Before Review
이전에 리뷰를 작성했던 Bas-Net이라는 논문의 후속작이라 보면 될 것 같습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Weakly Supervised Temporal Localization(이하 W-TAL)은 snippet level의 feature를 추출하고 Temporal-Class Activation Sequence(이하 T-CAS)를 생성하여 thresholding을 거쳐 localization을 수행하는 것이 일반적인 process 입니다.
그리고 T-CAS를 이용하여 video-level의 score vector를 만들고 video-level에서의 classification을 수행합니다. 결국 video level의 classification에 도움이 되는 snippet을 찾아서 grouping 잘 하는 것이 핵심이라 볼 수 있습니다.
본 논문의 저자는 2020년 AAAI에 공개된 Bas-Net의 저자와 동일합니다. Bas-Net의 아이디어는 다음과 같습니다. Untrimmed Video내에서 localization을 하는 것은 필연적으로 background의 영향을 많이 받기 때문에 background라는 auxiliary class를 만들어 background에 대한 고려도 해야 된다라는 주장을 담은 논문이었습니다.
본 논문의 Motivation도 비슷합니다. 여전히 background는 중요하게 고려됩니다. Background에 대한 처리를 어떻게 구성하냐에 따라 localization 성능이 달라진다는 것이죠. 저자는 일단 background의 종류를 두 가지로 분류를 합니다.

(a) dynamic은 쉽게 말해 background라고 부르기 애매해서 dynamic 하다는 것 입니다. SoccerPenalty라는 영상에서 저기 red box로 칠해진 부분들은 background이지만 맥락 자체는 soccer와 비슷하기 때문에 dynamic 하다 이렇게 정의를 했네요.
(b) inconsistent는 아예 관련이 없는 부분을 의미합니다. 비교적 찾기 쉬운 background라 볼 수 있지요. Golfswing 비디오에 대해서 green box로 칠해진 앞의 두 부분은 아무런 관련이 없다고 볼 수 있습니다.
그리고 저자는 서두에서 이전에 작업했던 Bas-Net의 한계를 밝히고 있습니다. 이렇게 dynamic하고 inconsistent 한 background들에 대해서 하나의 class로 강제하기에는 어려움이 따른다는 것이죠.
그래서 본 논문에서는 새로운 관점을 제시합니다.
단순히 하나의 클래스로 강제하는 것이 아니라 background들을 out-of-distribution(이하 OOD)으로 보자는 것입니다.
그리고 여기에서 background들을 OOD로 분류하기 위한 장치로 uncertainty를 도입합니다. 그리고 uncertainty를 정의하기 위한 중요한 observation이 하나 있습니다.
Action segment의 feature magnitude(L2-norm)은 상대적으로 큰 값을 가지고 background segment의 feature magnitude(L2-norm)은 상대적으로 작은 값을 가진다는 것입니다. 아마 GT를 참고한 관찰이지 싶은데 그래프로 보도록 하겠습니다.
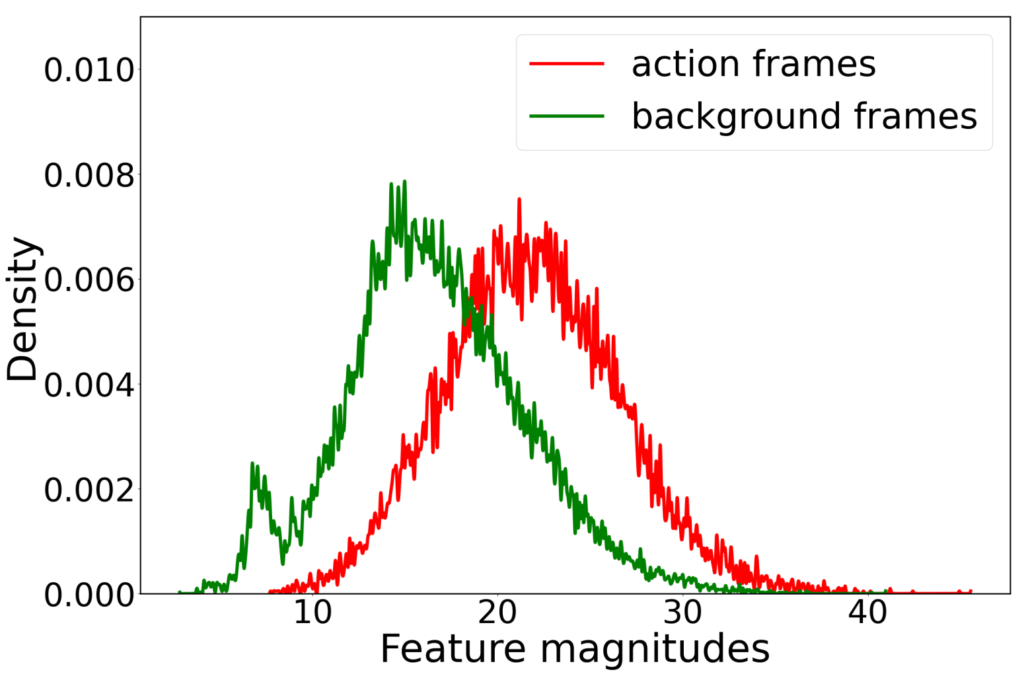
action frame들의 feature magnitude의 분포가 background frame의 분포보다 상대적으로 더 큰 magnitude를 가지는 분포로 나타나고 있습니다. 저자는 이것에 대한 이유로 다음과 같이 설명합니다.
"This is because action frames need to produce high logits for ground-truth action classes."
너무 간결하게 서술 되어있어 사실 해석하는데 조금 어려웠습니다. 그래서 저의 추측을 조금 담아 해석을 해보면 아마 저 feature들은 backbone feature나 다른 베이스라인 방법론으로 만들어낸 feature일 것 같습니다. 학습 자체는 action frame들이 ground truth에 해당하는 부분에서 더 높은 softmax score들을 만들어내야 하니 비교적 action frame들의 feature들은 high logit 값들을 담고 있고 L2-norm을 적용해보면 평균적으로 magnitude가 높아지는 것이라 추측할 수 있을 것 같네요.
이러한 관찰을 통해 저자는 action segment와 background segment간의 magnitude를 확연하게 구분할 수 있게 해주는 framework를 제안합니다. 그래서 action segment들의 feature magnitude는 높게 만들어서 높은 softmax score를 만들 수 있게 설계해주고 background feature magnitude는 작게 만들어서 낮은 softmax score를 만들게 하는 것이 목적입니다.
논문의 컨셉은 이 정도로 설명하고 이제 제안한 방법론에 대해서 알아보도록 하겠습니다.
Method
전체 framework 입니다. 그리 복잡하지 않으니 하나씩 살펴보도록 하겠습니다.
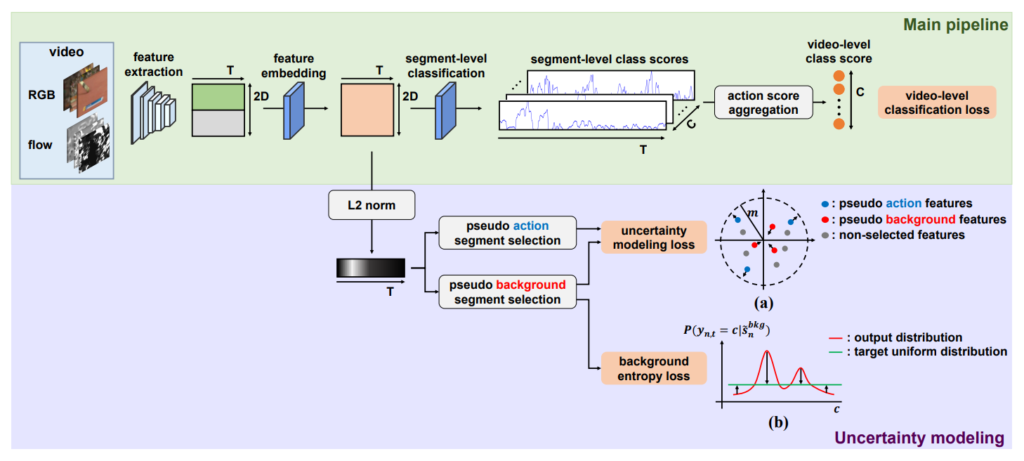
Feature Extraction
Feature extraction과 embedding은 간단합니다. Untrimmed 비디오는 비디오마다 길이가 다양하기 때문에 고정된 길이(T)로 맞춰주고 각 segment를 pretrained backbone에 넣어서 각 segment마다 feature를 기술합니다. Flow를 같이 사용해주는 이유는 action의 동적인 변화를 capture 하는데 유용하기 때문이죠. 아래의 그림을 보면 feature extraction은 쉽게 이해할 수 있을 것 같습니다.
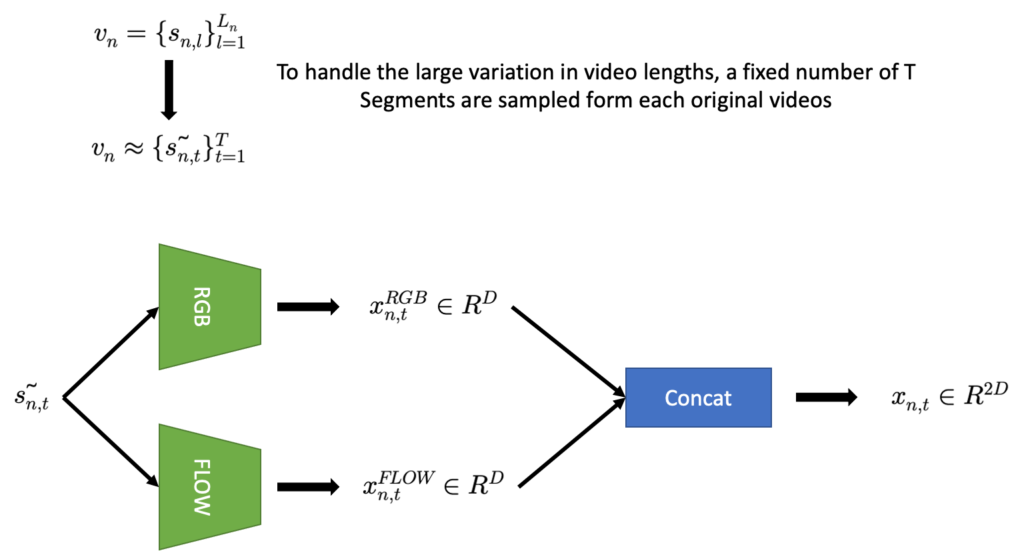
그래서 결국 segment 단위로 feature들을 모두 기술한 뒤 모아주면 비디오를 segment-level의 feature set으로 정의할 수 있습니다.
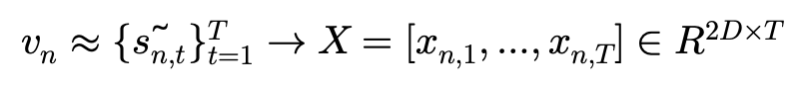
Video level Classification
Video level의 action category를 예측하기 위해서는 video-level score가 필요할 것 같습니다. 그렇다면 이것은 어떻게 만들 수 있을까요? 위에서 정의해준 $ v_{n}$에 두 번의 연속적인 1D convolution을 적용해주면 얻을 수 있습니다.
- $ v_{n}\in R^{2D\times T}\rightarrow A_{n}\in R^{C\times T}$
이렇게 feature의 채널 차원에 대해서 convolution을 진행해주면 $ A_{n}\in R^{C\times T}$ Temporal Class Activation Sequence(T-CAS)라는 것을 얻을 수 있습니다.
우선 T-CAS에서 각 class별로 top-k개의 snippet을 선택합니다. 그 class를 책임지는 대표 snippet을 선택한 다음 score를 평균 내줍니다. 이렇게 class 별로 top-k mean pooling을 거치면 class 마다 하나의 score를 얻을 수 있고 class 별로 모두 모아주면 video-level score vector를 얻을 수 있습니다.
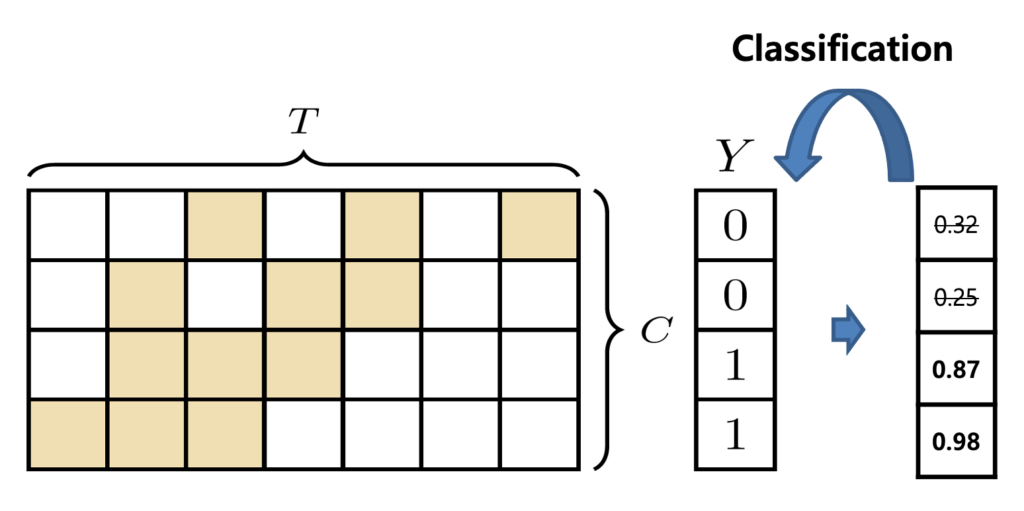
그리고 나면 cross entropy loss를 통해서 최적화를 할 수 있습니다.
- $ L_{a}=-\frac {1}{N} \sum^{N}_{n=1} \sum^{C}_{c=1} \hat {y}_{n;c} log(p_{n;c})$
Uncertainty formulation
Weakly Supervised Temporal Localization의 핵심은 단순히 video-level classification만 하는 것이 아니라 그 외 추가적인 task를 생성하여 모델이 T-CAS를 더욱 잘 만들도록 해주는 것이 핵심입니다.
본 논문은 각 segment를 보았을 때 이 segment가 action인지 아니면 background인지 판단하기 위해 Out-of-Distribution 개념을 도입하게 됩니다. 그것을 위해서 일단 각 segment가 특정 action class일 확률을 뜯어보도록 하겠습니다.
$ n $ 번째 비디오에 대해서 $ t $ 번째 segment가 $ c $라는 action class일 확률을 우리는 이렇게 정의할 수 있습니다.
- $ P(y_{n, t}=c|\tilde {s_{n, t}} )$
그리고 $d$라는 background discrimination 용도의 변수를 도입합니다. $ d\in \{ 0, 1\} $ 일 때, $ d=1 $이라면 segment는 임의의 action class에 속해있다는 것을 의미하며 $ d=0 $는 segment가 background임을 의미합니다. 새로 도입한 변수를 이용하여 위의 확률을 다시 정의하면 아래와 같습니다.
- $ P(y_{n, t}=c|\tilde {s_{n, t}} )=P(y_{n, t}=c, d=1|\tilde {s_{n, t}} )$
그리고 조건부 확률의 연쇄 법칙에 의하여 다시 아래와 같이 분해할 수 있습니다.
- $ P(y_{n, t}=c, d=1|\tilde {s_{n, t}} )=P(y_{n, t}=c|d=1,\tilde {s_{n, t}} )\times P(d=1|\tilde {s_{n, t}} )$
자 이제 이렇게 두 가지의 확률로 분해된 녀석들을 살펴보면
- $ P(y_{n, t}=c|d=1,\tilde {s_{n, t}} )$ : 그냥 일반적으로 Video-Classification 할 때 사용되는 확률입니다. T-CAS에 나타나는 확률 값이라 보면 됩니다.
- $ P(d=1|\tilde {s_{n, t}} )$ : 이 녀석이 우리가 고려해야 될 값이라 보면 됩니다. Segment가 In-distribution인지 Out-of-Distribution인지 나타내는 확률 값인 셈이기 때문입니다. 이 조건부 확률을 해석하면 $\tilde {s_{n, t}} $ segment일 때 In-distribution인지 나타내는 확률 값이기 때문이죠.
그런데 아까 Introduction에서도 살펴봤지만 In-Distribution(Action)의 feature magnitude는 Out-of-Distribution(Background)에 비해 상대적으로 크다는 관측을 보았습니다. 여기서 motivation을 얻어 $ P(d=1|\tilde {s_{n, t}} )$ 일종의 uncertainty 역할을 할 수 있는 이 확률 값을 아래와 같이 정의합니다.
- $ P(d=1|\tilde {s_{n, t}} )=\frac {min\left( m,\parallel f_{n, t}\parallel \right) }{m} $
해석을 해보자면 우선 $\parallel f_{n, t}\parallel $는 feature의 magnitude를 나타내며 이는 L2-Norm으로 계산합니다. $ m $은 사전에 정의된 최대 feature magnitude입니다.
이제 저 확률의 의도는 만약 feature가 In-distribution(Action)이라면 feature의 magnitude가 $m$보다 크거나 $m$에 비슷한 수준일 것이고 $ P(d=1|\tilde {s_{n, t}} )$ 이 값은 1에 가까워집니다.
반대로 feature가 Out-of-distribution(Background)이라면 feature의 magnitude가 $m$보다 작을 것이고 $ P(d=1|\tilde {s_{n, t}} )$ 이 값은 0에 가까워집니다.
자 그렇다면 Out-of-Distribution을 판단하는 Uncertainty 자체는 $P(d=1|\tilde{s_{n,t}} )=\frac {min\left( m,\parallel f_{n, t}\parallel \right) }{m} $ 이렇게 정의가 되었습니다.
우리의 다음 스텝은 정말로 Out-of-distribution 일 때 feature의 magnitude가 작아지도록 만들어주어야겠네요.
Uncertainty Learning
자 본격적으로 Loss를 논하기 전에 정하고 가야 할 것이 남아있습니다. P(d=1|\tilde {s_{n, t}} )를 보았을 때 우리는 어떤 segment가 $ d=1 $이고 어떤 segment가 $ d=0 $인지 정의를 해야 합니다. Video-level의 annotation만을 사용하기 때문에 임의로 In-Distribution, Out-of-Distribution을 정의를 해야 될 것 같습니다.
방법은 굉장히 간단합니다.
T-CAS에서 score가 높은 top-k의 segment는 pseudo-action class로 In-Distribution($ d=1 $)에 해당됩니다.
T-CAS에서 score가 낮은 bottom-k의 segment는 pseudo-background class로 Out-of-Distribution($ d=0 $)에 해당합니다.
그리고 우리는 학습을 할 때 모든 segment를 이용하는 것이 아닌 pseudo action/background segment들만 사용을 하게 됩니다.
Training Objective
학습은 세 가지의 Loss를 가지고 jointly 하게 진행이 됩니다.
Video-level Classification Loss
A라는 untrimmed video에서 어떤 action들이 존재하는지 예측하는 작업입니다. 우리가 video-level의 annotation만을 사용하기 때문에 일단 classification task로 학습을 진행하게 됩니다.
- $ L_{a}=-\frac {1}{N} \sum^{N}_{n=1} \sum^{C}_{c=1} \hat {y}_{n;c} log(p_{n;c})$
Uncertainty Modeling Loss
이제 feature의 magnitude를 control 해줄 loss를 정의해줄 겁니다.
- $ L_{um}=\frac {1}{N} \sum^{N}_{n=1} \left( max\left( 0, m-\| f^{act}_{n}\| \right) +\| f^{bkg}_{n}\| \right)^{2} $
Loss를 발생시키지 않는 상황을 가정해본다면 $ m <\| f^{act}_{n}\| \ $ 이면서 $\| f^{bkg}_{n}\| \rightarrow 0 $의 방향으로 가야 합니다.
즉, In-Distribution의 feature magnitude는 $m$보다 커지게 되고, Out-of-Distribution의 feature magnitude는 0에 가까워지는 방향으로 학습이 진행된다고 볼 수 있습니다.
Background Entropy Loss
위의 Uncertainty Modeling Loss를 통해서 feature의 magnitude는 control 할 수 있었습니다. 하지만 Out-of-Distribution segment에 대해서 T-CAS가 담고 있는 softmax score는 여전히 높은 값을 가질 수 있습니다. Out-of-Distribution segment는 softmax function을 통해서 나온 score는 작은 값을 가져야만 합니다 localization에 방해가 될 수 있기 때문입니다. 따라서 이 Out-of-Distribution segment의 softmax score를 control 하는 loss를 추가하게 됩니다.
- $ L_{be}=\frac {1}{NC} \sum^{N}_{n=1} \sum^{C}_{c=1} -log(p_{c}(s^{\sim bkg}_{n}))$
- $ p_{c}(s^{\sim bkg}_{n})=\frac {1}{k^{bkg}} \sum\nolimits_{j\in S^{bkg}} p_{c}(\tilde {s} , j)$
그런데 저는 여기서 조금 의아했던 부분이 $ L_{be}=\frac {1}{NC} \sum^{N}_{n=1} \sum^{C}_{c=1} -log(p_{c}(s^{\sim bkg}_{n}))$를 최소화시키기 위해서는 결국 $ p_{c}(s^{\sim bkg}_{n})$이 1에 가까워져야 합니다.
$ p_{c}(s^{\sim bkg}_{n})$ 1에 가까워진다는 의미는 Out-of-Distribution Segment의 softmax score가 모두 1에 가까워짐을 의미합니다. 물론 score들을 uniform 하게 만들 수 있겠지만 uniform 하게 1에 가까워지는 것이 아닌가라는 생각이 드네요.
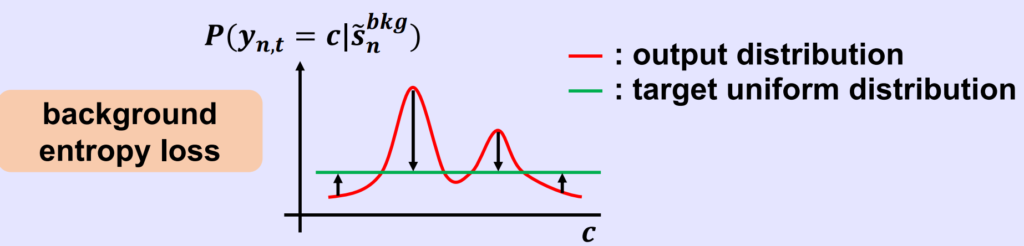
이 부분은 나중에 코드를 돌려본다면 확인해보도록 하겠습니다.
Inference
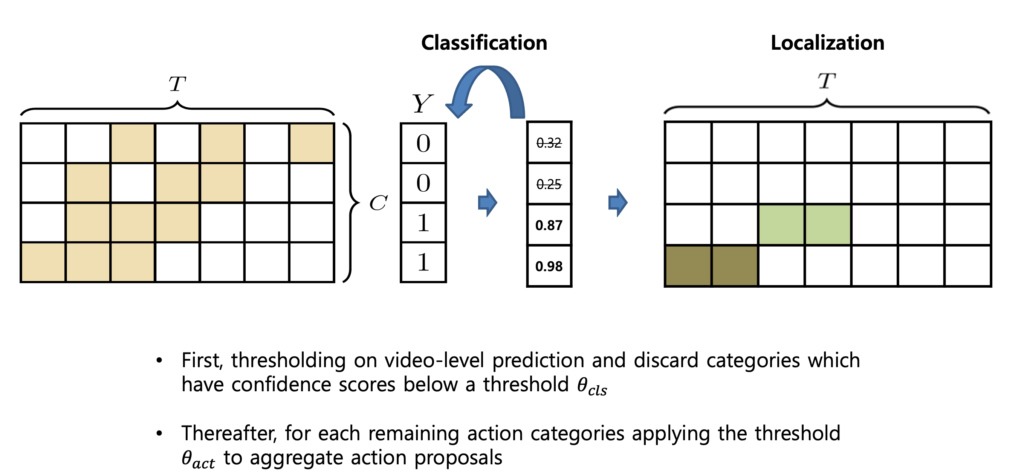
W-TAL에서 inference는 크게 세 단계로 나눌 수 있습니다.
- CAS에서 Video-level score vector를 만들고 video-level thresholding을 진행합니다. 즉, 일정 threshold 이하의 action category에 해당하는 CAS는 사용하지 않는다는 것이죠 아래의 그림을 보면 0번째, 1번째 Class는 제거가 된 모습입니다.
- 그다음으로는 snippet level thresholding을 진행합니다. Video-level thresholding을 거치고 살아남은 class에 대한 CAS를 살펴봤을 때 score가 높은 snippet들을 살려두고 grouping 해서 proposal을 만드는 것이죠.
- 이렇게 해서 만들어진 proposal 들에 대해서 Non-Maximum Suppression을 통한 후처리를 해준다면 Inference의 과정은 모두 끝이 나게 됩니다.
Experiments
Dataset
THUMOS14 dataset : 원래는 101가지의 action class를 가지는 데이터셋이지만 그중 20개의 class에 대해서만 temporal annotation을 제공합니다. 200개의 validation video로 학습을 진행하고 213개의 test video로 평가를 한다고 합니다. 200개의 비디오만 사용한다고 해서 task의 난이도가 쉬운 것은 아닙니다. 왜냐하면 비디오의 길이가 평균 4분 정도이기 때문이죠. 또한 action의 영역이 굉장히 sparse 하기 때문에 action과 background 간의 imbalance가 조금 심한 데이터셋입니다.
ActivityNet dataset : 200가지의 action class를 가지고 있는 데이터셋으로 temporal action localization benchmark를 위해 등장한 데이터셋입니다. 평소에는 test data에 대해서 평가를 할 수 없고 activitynet challenge 기간에만 평가 서버가 열려서 test data에 대해서 평가할 수 있습니다. 이러한 제한적인 상황 때문에 보통 연구를 할 때는 10024개의 train 데이터로 학습하고 4926개의 validation 데이터로 평가를 진행하다고 합니다
Comparison With State-of-the-art Methods
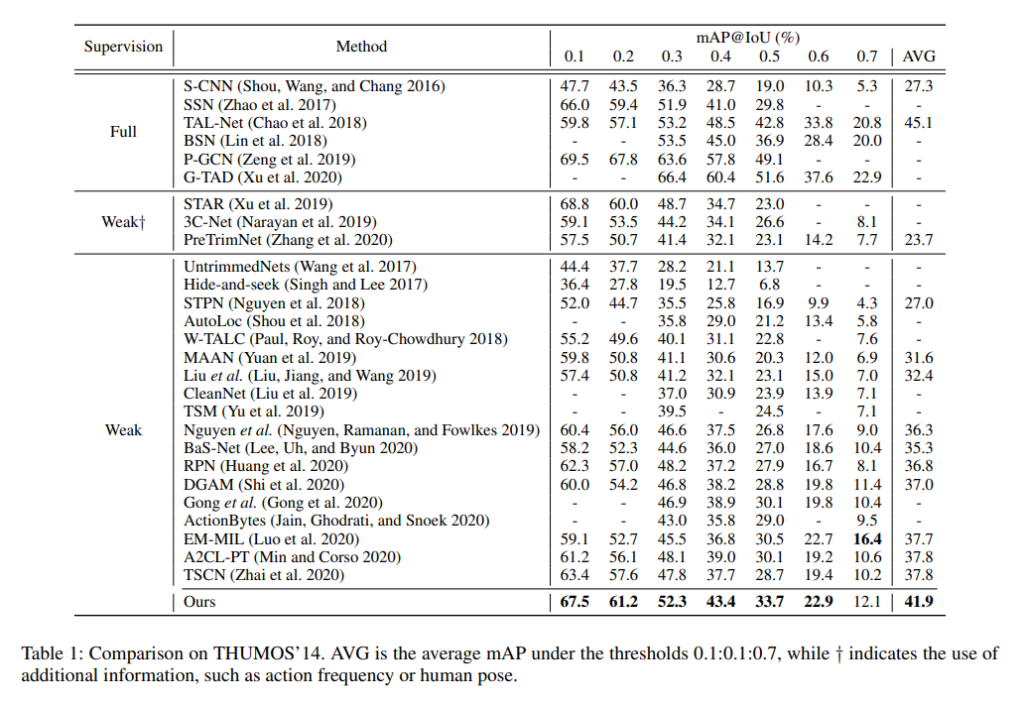
THUMOS'14에서의 벤치마킹입니다. Weakly-Supervised 진영에서는 21년도 기준으로 전년도 방법론들과 비교했을 때 SOTA의 성능을 보여주고 있습니다.
인상 깊은 것은 Bas-Net이라 적혀있는 방법론이 저자가 20년도에 제안한 방법론인데 불과 1년 사이에 35.3->41.0으로 성능 향상을 이루었습니다. 참으로 뿌듯할 것 같습니다.
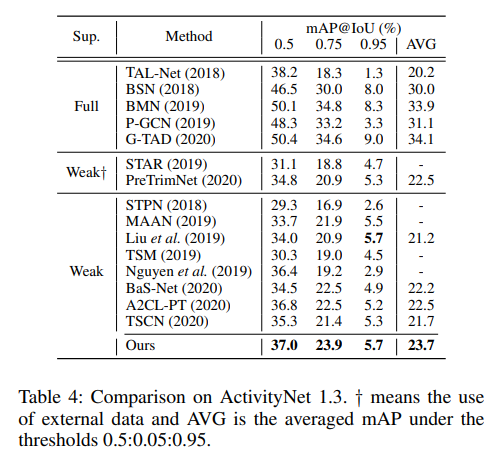
ActivityNet에서도 Weakly Supervised 진영에서는 SOTA를 달성하고 있고 이 데이터셋에서는 18년도에 나온 TAL-Net이라는 방법론을 이겨버렸습니다. 슬슬 WTAL 연구들이 과거의 supervised 연구들을 따라잡고 있는 것 같네요.
Ablation Studies
다음으로는 중요한 Ablation입니다.

자 우선 Score 부분에 softmax와 fusion으로 나뉘었습니다.
softmax는 그냥 $ P(y_{n, t}=c, d=1|\tilde {s_{n, t}} )=P(y_{n, t}=c|d=1,\tilde {s_{n, t}} )\times P(d=1|\tilde {s_{n, t}} )$에서 앞부분인 $ P(y_{n, t}=c|d=1,\tilde {s_{n, t}} )$이 확률만 사용한 것입니다.
fusion은 둘 다 사용한 fusion 된 score로써 학습을 진행한 것이라 보면 되겠습니다.
그리고 $ L_{cls}$ 말고 다른 Loss term들을 하나씩 추가했을 때의 성능입니다.
베이스라인은 에 비해 Uncertainty를 고려하여 fusion score를 사용했을 때의 성능 향상폭(22.6->32.5)이 상당합니다. 그리고 feature의 magnitude를 조절시켜주는 $ L_{um}$를 추가했을 때도 성능 향상폭이(32.5->40.2)로 역시 상당합니다. 마지막으로 Background entropy Loss를 추가해서 다른 방법론들에 비해 성능 폭을 늘릴 수 있도록 더욱 쪼아주었습니다.
이러한 Ablation Study가 말해주는 것은 확실히 feature의 magnitude 역시 정보가 부족한 WTAL에서는 효과적으로 사용이 될 수 있음을 보여주는 것 같네요.
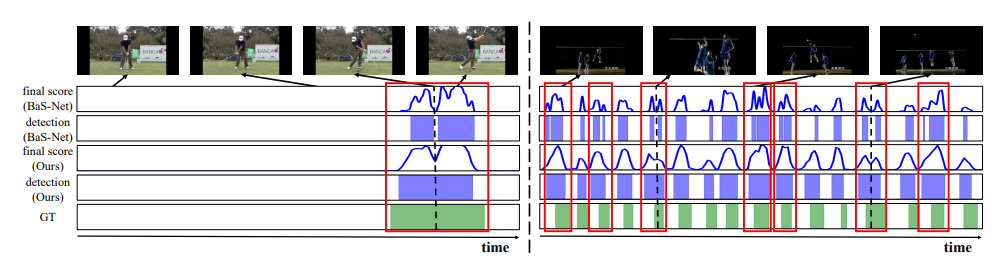
Qualitative Results
여기서는 20년도에 저자가 작성했던 Bas-Net과의 정성적 결과를 비교하고 있습니다. 핵심은 Bas-Net 같은 경우는 하나의 action instance를 쪼개서 예측하는 경향을 보이고 이번에 제안된 방법론은 그렇지 않다는 것입니다.
단순히 일관성 없는 background frame들을 하나의 class로 강제시키다 보니 이러한 한계가 나타난 것이라고 저자는 정리합니다. 반대로 이번 work은 uncertainty modeling을 통해 보다 더 background를 잘 이해하였기 때문에 성능이 높다 이렇게 주장을 합니다.
Conclusion
Feature의 magnitude로부터 insight를 얻어 이를 토대로 WTAL을 학습시킬 framework를 구상했다는 것이 인상 깊은 논문입니다.
이상으로 리뷰 마치도록 하겠습니다. 감사합니다.



