 이해하는 데는 background visual pattern 보다는 motion pattern이 더 중요하니 여기에 집중하겠다는 소리입니다.
그런데 여기서 한 가지 의문이 들 수 있습니다. 별다른 label이 있는 것도 아닌데 비디오에서 motion이 이뤄지고 있는 부분을 어떻게 추출한다는 것인지 궁금할 수 있겠네요. 이것이 본 논문의 핵심입니다. 그리고 저자는 굉장히 간단한 방법으로 이를 수행하고 정략적인 성능 평가를 통해 본 방법론의 우수함을 증명합니다.
그렇다면 이제 저자가 제안한 방법론에 대해서 살펴보도록 하겠습니다.
Related work
원래 related work 까지는 다루지 않는데 제가 이전에 리뷰 했던 방법론과 직접적으로 비교하는 문장이 있어 간단하게 정리하고 가겠습니다.
[CVPR 2021] Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning라고 해서 background erasing이라는 컨셉으로 똑같이 video representation learning을 다룬 연구가 있습니다. 여기서는 비디오의 다른 영역에서의 영상을 현재의 영상으로 합쳐 motion pattern은 비슷하지만 background 정보는 다른 pair를 만들어 동일하게 contrastive learning을 했던 방법론이 있습니다.
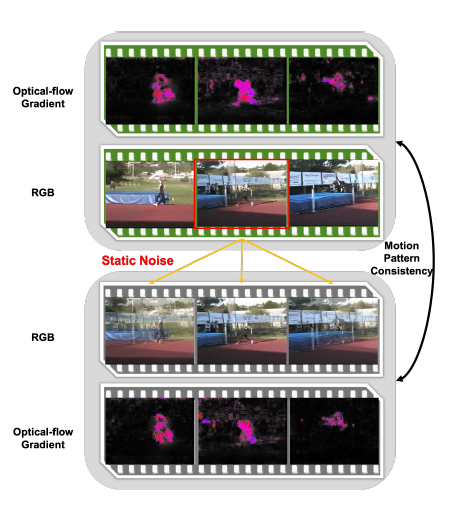
즉, static noise를 넣어도 optical flow gradient가 비슷한 것을 통해 noise를 가하면 motion pattern은 유지가 되지만, background는 확실히 변형이 되니 이렇게 positive pair를 만들어 모델이 motion pattern에 집중하게 만들었다고 보면 됩니다.
하지만 저자는 이 방법론의 단점으로 motion pattern이 항상 유지가 될 수 없음을 지적합니다. 저 예시 같은 경우는 굉장히 이상적인 케이스라 볼 수 있겠죠. 노이즈가 들어갔을 때 항상 motion pattern이 유지가 될 수 없고 오히려 motion pattern을 없애는 경우도 생기기 때문에 한계점이 있다고 주장합니다.
자 방금 설명한 background erasing(BE) 방법은 실험 부분에서도 계속 비교가 되기 때문에 간단하게 짚어봤습니다.
Proposed approach
Background Bias in Contrastive Learning
우선 이전까지의 방법론의 한계에 대해서 먼저 분석을 합니다. 계속 설명했지만 visual augmentation 만을 적용해서 contrastive learning을 적용하는 것은 background cue에 있는 다른 instance를 구별하는 식으로 학습이 되기 때문에 background bias가 심해진다고 앞에서 계속 설명했습니다. 우선 정말로 그게 사실인지 확인해 보도록 하겠습니다.
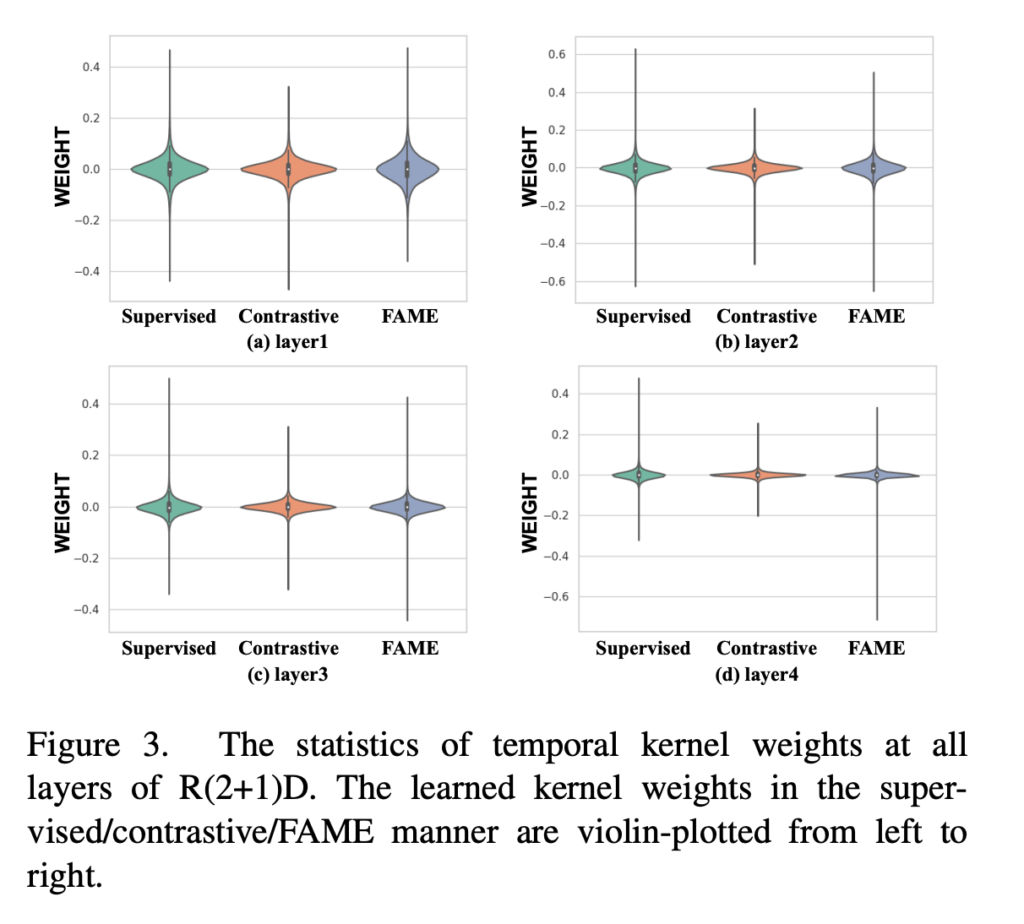
1D convolution layer의 weight를 plot 한 그림입니다. 이 분석에 사용된 Backbone network는 R(2+1)D network로 2D 방식으로 spatial 축에서 convolution 연산을 진행하고 temporal 축에서 1D convolution을 수행하는 방식입니다.
즉, 1D convolution layer의 weight를 살펴보는 것은 모델이 temporal 축에 대해서 어떻게 반응하는지 살펴보겠다는 의도입니다.
우선 supervised 방식과 일반적인 contrastive 방식을 비교해보도록 하겠습니다. 그냥 weight의 분산이 크냐 작냐로 비교하면 됩니다. supervised 방식은 분산이 크기 때문에 더욱 flexible 한 temporal modeling을 수행할 수 있는 반면 contrastive 방식은 분산이 작아 supervised 방식에 비해 temporal 변화에 강인하지 못합니다.

다음으로는 CAM을 통한 분석입니다.
위의 그림이 일반적인 contrastive learning을 수행했을 때 모델이 집중하는 부분을 시각화한 것이라 보면 됩니다. 확실히 motion이 이뤄지고 있는 부분 말고도 다른 시각적인 부분에 activation이 활성화되는 것을 볼 수 있습니다.
아래의 그림은 저자가 제안한 방식으로 했을 때의 CAM 결과입니다. 확실히 동일한 사진에 대해서 background bias가 줄어들고 정말 motion pattern에 집중하는 모습을 보여줍니다.
확실히 저자의 주장대로 visual augmentation 만을 적용해서 contrastive learning을 적용하는 것은 background-bias가 심해지는 것을 확인할 수 있습니다. 다시 한번 정리해서 저자는 motion pattern을 고정시키고 background에 변화를 주어야 모델이 motion에 집중할 수 있다고 주장했습니다. 그렇다면 motion pattern을 정밀하게 추출할 수 있는 방법이 필요한데 이제 진짜 그 방법이 무엇인지 알아보도록 하겠습니다.
Foreground Background Merging
일단 motion이 활발한 곳을 찾기 위해서는 프레임의 변화를 살펴볼 필요가 있습니다. 물론 optical flow가 이런 역할을 대신해 주지만 본 논문에서는 optical flow를 사용하지 않았네요. Optical flow를 준비하는 것은 굉장히 time consuming 한 작업이기 때문에 저자는 optical flow 대신 frame의 미분 만을 이용해서 motion 영역을 찾고자 한 것입니다.
일단 인접한 프레임에 대해서 반복적으로 미분을 수행합니다. 그냥 픽셀 값을 뺀 것이죠. 이것을 temporal 축과 channel 축에 대해서 진행합니다.
- $X\in R^{C\times T\times H\times W}$ : $C$는 채널 수이고 $T$는 temporal dimension입니다.
- $S=\frac{1}{T-1} \sum^{C}_{c=1} \sum^{T-1}_{t=1} \parallel X_{c,t+1}-X_{c,t}\parallel ,S\in R^{H\times W}$ : channel 축과 temporal 축에 대한 미분을 누적시켜 seed region $S$를 생성합니다.
직관적으로 frame difference는 자연스러운 motion의 변화를 잡아주기 때문에 움직이는 foreground object는 상대적으로 큰 값을 가지게 됩니다. 특히나 foreground object의 edge 영역이 굉장히 큰 값을 가진다고 하네요. Foreground edge로부터 시작해 object까지 확장을 시키기 위해서 저자는 seed propagation을 활용합니다.
- $N^{(F)}$ : Foreground 영역에 존재하는 픽셀의 total number를 의미합니다.
- $N^{(F)}_{x}$ : 임의의 색상 x가 Foreground 영역에 얼마나 있는지 total number를 의미합니다.
- $P(x\mid F)=N^{(F)}_{x}/N^{(F)}$ : Foreground 영역에서 색상 x의 비율을 나타냅니다.
그러면 저 $N^{(F)}$ 이걸 어떻게 정의할 건지가 중요한데 저자는 그냥 seed region에서 상위 50%를 사용했다고 하네요. Seed region에서 큰 값을 가지는 부분은 foreground일 확률이 높으니깐 상위 50%의 해당되는 부분은 foreground region이라고 정의한 것 같습니다. 그리고 $N^{(B)}$ background는 하위 10%를 가지고 sampling 합니다.
- $N^{(F)}=[0.5\times H\times W],N^{(B)}=[0.1\times H\times W]$
그러고 나서 한 가지 가정을 합니다. 색상이 같다면 foreground 이거나 background 일 확률이 동일하다는 가정을 합니다. 어째서 이런 과감한 가정을 했는지에 대해서 부연 설명이 없어 우선 받아들이고 넘어가겠습니다.
일단 우리에게 중요한 것은 어떠한 픽셀 x가 주어졌을 때 그 픽셀이 foreground인지 판단할 수 있는 확률을 정의하는 것이 필요합니다.
- $ P(F\mid x)$ : 어떠한 픽셀 x라는 새로운 정보가 주어졌을 때 $P(F)$에 대한 사후 확률입니다.
그리고 위에서 살펴본 베이즈 정리를 이용하면 다음과 같이 전개할 수 있습니다.
- $P(F\mid x)=\frac{P(x\mid F)P(F)}{P(x)} $
이때 $P(x)$는 전 확률 공식을 통해 정리할 수 있습니다. 무슨 소리냐면 픽셀에게 가능한 경우는 foreground에 속해있거나 background에 속해있을 경우 두 가지밖에 없습니다. 즉, $P(x\mid F)P(F)+P(x\mid B)P(B)$ 이렇게 정리할 수 있습니다.
- $P(F\mid x)=\frac{P(x\mid F)P(F)}{P(x)} =\frac{P(x\mid F)P(F)}{P(x\mid F)P(F)+P(x\mid B)P(B)} $
그런데 이때 여기서 $P(F)=P(B)$라는 가정을 했기 때문에 분모 분자에 $P(F),P(B)$를 소거할 수 있습니다. 최종적으로
- $P(F\mid x)=\frac{P(x\mid F)}{P(x\mid F)+P(x\mid B)} $
이렇게 정리가 되네요. 이렇게 임의의 픽셀 x가 주어졌을 때 Foreground인지 나타내는 확률을 알 수 있다면 간단한 segmentation mask를 생성할 수 있습니다.
- $\left[ M\right]_{ij} =P(F\mid x_{ij})\in R^{H\times W}$
그리고 이진화를 합니다. 확률 마스크에서 확률이 높은 상위 $\beta$%는 1로 나머지는 0으로 처리해 주는 것입니다.

여기서 $\beta \in [0,1]$로써 foreground 비율을 나타내는 hyper-parameter입니다.
그리고 나면 새로운 비디오 클립을 생성할 수 있습니다.
- $X_{merge}=X\otimes \tilde{M} +Y\otimes (1-\tilde{M} )$
여기서 $X$는 원래 비디오고 $Y$는 다른 랜덤 비디오입니다. $X$에서 Motion을 따오고 $Y$에서 Background를 따와서 새로운 motion-positive video를 만드는 것이죠.
여기서 한 가지 중요한 것은 랜덤 하게 비디오를 사용하기 때문에 배경 부분에도 다른 motion pattern이 들어갈 수 있는데 이는 학습에 중요한 요소라고 합니다. 배경 부분에 정말로 배경만 있으면 강인하게 motion pattern을 학습하기 어렵다는 이유 때문입니다.

이렇게 motion은 동일하고 배경이 다른 두 비디오에 대해서 서로 feature representation이 같아지는 contrastive learning을 통해 저자는 FAME(Foreground Background Merging)이라는 framework를 제안했습니다.
Experiments
Ablation Study
Area Ratio of Foreground Region
Segmentation Mask를 만들 때 foreground 비율을 어느 정도로 할지 정의하는 $\beta \in [0,1]$에 대한 ablation입니다.
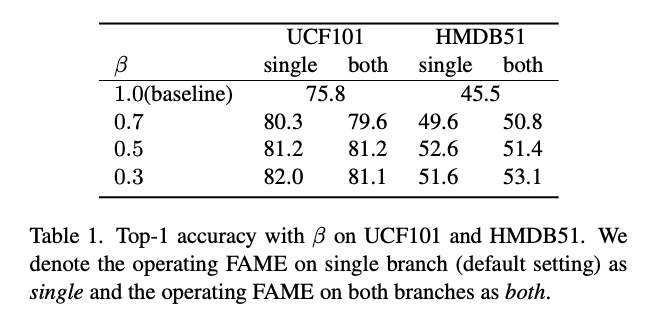
$\beta$가 0이라는 것은 motion과 background를 분리하지 않고 visual augmentation만을 한 것을 의미합니다. 기존 베이스라인 대비 action recognition task에서 성능 향상을 얻을 수 있었습니다. 데이터셋마다 최적의 비율은 조금 다르네요. 여기서 both라고 표기된 성능 같은 경우는 MoCo framework에 저자가 제안한 방식을 적용한 것이라고 합니다. single은 저자가 제안한 베이스 방식인데 MoCo와 큰 차이가 없는 것을 통해 저자가 만든 베이스 방식만으로도 충분히 background debiased learning을 수행할 수 있다고 주장합니다.
Background Source
다음은 background source를 어디서 가져와야 하는지 분석한 실험입니다. 간단하게 두 가지 비교 군이 있는데 같은 비디오 다른 클립을 사용했을 때와 다른 비디오에서 가져온 경우를 비교했습니다.
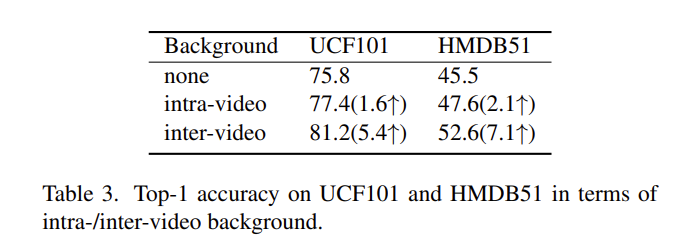
같은 비디오는 결국 background가 비슷하기 때문에 강인하게 학습을 할 수 없었던 모양입니다. 서로 다른 비디오에서 background를 샘플링하는 것이 훨씬 더 풍부한 pair를 만들어주기 때문에 motion pattern을 더 잘 학습할 수 있었나 봅니다.
Variants of Foreground Mask
논문의 핵심이라고 볼 수 있었던 foreground mask 만드는 방식을 다른 방식들로 대체했을 때의 분석입니다.
- Gauss : 2D Gaussian kernel을 foreground mask라고 가정하는 것입니다.
- Seed : 베이즈 정리를 통해서 만들어낸 확률 맵을 가지고 masking을 하는 것이 아니라 그 전 단계인 Seed Region에서의 Top-$\beta $만을 사용해서 만든 Mask입니다.
- Grid : Seed Region을 4x4 Grid로 분할하고 Sum pooling을 적용합니다. 그리고 16개의 Grid 중 sum pooling 값이 큰 8개의 Grid 만을 살려서 Foreground라고 정의하는 방식입니다.
글만 보면 애매하니 간략한 그림도 같이 보도록 하겠습니다.

그림을 보면 이제 각 방법론이 어떤 느낌인지 이해할 수 있을 것 같네요. 이렇게 mask를 만들어서 motion과 background를 잘 분리하는 것이 본 논문의 핵심이었는데 정량적으로 성능을 한번 비교해 보도록 하겠습니다.
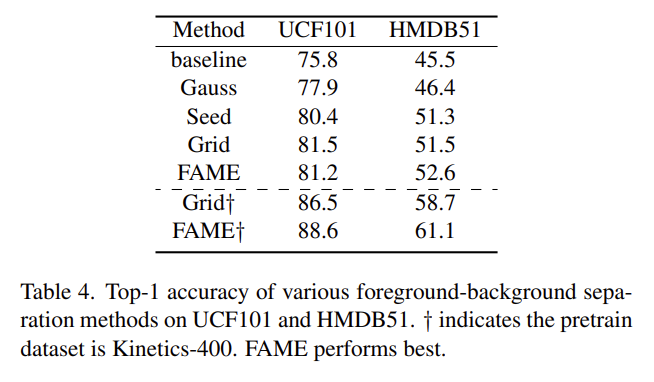
일단 베이스라인 대비 모든 방법론이 성능 개선을 이룰 수 있었네요. 신기하지만 Gauss 필터를 적용한 것도 성능이 개선되었다니 흥미롭네요 아무런 관련이 없을 줄 알았는데 말입니다.
Kinetics-400으로 사전 학습을 하지 않았을 때는 UCF101에서는 Grid 방식이 좋고 HMDB51에서는 FAME 방식이 좋네요.
하지만 사전학습을 했을 때 즉, motion-aware representation을 down-stream task에 transfer 할 때는 FAME 방식이 둘 다 좋은 모습을 보여줍니다. 이를 통해 Grid 방식으로 rough 하게 mask를 만드는 것보다 세밀하게 마스크를 만들어주는 방식이 좀 더 학습을 용이하게 만들어주는 것 같네요.
Evaluation on Downstream Tasks
Action Recognition on UCF101 and HMDB51

Action Recognition에 transfer learning 했을 때 benchmarking입니다. Back-bone 별로 다양하게 실험을 했는 데 결국 저자가 제안한 방식이 가장 좋은 성능을 보여줍니다. 전년도 SOTA 임과 동시에 motivation이 비슷했던 background erasing(BE)를 꽤나 큰 폭으로 앞질렀네요.
Video Retrieval on UCF101 and HMDB51
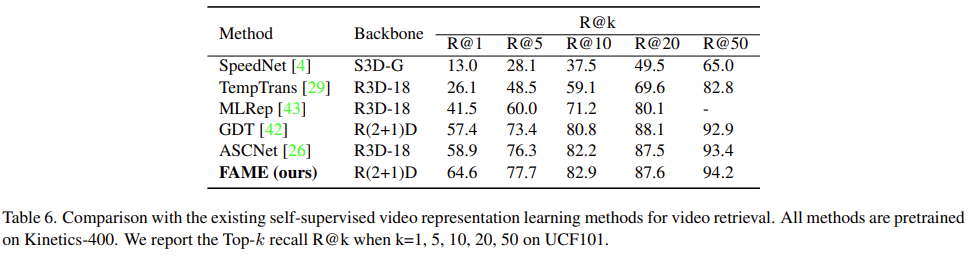
Video Retrieval 실험입니다. 역시나 가장 좋은 성능을 보여주면서 action 자체의 의미론적 정보도 잘 잡아준다는 것을 보여주고 있습니다.
Conclusion
Color distribution을 가지고 foreground 영역을 찾는다는 아이디어가 간단하지만 아직 아쉬운 부분이 남는 것 같습니다. 실제로 저자 역시 motion 부분과 background 영역의 color distribution이 비슷한 부분은 여전히 한계점이라고 언급을 하고 있네요.
뭔가 video representation learning 쪽 연구들은 복잡한 설계 대신 간단하면서 직관적인 아이디어로 승부를 보는 느낌이 있습니다.
이상으로 리뷰 마치도록 하겠습니다.



