Before Review
오늘은 꽤 인상 깊게 읽었지만 또 한편으로는 아쉬웠던 논문을 가져왔습니다. 지금 진행 중인 연구 과제에서 나아가야 할 방향에 대한 Insight를 주는 Paper이지만 , 코드 공개가 되어 있지 않아서 살짝 아쉬웠던 논문입니다.
아무튼 각설하고 분야는 Action Segmentation이라고 해서 , Video의 Frame 별로 무슨 Action인지 분류하는 Task입니다. 최근 들어 Unsupervised 혹은 Self-Supervised 기반의 접근 방법론을 찾아보다 같은 랩실 동료의 추천으로 읽어보게 되었습니다. 본 논문은 Clustering을 기반으로 Action Segmentation을 해결하려는 접근 방법을 취해주고 있습니다.
따라서 본격적인 얘기를 진행하기 전에 K-Means Clustering과 FINCH라고 불리우는 Hierarchical Clustering 방법론을 먼저 살펴보고 가도록 하겠습니다.
Preliminaries
K-means
Clustering 방법론으로 아마 대부분 아실 거라고 생각합니다. K 개의 Centroid를 임의로 생성하고 , 생성된 Centroid를 기반으로 모든 데이터에 군집을 할당해줍니다. 이때 군집은 가장 가까이 있는 중심에 속하게 됩니다. 모든 데이터에 군집이 할당되면 다시 각 군집의 Centroid를 다시 계산해주고 위의 과정을 반복하다가 Centroid가 변하지 않을 때 멈추게 됩니다.
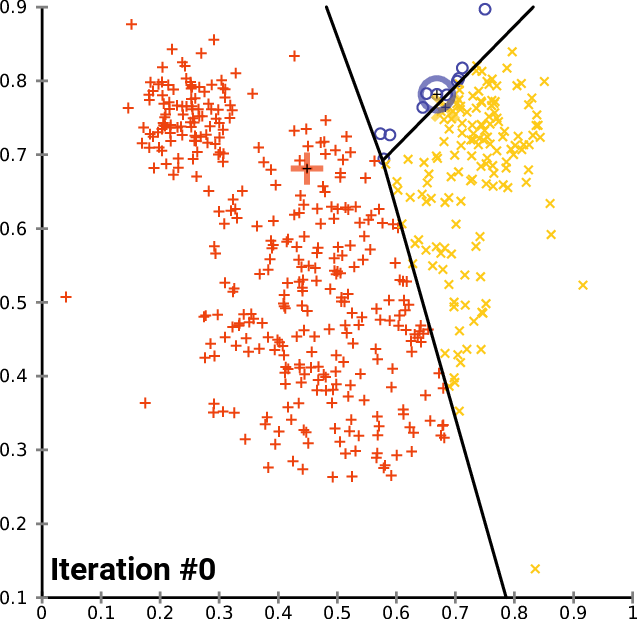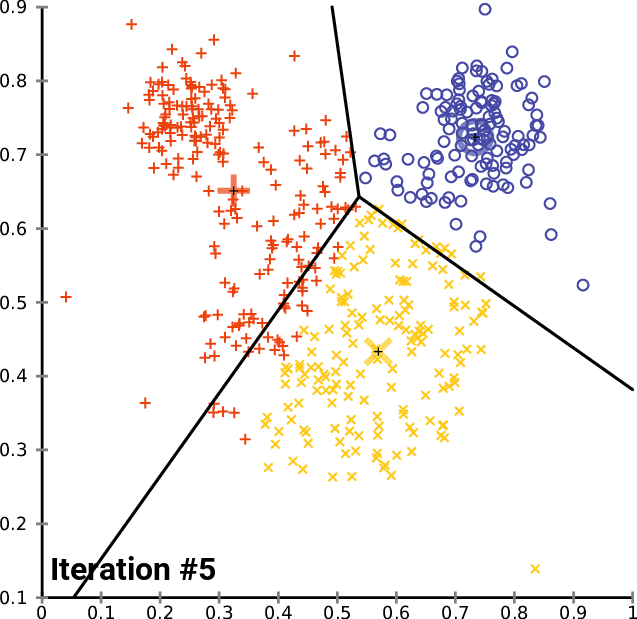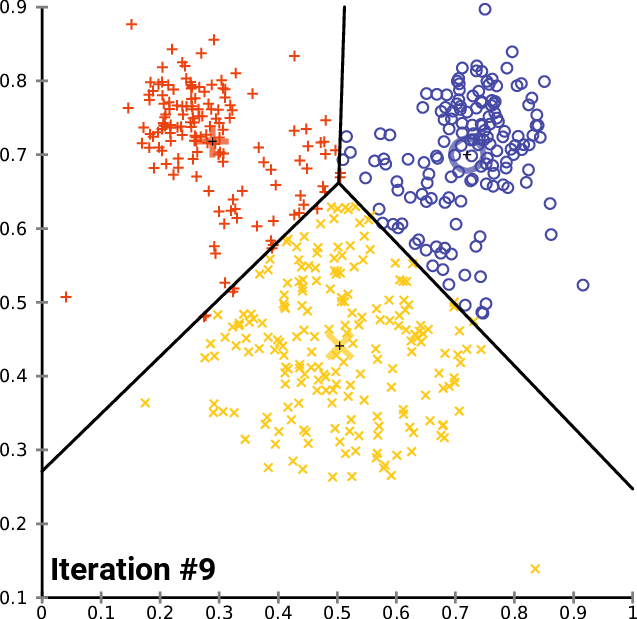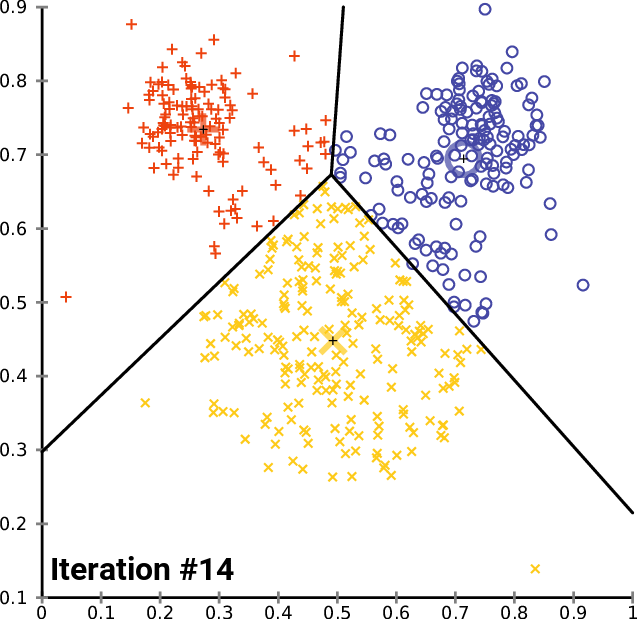
K-Means Clustering은 분리형 군집화 알고리즘에 속하며 사전에 군집의 수 K가 정해져야 알고리즘이 수행 가능합니다. 단점으로는 서로 다른 크기의 군집을 잘 찾아내지 못하며 , 서로 다른 밀도의 군집을 잘 찾아내지 못합니다. 또한 지역적 패턴이 존재하는 군집은 이게 거리를 바탕으로 계산을 하는 구조이다 보니 판별하는 데에 있어 한계를 가지게 됩니다. K-Means를 알아봤으니 다음으로는 계층적 군집화 알고리즘에 해당하는 FINCH를 알아보도록 하겠습니다.
FINCH
본 논문에서 사용할 핵심적인 Method 입니다. 2019년에 Efficient Parameter-free Clustering Using First Neighbor Relations CVPR에 발표된 논문에서 제안된 Clustering 방법론입니다. 본 논문에서 제안된 방법론도 이 FINCH를 기반으로 서술하고 있기 때문에 이 알고리즘을 우선 간단하게 알아보고 가도록 하겠습니다.
제안된 Background는 이러합니다. Clustering은 일반적으로 Data point들 간의 거리를 해석하여 data 들의 group을 찾아내는 것을 의미합니다. 이 과정에서 고차원 공간에 분포하는 data 간의 거리를 단순히 이용하는 것보다는 좀 더 semantic 한 relation을 이용하자가 FINCH의 아이디어입니다. 데이터 point에서 누구랑 가장 가까운지만 알고 있는 것만으로도 충분한 통계치를 얻을 수 있다고 합니다.
이러한 접근을 사용하면 Hyperparameter(distance threshold , number of clusters) 설정도 필요 없다고 합니다. 간단하게 그림을 먼저 살펴보도록 하겠습니다.

태양계의 행성을 예시로 FINCH 알고리즘을 설명하고 있는 데 , 각 행성별로(feature 별로) 어느 행성이 가장 가까운지 먼저 계산해준 다음에 이를 가지고 인접 행렬(그래프)을 만들어줍니다. 그래프를 다 만들고 났을 때 만들어지는 순환 경로가 하나의 군집을 의미하게 됩니다. 위의 사진으로 봤을 때는 3개의 군집이 만들어지네요.
이제 이렇게 만들어진 개별적인 Cluster들을 재귀적인 방법으로 계층적으로 병합 시켜주게 됩니다. Cluster들을 Merge 하는 부분은 이따 TW-FINCH에서도 동일하게 적용이 되기 때문에 그때 알아보는 것으로 하고 결국 FINCH 알고리즘은 가장 최근 접한 feature들끼리의 relation을 바탕으로 Grouping을 수행한다 라고 이해하시면 될 거 같습니다.
Introduction
그럼 이제 슬슬 논문 얘기를 해보도록 하겠습니다. Video에 있어서 인간의 행동(Action)을 Fine-grained level로 이해하는 것은 어렵지만 , 당연히 더 깊은 Video understanding 위해서는 해결해야 하는 문제이기도 합니다. Video에 대한 정보를 Frame 별로 해석할 수 있다면 더욱 응용할 수 있는 분야가 많이 있을 것입니다. 이에 따라서 Fine-Grained Level이지만 제약조건이 많지 않은 접근 방법 즉 , Annotation에 의존하지 않는 방법들이 활발하게 연구되고 있고 본 논문도 그러한 목표를 가지고 제안되었습니다.
Action Segmentation이 바로 위의 문제에 해당하는 연구분야가 되는 데 당연히 어려운 점이 존재합니다. Frame level로 무슨 Action인지 구분하기 위해서는 상당한 Annotation을 요구로 합니다. 설령 Supervised가 아닌 Weakly-Supervised 방식이라 해도 역시 적지 않은 인간의 개입이 필요한 상황입니다.
본 논문의 저자는 Fine-Grained Level의 Video Understanding Task를 다루면서 완전한 Unsupervised 방식의 방법을 제안했습니다. 핵심은 action segmentation 문제를 grouping 문제로 인식하는 것입니다. 결국 , Action간의 temporal boundaries 효과적으로 구분해주는 Clustering Method 고려해보자 라는 것이 저자의 아이디어입니다.
간단하게 설명을 드리자면 , Frame level의 Feature를 받아와서 Cluster들을 만들어줄 때 단순히 feature space내에서 feature들 간의 distance만 고려하는 것이 아니라 , time-space에서의 distance를 기반으로 Weight를 주어서 Feature들 간의 Temporal coherence까지 고려한 Clustering 알고리즘을 설계한 것입니다. 본 논문에서 제안하는 TW-FINCH라고 하는 알고리즘은 FINCH 알고리즘을 기반으로 조금 더 action segmentation에 적합하게 수정한 알고리즘이라 보시면 됩니다.
Temporally Weighted FINCH(TW-FINCH)
앞서 말씀드렸지만 , 본 논문의 저자는 Action Segmentation 문제를 Unsupervised 방식으로 해결하기 위해 Grouping(Clustering) 관점으로 바라보고 있습니다. 상대적으로 좋은 video frame representation(feature나 descriptor)이 존재한다면 , Grouping을 할 때 Action 끼리의 경계를 잘 구별할 수 있다고 합니다. 본 주장에 힘을 실기 위해 간단한 실험 결과를 보여주고 있는 데
- K-Means representing centroid-based methods
- FINCH representing hierarchical agglomerative clustering methods

Frame Feature는 64-dim IDT Feature를 사용했다고 합니다. 단순한 clustering baseline인 Kmeans/FINCH 알고리즘이 Weakly Supervised 혹은 Unsupervised 알고리즘과 비슷한 성능을 보여주고 있습니다. 본 논문의 저자는 이러한 observation에 힘 입어 action segmentation에 더욱 효과적인 알고리즘을 제안하게 됩니다.

위의 그림은 제안된 TW-FINCH를 통해서 Segmentation 결과가 GT와 거의 동일하다는 정성적 결과를 보여주고 있습니다. 자 그럼 이제 TW-FINCH는 어떻게 설계가 된 건지 알아보도록 하겠습니다.
비디오가 N개의 frame으로 구성이 되어 있을 때 , N개의 Frame feature를 가지고 방향 그래프를 만들게 됩니다.
두 가지의 방향 그래프를 정의해주게 되는 데 1) feature-space , 2) time-space 간의 그래프를 정의하게 됩니다.
Feature-Space상에서 distance를 나타내는 Graph(인접 행렬)를 정의해줍니다. 여기서 $<x_{i}, x_{j}>$ feature vector들을 normalize 시킨 후에 inner product를 진행한 것입니다. 결국 저 그래프 자체는 feature-space 상에서의 거리를 나타내고 있다고 보시면 되겠습니다.
- $G_{f}(i,j)=\begin{cases}1&i=j\\ 1-<x_{i},x_{j}>&else\end{cases} $
다음으로는 Time-space 상에서 weight를 부여하는 Graph입니다. N개의 frame에 대해서 time-stamp라는 것을 정의해주는 데 간단하게 $T=\{ 1,2,\cdots ,N\} $ 이렇게 프레임 인덱스를 가지고 정의해주고 있습니다. 그래프가 아래와 같이 정의가 되면 frame 끼리 시간적으로 멀리 떨어져 있다면 weight가 클 것이고 , 시간적으로 근처에 있다면 weight가 작게 부여가 되는 구조입니다. 이 weight가 나중에 distance에 고려가 되는 상황이라 , 근처에 있을 수록 거리가 가까워지는 feature를 유사하게 보겠다는 그런 의도라 보시면 될 거 같습니다.
- $G_{t}(i,j)=\begin{cases}1&i=j\\ \frac{\mid t_{i}-t_{j}\mid }{N} &else\end{cases} $
이제 이 두 그래프를 합쳐주게 되는 데 여기서 애매한 부분이 있습니다. 일단 수식은 아래와 같습니다.
- $W(i,j)=G_{f}(i,j)\cdot G_{t}(i,j)$ 이때 두 행렬을 matrix 곱을 해준다는 건지 , element-wise product을 해주는 건지 나와있지가 않아서 조금 혼란스러웠습니다. 아마 element-wise product으로 해주는 것이 흐름상으론 자연스러운 것 같아 그렇게 가정하고 진행하겠습니다.
무튼 이렇게 두 인접 행렬을 가지고 새로운 인접 행렬(그래프)을 얻을 수 있게 됐고 , 이 그래프는 frame 간의 feature-sapce 간의 거리와 time-space 간의 거리를 모두 고려해준 temporally weighted graph라고 볼 수 있습니다. 마지막으로 1-NN 그래프 즉 , 가장 가까운 frame만 남겨두는 작업을 진행해서 어떤 frame끼리 가장 가까운지 구해주게 됩니다. 참고로 당연히 이 그래프 G는 symmetric matrix입니다.
- $G(i,j)=\begin{cases}0&if:W(i,j)>\min_{\forall j} W(i,j)\\ 1&otherwise\end{cases} $
여기까지 해서 Temporal Weight가 적용된 1-NN 그래프를 정의해주었고 , 아직 Cluster를 만들기 위한 Graph Segmentation은 진행하지 않았습니다. 여기까지 진행했다면 First-Partition(Cluster)을 얻어준 것이고 이제 이 Cluster들을 재귀적으로 merge 해서 계층적인 Clustering이 진행됩니다.

제안된 알고리즘을 설명하는 의사 코드입니다. 차근차근 살펴보도록 하겠습니다.
- Input data는 Video feature들입니다. 각 frame별로 frame을 나타내는 descriptor가 input으로 들어간다고 보면 됩니다. 각 벡터의 차원은 d가 됩니다.
- Output data는 Partition들의 집합이라고 볼 수 있는 데 참고로 Partition은 Cluster들의 집합을 의미합니다. 여기 이 Partition 들은 계층적인 구조를 가지게 되므로 $P_{i}\subseteq P_{i+1}$으로 표현해주고 있습니다.
- Initialization은 첫 번째 Partition을 구해주는 과정으로 위에서 이미 설명을 드렸습니다. feature-space와 time-space를 모두 고려한 그래프를 얻어와서 가장 최근접 feature 끼리 매칭 시켜주는 1-NN 그래프를 구하게 되면 가장 소분류의 Partition을 얻을 수 있습니다.
- Partition Merge는 loop를 돌려서 진행이 되는 데 , 종료 조건은 Partition을 구성하는 Cluster의 개수가 하나가 될 때까지 진행하는 것입니다. 그 안에서 진행되는 작업은 Initialization 부분과 유사한데 , 예를 들어 첫 번째 Partition에 해당하는 Cluster의 개수가 10개가 되었다고 가정해보겠습니다. 이제 각 Cluster 내부에 모든 feature vector들을 평균 내서 Cluster를 대표하는 averaged feature들을 추출해주게 됩니다. 동일하게 각 Cluster 내부에 모든 feature vector들의 time-stamp를 평균 내서 Cluster를 대표하는 averaged time-stamp를 추출해주게 됩니다. 그럼 이제 이 10개의 Cluster들을 대표하는 feature vector와 time-stamp를 가지고 동일하게 1-NN temporally weighted graph $G_{M}$을 얻을 수 있습니다. Cluster들을 averaging 한 feature들과 time-stamp로 만들어준 Graph를 가지고 동일하게 Cluster 들을 구분할 수 있게 됩니다. 10개의 Cluster들이 다시 3개의 Cluster들로 3개의 Cluster들이 2개로 그리고 1개로 Merge 되면 Loop가 종료되며 Clustering이 종료가 됩니다.(10개 , 3개 이 숫자들은 이해를 돕기 위한 예시입니다.)
한 가지 고민을 해봐야 하는 부분이 뒤에서도 다시 한번 언급을 하지만 , time-stamp를 평균 낸다는 것은 결국 그 Cluster에 속하는 Feature들이 나타날 평균 시간대를 의미합니다. 평균이 어찌 보면 temporal 한 consistency를 부여해줄 수 있지만 , 이런 상황에서는 강인하지 못합니다.
같은 Action이지만 , 비디오의 시작과 끝에 존재하는 비디오라면 time-stamp가 확연하게 차이 나기 때문에 이러한 방식은 나름의 문제점을 가질 수 있습니다.
자 그럼 Temporally weight가 적용된 Hierarchy Clustering 알고리즘은 알아보았고 이를 가지고 Action Segmentation은 어떻게 진행이 되는지 알아보도록 하겠습니다. 사실 이 부분이 제일 궁금했는 데 저렇게 의사 코드만 딱 나와있어서 이해가 잘 되질 않았습니다.

- Input data로는 action 개수 K , N개의 frame feature , 위에서 만들어준 Partition set들입니다.
- Output data로는 K개의 Cluster를 담고 있는 Partition입니다.
- 종료 조건은 Partition 안에 K개의 Cluster만 남을 때까지 2개의 Cluster들을 Merge 시켜줍니다.
- Loop 구문에서는 무슨 작업이 진행되냐면 , input feature를 사전에 정의해준 Partition에 따라 각 Cluster에 할당시켜 준 뒤 아까와 마찬가지로 Cluster를 대표하는 averaged feature , averaged time-stamp를 계산해줍니다. 동일하게 temporally-weighted 1-NN Graph를 만들어주고 여기서 딱 두 개의 Cluster만을 연결시켜주는 데 어떻게 진행하냐면 $W(i,j)=G_{f}(i,j)\cdot G_{t}(i,j)$ 여기서 계산되는 distance가 가장 작은 matching 쌍만 남겨두고 다른 값들은 다 0으로 처리해버립니다. 즉 , temporally weight distance가 가장 적었던 두 Cluster들을 Merge 해준 뒤 위의 과정이 반복됩니다. 그러다가 Cluster의 개수가 K개가 되며 종료가 됩니다.
의사 코드에 대한 설명이 아예 없어서 이 정도로 밖에 설명을 못 드릴 것 같습니다. 사실 정확히 어떻게 Action Segmentation 작업이 이루어지는지는 아직 감이 안 잡히는 것 같습니다. 추후에 더 깨달은 부분이 있다면 설명을 추가해서 올려놓도록 하겠습니다.
Experiments
Dataset
Temporal Action Segmentation 분야에서 자주 사용되는 다섯 가지 dataset을 사용했다고 합니다.
- Breakfast(BF) , Inria Instructional Videos(YTI) , 50 Salads (FS) , MPII Cooking 2(MPII) , Holywood Extended(HE)
이 다섯 가지 데이터는 다양한 action을 포함하고 있으며 다양한 길이의 비디오 또한 포함하고 있습니다.
Features
사실 여기 나오는 Feature들에 대해서는 잘 몰라서 자세히 설명을 드리긴 힘들 거 같습니다. 우선 관련 논문 링크를 첨부할 테니 필요하신 분들을 참고하시면 좋을 것 같습니다.
- Improved Dense Trajectory feature(IDT)
- Set constrained temporal transformer(SCT)
- Continuous Temporal Embedding(CTE)
- HOF + VGG16(conv5)
Action Recognition 진영에서 제안된 Feature들도 있고 , Action Segmentation 진영에서 제안된 Feature들도 있습니다. 위의 Feature를 고른 이유는 다른 방법론들과 fair comparison을 위해 동일한 Feature를 사용한 것뿐이라고 합니다.
Performance
결론적으로 말씀드리면 5개 데이터셋에 대해서 K-means , FINCH baseline보다 월등한 성능을 보여주며 , 다른 Weakly Supervised 기반의 방법론들의 성능을 가뿐히 뛰어넘는 성능을 보여주고 있습니다.
성능 테이블은 정말 다 하나같이 SOTA를 달성하고 있어서 , 단순히 보여 드리는 것은 의미가 없는 것 같고 성능 적인 부분 말고 추가적인 얘기를 하나만 말씀드리면 이 TW-FINCH가 데이터셋에 Background가 많을 때 성능 하락 폭이 다른 알고리즘에 비해 적다는 얘기를 저자가 하고 있습니다.
아마도 Training 기반의 알고리즘들은 Background 비율이 많은 데이터로 학습하다 보면 overfitting이 일어나 성능 하락폭이 큰 반면 TW-FINCH는 이러한 상황에서도 나름 덜 영향을 받는 다고 합니다.
다른 방법론들과 비교한 정성적 결과입니다.
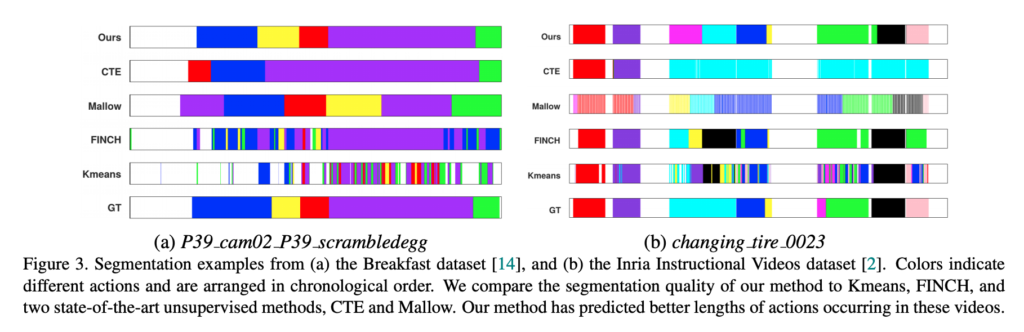
Kmeans나 FINCH와 비교해보았을 때도 더 좋은 결과를 보여주며 다른 알고리즘에 비해서도 더 좋은 성능을 보여주고 있습니다.
Limitation
본 논문의 저자가 밝히는 두 가지의 한계점이 있습니다.
- 낮은 Visual coherence로 인해 연속적인 temporal sequence들을 과도하게 분할할 때 같은 Action을 다른 Cluster에 할당되게 됩니다. 이는 결국 Frame Feature가 얼마나 Visual 정보를 효과적으로 표현하는지에 달려 있는 것 같습니다.
- 같은 action을 나타내는 frame을 시간적으로 거리가 멀 때 다른 action으로 분류하는 경향이 있습니다. 결국 , 비디오 내에 동일한 action이 초반에 나왔다가 어느 정도 시간이 흘렀을 때도 잘 구분을 해야 하는 데 , 이런 부분에 약하다는 의미입니다.
Conclusion
우선 , Deep Learning 기반의 접근이 아닌 , Machine Learning 기반의 Clustering 알고리즘을 가지고 Unsupervised 방식으로 굉장히 좋은 성능을 보여주는 방법론이 나온 것 같습니다. 어떠한 Training도 필요하지 않고 , Annotation도 필요하지 않은 점을 미루어 보았을 때 비디오 관련 많은 DownStream Task에 접목이 가능할 것 같습니다.
code가 공개되지 않아 정말 아쉬운데 , 아이디어 자체는 ETRI 과제에 접목시킬 만한 포인트가 있어서 Pseudo-Code를 가지고 구현을 해봐야 하나.. 고민이 듭니다. 논문을 이해하는 데는 꽤 어려움이 있었지만 , 좋은 Insight를 얻을 수 있었던 Paper 였던 것 같습니다.
리뷰 읽어주셔서 감사합니다.



