Before Review
Weakly Supervised Temporal Action Localization 분야에서 contrastive learning 개념을 도입한 논문입니다.
Contrastive pair를 생성하기 위해서 팽창(dilation)과 침식(erosion)이라는 기본적인 영상처리 기법의 개념을 도입한 논문입니다. 코드도 잘 공개되어 있기도 하고 원복 실험도 무리 없이 진행이 되어서 좋았던 논문 이었습니다.
리뷰 시작하도록 하겠습니다.
Preliminaries
본 논문의 핵심은 contrastive pair를 어떻게 구성을 할 것인가?라고 볼 수 있습니다. Weakly Supervised Temporal Action localization은 video level의 label 만을 제공하기 때문에 어떠한 구간에 대한 constastive pair를 만들기 어려운 감이 있습니다. 여기서 등장하는 것이 Dilation(침식)과 Erosion(팽창)입니다. 지금은 Dilation과 Erosion이 무엇인지만 간단하게 알아보고 리뷰 시작하도록 하겠습니다.
Dilation
팽창의 직관적인 의미는 무엇인가 커지는 상황이라 볼 수 있습니다. 따라서 팽창을 이미지에 적용시키면 물체의 크기를 증가시키는 효과를 얻을 수 있습니다. 수식으로는 아래와 같이 표현할 수 있는데 A는 원본 이미지라 보면 되고 B는 dilation mask라 볼 수 있습니다.
- A⊕B={(x,y)+(u,v):(x,y)∈A,(u,v)∈B}
결국 A의 모든 화소 (x,y)를 B에 대한 사본으로 치환하여 합 한다는 의미입니다. 아래의 그림을 보면 이해가 더욱 쉬울 것 같네요.

원래 A의 이미지는 주황색 라인으로 칠해진 부분이라 할 때, A에 대해서 B에 대한 Dilation을 진행하면 가장 왼쪽의 그림처럼 픽셀 값들이 분포하게 됩니다. B의 (0,0) 지점을 A의 모든 픽셀에서 치환한 다음 합쳐주었다고 보면 됩니다. 결과적으로 팽창을 진행하면 글씨체들이 조금 더 두꺼워지는 것을 확인할 수 있습니다.
Erosion
침식의 직관적인 의미는 무엇인가 줄어드는 효과를 생각할 수 있습니다. 그래서 이미지에 있는 물체들이 얇아지거나 작아지는 효과를 얻을 수 있겠죠. 수식으로는 아래와 같이 표현할 수 있는데 A는 원본 이미지라 보면 되고 B는 erosion mask라 볼 수 있습니다.
- A⊖B={w:Bw⊆A}
Erosion mask인 B를 A에서 이동하면서 슬라이딩을 할 때 B가 A 내부에 완전히 속할 때, B의 (0,0) 위치에 점을 표시하는 것입니다. 이것 역시 그림을 보면 더욱 이해가 빠를 것 같습니다.
원래 A 이미지에서 B Masking을 했을 때 완전히 겹쳐지는 부분은 라인으로 칠해진 부분입니다. 연두색, 주황색, 하늘색 라인으로 둘러 쌓인 중앙 부분이 침식에 해당되는 포인트입니다. 침식에 해당되는 포인트만 살려주면 저렇게 세 개의 픽셀만 살아남게 되는 것이죠. 결과적으로 이미지의 라인이 조금 얇아지는 효과를 볼 수 있습니다.
여담으로 영상처리 에서는 팽창 이미지와 침식 이미지를 이용해서 경계선을 검출하는 응용 작업이 있습니다. 무튼 이것으로 Dilation(팽창)과 Erosion(침식)에 대한 설명을 마치고 본격적인 논문 리뷰에 들어가도록 하겠습니다.
Introduction
Weakly Supervised Temporal Localization은 제가 이전 리뷰에서도 많이 다뤘기 때문에 자세히 설명하지는 않겠습니다. 다시금 제대로 이해하고 싶은 분이 있다면 저의 이전 리뷰들을 차근차근 읽어보는 것을 추천드립니다.
Weakly Supervised Temporal Localization(이하 W-TAL)은 Snippet Level의 Feature를 추출하고 Temporal-Class Activation Sequence (이하 T-CAS)를 생성하여 thresholding을 거쳐 Localization을 수행하는 것이 일반적인 Process 였습니다. 그리고 T-CAS를 이용하여 Video-Level의 Score vector를 만들고 Video-level에서의 Classification을 수행하여 Video level의 classification에 도움이 되는 snippet을 찾아서 grouping 하는 것이 핵심이라 볼 수 있었죠.
하지만 위에서 설명한 baseline 방식으로는 snippet 끼리의 temporal context를 encoding 하기 어렵습니다. 단순히 temporal 차원으로 convolution 하는 것은 한계가 있다는 얘기입니다.저자가 주장하는 것은 "Snippet 끼리의 temporal context를 이해하는 것이 중요하다" 라는 것 입니다. 아래의 그림 예시를 한번 보도록 하겠습니다.
Cliff-Diving이라는 Action에 대한 비디오입니다. 그림을 보면 snippet이 #1부터 #4까지 존재하고 있네요. 여기서 #1은 분명하게 action임을 구분할 수 있고 #4는 분명하게 Background 임을 구분할 수 있습니다. 하지만 #2와 #3는 이게 action인지 Background인지 조금 애매한 감이 있습니다. 그리고 저자는 이러한 애매한 snippet들이 Localization 성능을 저하시킨다고 주장합니다.
이전에 리뷰 했던 [CVPR 2021] Weakly Supervised Action Selection Learning in Video 논문과 문제 정의는 비슷한 것 같습니다. 저자는 이러한 애매한 Snippet들을 발생시키는 문제를 Single Sinppet Cheating이라고 정의합니다. Snippet 끼리의 temporal context를 보지 않고 단일 Snippet에 의존해서 예측을 수행하기 때문에 발생하기 때문이라고 주장합니다. 여기서 저자는 Easy Snippet과 Hard Snippet 개념을 도입합니다.
Easy Snippet은 말 그대로 구분하기 쉬운 Snippet 의미합니다. 정확히 얘기하면 Snippet의 Feature Representation이 너무나도 명확해서 Action인지 Background인지 알기 쉬운 Snippet들을 의미합니다.
Hard Snippet은 반대로 구분하기 어려운 Snippet을 의미합니다. Snippet의 Feature Representation이 애매해서 이게 Action인지 Background 인지 구분이 어려운 Snippet들을 의미합니다.
그래서 총 4가지의 Snippet을 정의할 수 있습니다. Easy Action Snippet(EA), Hard Action Snippet(HA) , Easy Background Snippet(EB), Hard Background Snippet(HB)입니다.
이때 Contrastive Learning을 도입하면 Hard Action은 Easy Action과 Representation이 비슷해지고 Easy Background와 멀어지는 Representation Learning을 할 수 있습니다. 반대로 Hard Background는 Easy Background와 Representation이 비슷해지고 Easy Action과 멀어지는 Representation Learning을 할 수 있습니다.
이것이 본 논문의 아이디어입니다. 그런데 Contrastive Learning을 도입할 때 가장 중요한 것은 Contrastive Pair를 어떻게 구상하느냐입니다. 우리는 Temporal annotation이 없기 때문에 어느 구간이 action이고 어느 구간이 background 인지 모르는 상황입니다. 따라서 어느 Snippet이 Easy Snippet이고 어느 Snippet이 Hard Snippet인지 사전에는 알 수 없습니다.
특히나 Hard Snippet 같은 경우는 애매한 녀석들이기 때문에 더욱이 특정하기 힘들 수 있습니다. 이때 저자는 한 가지 intuition을 발휘해서 Hard Snippet을 정의합니다. 애매한 snippet들은 주로 action instance의 경계 지점에 위치할 수 있다는 것입니다. action의 경계는 action과 background가 변하는 지점이기 때문이죠. 당연히 ambigous 하다고 볼 수 있습니다.이러한 직관을 바탕으로 저자는 dilation과 erosion 연산을 통해 Hard Snippet mining 알고리즘을 제안합니다.
그다음에 Easy Snippet은 상대적으로 정의하기 쉽습니다. T-CAS에서 score가 상위 k개에 들어가면 Easy Action, score가 하위 k개에 들어가면 Easy Background라 정의합니다. 다른 snippet 들에 비해 두드러지게 T-CAS에서 score가 높다는 것은 그만큼 Feature Representation이 확실하다는 것이기 때문이죠.
논문의 컨셉을 간단하게 알아보았고 이제 좀 더 자세히 제안된 방법론에 대해서 같이 알아보도록 하겠습니다.
Method
Feature Extraction and Embedding
Video의 Snippet Level Feature 추출 방식은 다른 논문과 다른 점이 없습니다. Snippet 단위로 Backbone에 넣어서 Feature를 기술하고 마지막에 Concat 해주는 방식입니다.
RGB frame과 Optical Flow를 각각 I3D Network에 입력으로 넣어 Feature를 추출한 뒤 각각 Temporal Convolution을 진행한 뒤 Concat을 해주는 방식으로 Video Feature를 기술하고 있습니다. 그리고 Concat 된 Feature에다가 한 번 더 temporal convolution과 ReLU를 사용해서 embedding feature XEn∈RT×2d를 생성합니다.
여기서 T는 고정된 길이로 Temporal 차원에 대한 길이입니다. 비디오마다 길이가 다 다르기 때문에 Snippet들을 샘플링한 뒤에 Temporal 차원의 길이를 맞춰주는 작업을 필수적으로 진행해야 합니다. 논문마다 조금씩 다르긴 하지만 T 맞춰주기 위해 sampling을 하는 논문들도 있고 Interpolation을 하는 논문도 있습니다. 여기서는 sampling을 수행했네요.
그리고 d는 각각 modality에 대한 feature 차원입니다. 본 논문에서는 RGB와 Optical FLow를 둘 다 사용했고 concat 했기 때문에 2d로 기술이 되는 것입니다.
Actionness Modeling
그다음으로는 Actionness modeling 과정입니다. Actionness는 이전 리뷰 [CVPR 2021] Weakly Supervised Action Selection Learning in Video에서 다룬 적이 있는데 일반적인 action이 가질 수 있는 성질을 의미합니다. 그렇다고 해서 거창하게 action 자체의 본질적인 성질을 찾는 것은 아니고 Snippet이 class-agnostic 한 action인지 아닌지 구분할 수 있는 probability vector를 잘 구하는 것이 목적이라고 보면 됩니다.
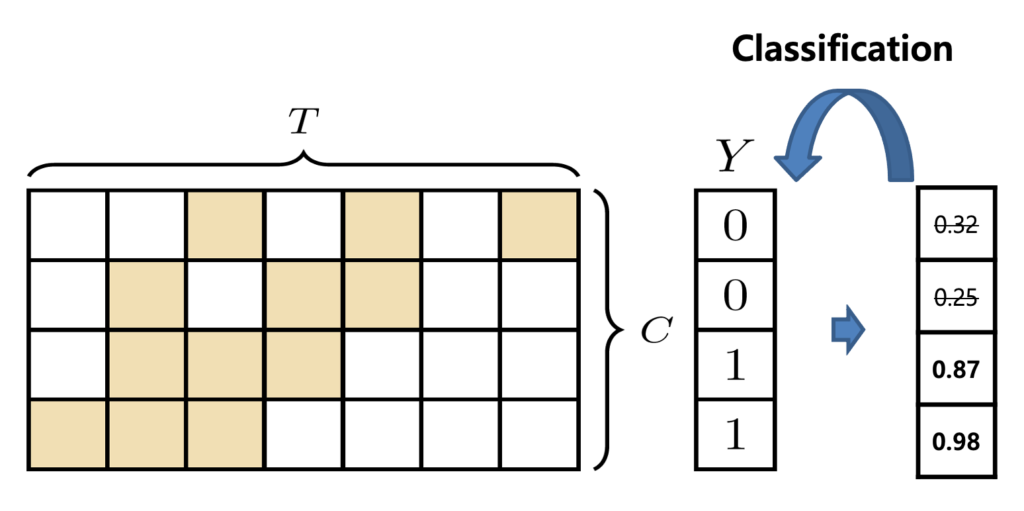
그러면 action probability vector는 어떻게 구할 수 있을까요? 여기서 T-CAS가 등장합니다. 그래도 이건 중요하니 다시 한번 짚고 넘어가도록 하겠습니다. T-CAS는 각 Snippet이 각 Class일 확률을 나타내는 Sequence Map입니다.
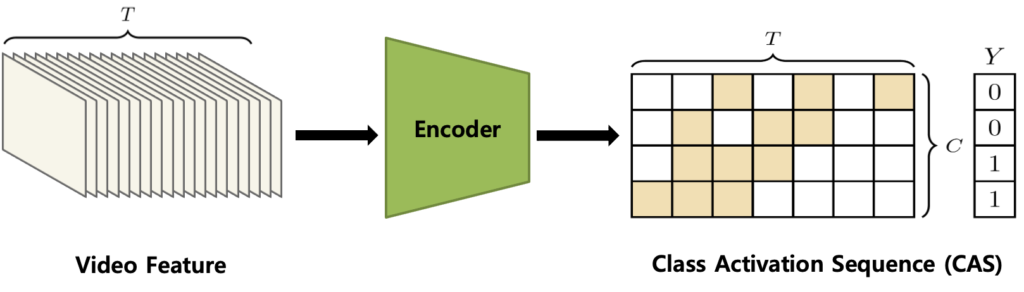
CAS에서 (0,0)에 해당하는 값은 무엇을 의미할까요? 가장 처음의 Snippet이 0번째 Action Category일 확률을 의미합니다. (T, C)에 해당하는 값은 T번째 Snippet이 C번째 Action Category일 확률을 의미하겠죠. 여기서 Class 차원으로 sum 연산을 취해줍니다. Class 축에 대해서 모든 확률을 더해주는 것은 어떻게 보면 Class-agnostic 한 action일 확률이라 볼 수 있겠죠. 따라서 action probability vector는 아래와 같이 구해줍니다.
- Anessn=Sigmoid(fsum(An))
결국, An∈RT×C⟹Anessn∈RT 이렇게 된다고 보면 됩니다.
Hard & Easy Snippet Mining
Hard Snippet Mining
애매한 snippet들은 주로 action instance의 경계 지점에 위치할 수 있다고 앞에서 얘기를 했었습니다. 그리고 여기서 침식(erosion) 팽창(dilation) 연산이 등장합니다. 일단 본격적으로 구하기 전에 Action binary mask를 만들어줍니다. 위에서 구해준 actioness probability에 대해서 thresholding을 거친 후 heavy side function을 취해주는 구조입니다.
- Abinn=ε(Anessn−θb)
그냥 간단하게 얘기하면 threshold 보다 넘은 score를 가지는 Snippet은 1 아니면 0 이렇게 할당해주는 구조라 보면 됩니다. 그리고 이 Mask를 가지고 이제 침식과 팽창 연산을 진행합니다. Hard Action은 침식 연산으로 계산합니다. 그리고 Hard Background는 팽창 연산으로 계산합니다.
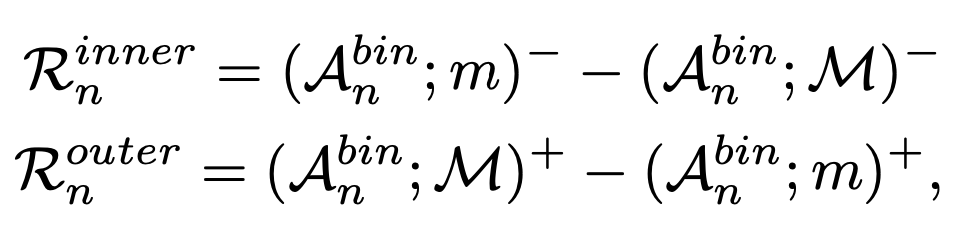
여기서 inner는 Hard action을 의미하고 outer는 Hard Background를 의미합니다. 그리고 (;)+ 연산은 erosion 연산을 의미합니다. 그리고 (;)−는 dilation 연산을 의미합니다. 무슨 소리인지 모르겠으니 그림으로 먼저 보도록 하겠습니다.
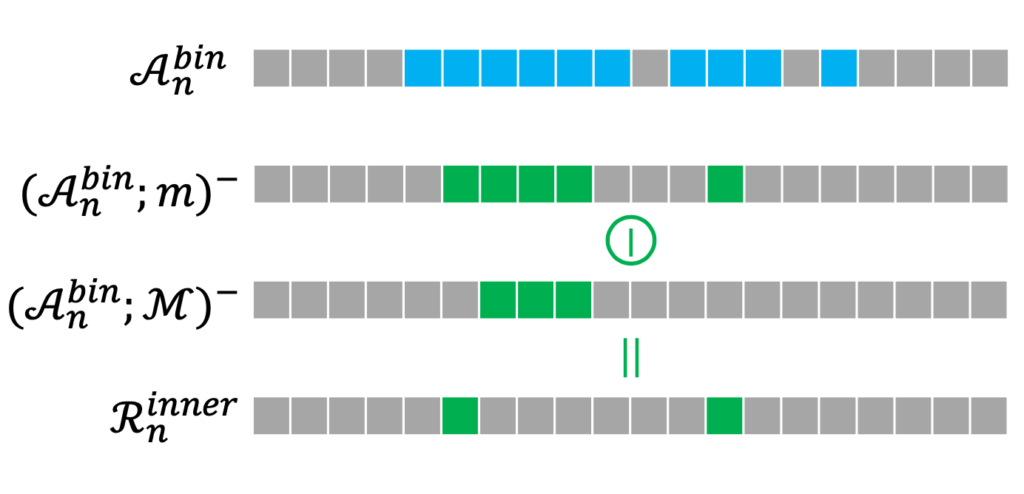
여기서 m mask는 가운데 포인트를 기준으로 양옆에 두 포인트가 완전히 속할 때 가운데 포인트를 살려주는 마스크라 보면 됩니다. 결과적으로 파란색인 부분에서 양옆으로 두 포인트를 포함할 수 있는 위치는 그림처럼 표시가 됩니다.
그 아래 M mask는 왼쪽에 두 포인트 오른쪽에 한 포인트가 속할 때 포인트를 살려주는 마스크입니다. 핵심은 이전에 했던 m masking 보다 더 큰 mask로 진행한다는 것입니다.
그리고 두 결과의 차이를 가지고 우리는 Hard action이라고 부르는 것이죠.
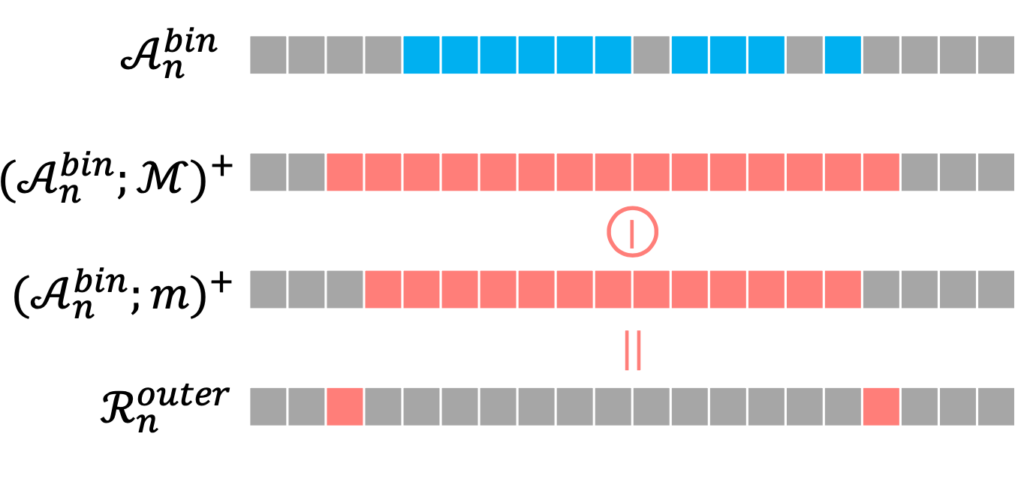
여기서 M mask는 가운데 포인트를 기준으로 양옆에 두 포인트씩을 추가하여 살려주는 마스크라 보면 됩니다. 결과적으로 조금 더 넓어지는 것이죠.
그 아래 m mask는 가운데 포인트를 기준으로 양옆에 한 포인트씩을 추가하여 살려주는 마스크라 보면 됩니다. 핵심은 이전에 했던 M masking 보다 더 작은 mask로 진행한다는 것입니다.
그리고 두 결과의 차이를 가지고 우리는 Hard Background라고 부르는 것이죠.
사실 저렇게 해서 어떠한 point를 찾는 과정까지는 이해를 하였지만 저것이 어떻게 Hard Action이고 Hard Background인지 의미를 부여하는 것인지는 아직 의문입니다.
Easy Snippet Mining
Easy Snippet은 feature의 표현력이 분명해서 score가 아주 높거나 아주 낮을 애들이라고 볼 수 있습니다. 그렇다면 우리의 T-CAS에서 Top-k에 해당하는 snippet들은 Easy Action Snippet이라 볼 수 있고 bottom-k에 해당하는 snippet들은 Easy Background Snippet이라 볼 수 있습니다.
이때 아까 정의했던 Hard Snippet 구간은 제외하고 선택한다고 보면 됩니다. 몇 개의 k를 선택할지는 hyperparameter라고 합니다.
Network Training
W-TAL에서의 학습 과정은 보통 Classification Loss + Additional Loss로 구성이 됩니다. Classification Loss가 등장하는 이유는 우리가 가지고 있는 Label이 비디오에 어떤 Action Category가 존재하는지 나타내는 Action Category Label이 존재하기 때문에 기본적으로 이를 사용하는 것이고 일반적으로 Classification Loss만을 이용해서 학습을 하면 성능이 떨어지기 때문에 논문마다 추가적인 Loss를 제안합니다.
- Action Loss
Video Level의 Action Category를 예측하기 위해서는 Video-level score가 필요할 것 같습니다. 그렇다면 이것은 어떻게 만들 수 있을까요? 우선 T-CAS에서 각 Class별로 top-k개의 Snippet을 선택합니다. 그 Class를 책임지는 대표 Snippet을 선택한 다음 score를 평균 내줍니다. 이렇게 class 별로 top-k mean pooling을 거치면 class 마다 하나의 score를 얻을 수 있고 class 별로 모두 모아주면 video-level score vector를 얻을 수 있습니다.
그리고 나면 cross entropy loss를 통해서 최적화를 할 수 있을 것 같습니다.
- La=−1N∑Nn=1∑Cc=1ˆyn;clog(pn;c)
여기서 N은 batch size라 보면 됩니다.
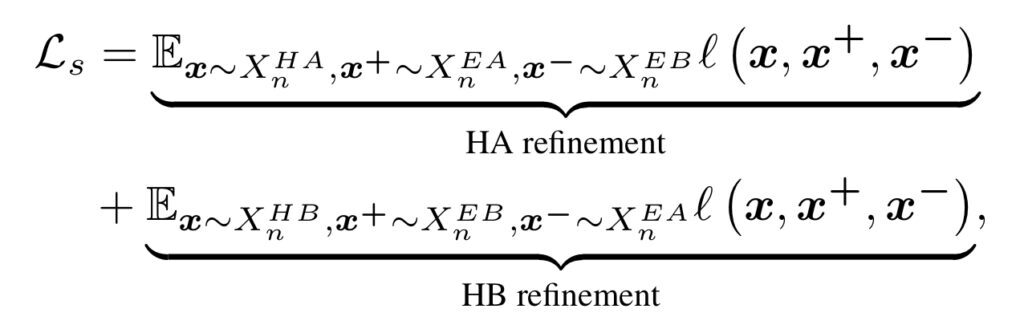
- Snippet Contrast (SniCo) Loss
SniCo Loss의 목적은 다시 얘기하지만 Hard Action은 Easy Action과 Representation이 비슷해지고 Easy Background와 멀어도록 또한 반대로 Hard Background는 Easy Background와 Representation이 비슷해지고 Easy Action과 멀어지는 Representation Learning을 할 수 있게 만드는 것에 있습니다.
"We project them to a normalized unit sphere to prevent the space from collapsing or expanding"
Contrastive Learning을 할 때는 Feature들을 길이가 1인 unit vector로 정규화를 시키는 것 같습니다. 처음 알게 된 사실이지만 이렇게 정규화를 시켜주면 embedding space가 unit sphere로 형성이 된다고 하네요.
Contrastive Learning에서 가장 흔하게 사용하는 InfoNCE Loss를 사용했습니다. 그리고 Hard Action Refinement와 Hard Background Refinement를 둘 다 고려했습니다. 무슨 말이냐면 Hard Action 입장에서의 InfoNCE Loss도 사용했고 Hard Background 입장에서의 InfoNCE Loss도 사용했다고 보면 됩니다.
- l(x,x+,x−)=−log[exp(xT⋅x+/τ)exp(xT⋅x+/τ)+∑Ss=1exp(xT⋅x−s/τ)]
다시 정리해보면 Hard Action 입장에서 Positive pair는 Easy Action이고 Negative pair는 Easy Background입니다.
그리고 Hard Background 입장에서 Positive pair는 Easy Background이고 Negative pair는 Easy Action입니다.
그래서 최종 SniCo Loss는 아래와 같습니다.
Inference
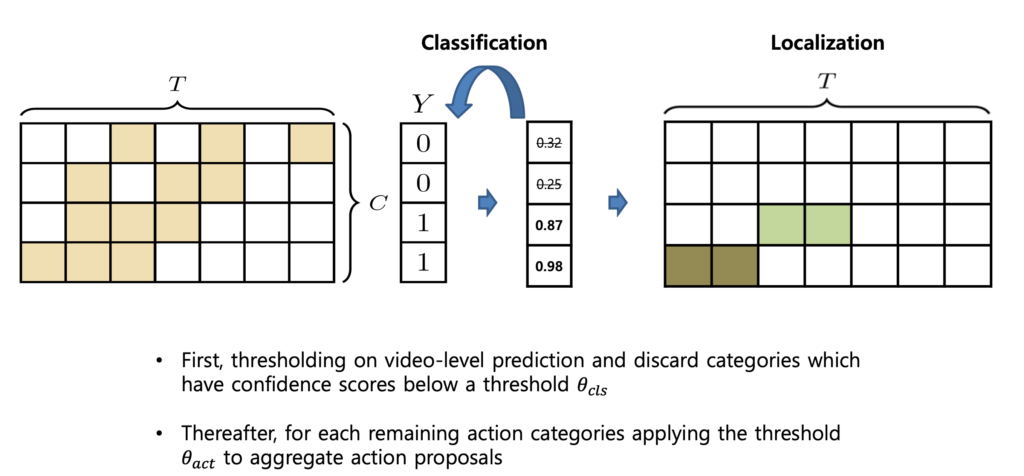
W-TAL에서 Inference는 크게 세 단계로 나눌 수 있습니다.
- CAS에서 Video-level score vector를 만들고 Video-level thresholding을 진행합니다. 즉, 일정 threshold 이하의 action category에 해당하는 CAS는 사용하지 않는다는 것이죠 아래의 그림을 보면 0번째, 1번째 Class는 제거가 된 모습입니다.
- 그다음으로는 Snippet level thresholding을 진행합니다. Video-level thresholding을 거치고 살아남은 Class에 대한 CAS를 살펴봤을 때 score가 높은 snippet들을 살려두고 grouping 해서 proposal을 만드는 것이죠.
- 이렇게 해서 만들어진 proposal 들에 대해서 Non-Maximum Suppression을 통한 후처리를 해준다면 Inference의 과정은 모두 끝이 나게 됩니다.
Experiments
Dataset
THUMOS14 dataset : 원래는 101가지의 action class를 가지는 데이터셋이지만 그중 20개의 class에 대해서만 temporal annotation을 제공합니다. 200개의 validation video로 학습을 진행하고 213개의 test video로 평가를 한다고 합니다. 200개의 비디오만 사용한다고 해서 task의 난이도가 쉬운 것은 아닙니다. 왜냐하면 비디오의 길이가 평균 4분 정도이기 때문이죠. 또한 action의 영역이 굉장히 sparse 하기 때문에 action과 background 간의 imbalance가 조금 심한 데이터셋입니다.
ActivityNet dataset : 200가지의 action class를 가지고 있는 데이터셋으로 temporal action localization benchmark를 위해 등장한 데이터셋입니다. 평소에는 test data에 대해서 평가를 할 수 없고 activitynet challenge 기간에만 평가 서버가 열려서 test data에 대해서 평가할 수 있습니다. 이러한 제한적인 상황 때문에 보통 연구를 할 때는 10024개의 train 데이터로 학습하고 4926개의 validation 데이터로 평가를 진행하다고 합니다
comparison with State-of-the-Arts
일단 THUMOS'14에서의 벤치마킹입니다.
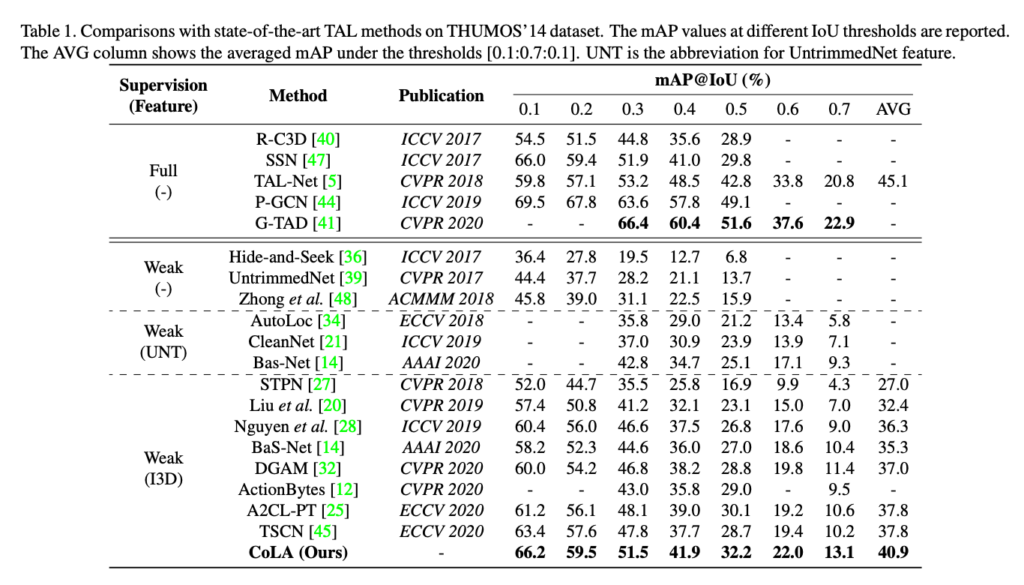
일단 Weakly Supervised 방식에서는 SOTA입니다. 저자는 그리고 몇몇 Fully Supervised와 비등한 수준의 성능을 달성했다고 주장하지만 2017년도의 성능은 따라잡은 것 같지만 18년부터는 아직 격차가 조금 나는 것으로 보입니다. W-TAL의 갈길은 멀지만 그만큼 challenging 한 task이니 날이 갈수록 더욱 연구가 활발해지길 기대하고 있습니다. ActivityNet에서도 동일한 경향성을 보여주기 때문에 따로 언급을 하지는 않겠습니다.
Ablation Studies
중요한 Ablation Study입니다.
일단 논문의 핵심이었던 SniCo Loss에 대한 Ablation Study입니다.

잠시 설명을 하면 baseline은 Classification Loss만을 사용해서 학습한 것을 의미합니다. SniCo Loss를 제외시키고 학습을 하면 mAP@0.5에서 7.5%의 성능 하락이 발생하네요. SniCo Loss를 통해 W-TAL에 적합한 feature distribution을 얻을 수 있었기 때문에 발생한 이득이라 볼 수 있겠습니다.
그 밑에 HB ref , HA ref는 Hard Background, Hard Action refinement를 의미합니다. 둘 다 하는 게 아니라 하나씩만 해도 되지 않냐라는 의문에 대답하기 위해 넣었다고 하네요. 결론적으로 둘 중 하나만 쓰면 성능 하락이 발생합니다. Hard Action과 Hard Background는 서로 다른 속성을 가지기 때문에 이러한 결과가 나온 게 아닌가 싶습니다.
그다음 ablation입니다. 본 논문의 저자는 Hard Snippet을 찾는 알고리즘을 제안했습니다. 그렇다면 그 알고리즘을 통해서 검출된 Hard Snippet들이 Non-trival 한지 의미가 있는 Snippet들인지 검증하는 것 역시 필요하겠죠.

이러한 분석을 하기 위해서는 Ground Truth를 참고해서 진행했습니다. 저자가 주장하는 Hard Snippet 부분은 action의 경계 부분입니다. 예를 들어 action이 5초 ~ 10초라면 4~5초 , 10~11초 이렇게 생각할 수 있습니다.
그래서 검출된 Hard sample이 저러한 경계 부근에 위치하면 잘 검출이 된 것이고 그것이 아니라면 상대적인 거리를 측정하는 식으로 Hard Snippet의 검출 오류를 측정했다고 합니다. 사실 이렇게 하는 것이 정말 맞는 방식이냐라고 물어본다면 조금 의문이 들지만 또 마땅한 방법이 생각나질 않으니 그냥 살펴봤습니다.
그래서 아래의 그래프를 보면 파란색이 학습을 시키지 않았을 때의 상대적인 오류 정도이고, 초록색이 2000 epoch 학습을 시켰을 때 상대적인 오류 정도입니다. x축은 error-prone region(Hard Snippet이 존재할 수 있는 구간)의 scale을 나타내는 축입니다. scale이 작을수록 더욱더 tight 하게 오차를 측정한다고 보면 됩니다. 0.2 scale에 대해서 3.7%의 오차를 보여준다고 합니다.
적어도 저자가 주장했던 경계 부근의 Hard Snippet에 한해서는 그래도 꽤나 잘 검출을 한다고 볼 수 있겠네요.
Qualitative Results
마지막으로 정성적 결과입니다.
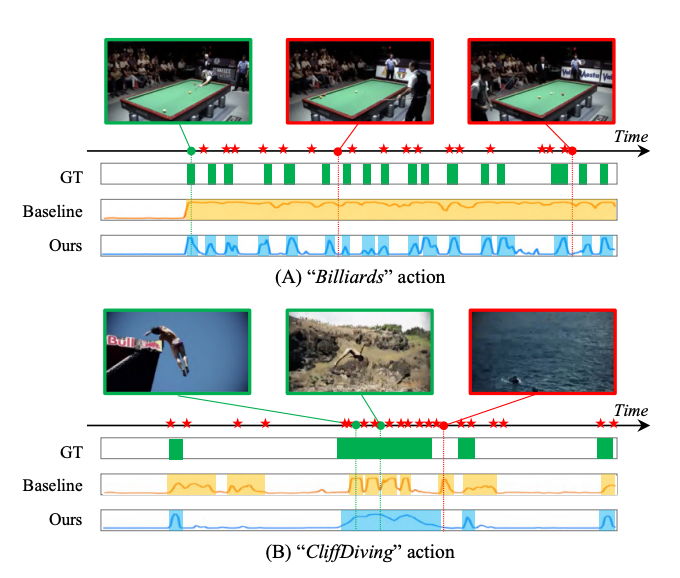
결과 (A)는 비디오의 모든 장면이 비슷한 콘텐츠를 공유하는 부분입니다. 게다가 GT도 굉장히 부분 부분 나뉘어 있어 상당히 어려운 편에 속하는 케이스입니다. 그럼에도 CoLA는 잘 찾는다고 이렇게 보여주고 있습니다.
결과 (B)는 다양한 카메라 뷰를 가지고 있는 동영상입니다. 이런 경우 역시 어려운 편이라 볼 수 있습니다. 역시나 잘 찾네요.
저자가 보여주는 정성적 결과에서는 인상 깊은 게 하나 있는데 바로 저기 시간축에 빨간색 별 표시를 이용해서 CoLa가 찾아낸 Hard Snippet 구간을 표시했다는 것입니다.
(A)에서는 GT의 boundary 쪽을 모두 Hard Snippet으로 간주하고 있는 것을 보여주고 있습니다. 꽤나 흥미롭군요.
Conclusion
팽창과 침식이라는 고전적인 영상 처리 기법에서 아이디어를 얻어 효율적인 Hard Snippet Mining 방식을 제안한 것이 인상 깊은 논문이었습니다.
이상으로 리뷰 마치도록 하겠습니다.



