Before Review
이번 리뷰는 Temporal Action Proposal로 비디오 내에 어느 구간에 action이 발생하는지 , event가 발생하는지를 예측하는 Task입니다. 이 Temporal Action Proposal Task는 [CVPR 2021] Self Supervised Learning for Semi-Supervised Temporal Action Proposal 지난번 Review에서 다룬 적이 있습니다. 이번에 준비한 논문은 Supervised기반으로 진행이 되며 , 당시에는 SOTA를 달성했고 여전히 Temporal Action Proposal 진영에서 Baseline으로 활용되는 논문입니다.
리뷰 시작하도록 하겠습니다.
Introduction
Video 진영에서 Object Detection과 비슷한 Temporal Action Detection(Temporal Action Localization) 분야는 비디오 콘텐츠 시장의 발달로 인해 산업계에서나 , 학계에서 많은 관심을 받고 있는 상황입니다. Temporal Action Detection은 Untrimmed Video 내부에 어느 구간에 Action이 존재하며 , 그 Action의 종류는 무엇인지 맞추는 작업입니다.
이 Temporal Action Detection이라고 하는 것이 결국에는 두 가지로 나뉘게 되는데 1) Temporal action proposal generation , 2) action classification 이중에서 action classification은 사실 Action Recognition 진영 쪽에서 이미 연구가 많이 이루어져서 어느 정도 가닥이 잡힌 상황이긴 합니다. 즉 , Temporal action detection의 퀄리티를 좌우하는 것은 Temporal Action Proposal 부분입니다.
이 Temporal Action Proposal Task는 사실 다른 비디오 Task에도 접목이 가능합니다. 그 이유는 Untrimmed Video에는 사실 무수히 많은 Background Frame이 존재합니다. 사실 이 Background frame은 데이터셋마다 다르게 정의가 될 순 있지만 공통적으로 해당하는 부분이 있습니다.
- 아무런 Visual 정보를 포함하지 않는 부분
정말 Background 의미와 맞아떨어지게 , 아무런 정보가 없는 Frame들도 Video data에는 적지 않게 존재합니다. 단순히 Visual 정보만을 이용해 Video Task를 진행하는 입장에선 이러한 Frame들은 불필요한 정보에 해당합니다.

- 사람의 인위적인 영상 편집이 들어간 부분

비디오 내부에 존재하는 어떤 장면과 장면을 이어 붙이기 위해서 , 영상편집 기법이 들어가게 됩니다. Dissolve , fade-in/out , wipe 등등의 soft 한 장면 전환 기법이 자주 등장하는 데 , 사실 이렇게 편집된 frame 역시 좋지 못한 Visual Information을 가지게 되므로 불필요한 정보에 해당합니다.
본 논문에서 소개할 Temporal Action Proposal 작업들이 저러한 Background Frame을 필터링해주는 데 좋은 역할을 할 수 있습니다. 때문에 Temporal Action Proposal은 video recommendation , video highlight detection , smart surveillance 등 많은 application에 사용될 수 있습니다.
본 논문에서 제안하는 BMN이라고 하는 방법론은 기존의 Temporal Action Proposal의 main stream이었던 , bottom-up 방식의 Proposal 방식에 한계점인 Proposal 자체가 정확하지 못하며 , 비디오의 dynamic 한 proposal 길이에 대응을 제대로 할 수 없다는 점을 언급하며 본인들의 새로운 framework를 제안합니다.
그렇다면 , 이 BMN이 어떤 메카니즘인지 이제 살펴보도록 하겠습니다.
Approach
Feature Encoding
대부분의 Proposal generation 방법론과 비슷하게 Raw video로부터 visual feature sequence를 추출합니다. 여기서는 two-stream network라고 해서 RGB-frame과 optical flow를 각각 Encoder에 태워서 나온 feature를 concat 하는 방식으로 visual feature sequence를 Encoding 해줍니다. Two-stream network를 이용해서 Video feature를 구해주는 건 사실 다른 논문들을 읽어봐도 대부분 동일한 방식을 취해주고 있습니다. 따라서 Feature를 처리하는 곳에서 별다른 부분은 없는 것 같습니다.
Boundary Matching Mechanism
저자가 주장하는 BMN의 핵심은 생성한 Proposal에 Confidence Score를 부여하는 과정에 있다고 합니다. 무슨 얘기인지는 찬찬히 알아보도록 하겠습니다.
먼저 Temporal proposal $\varphi $ 을 하나의 matching pair로 정의를 해줍니다. boudary의 starting point $t_{s}$ 와 ending point $t_{e}$의 pair로써 정의를 해준다는 의미입니다. 아래의 그림과 같이 BM mechanism의 목적은 BM confidence map $M_{C}$를 만들어내는 것입니다.

2차원의 Map으로 구성이 되는 데 Map의 원소들은 각각 Proposal의 Confidence score를 담아주고 있습니다. 위치에 따라 duration과 strat point가 달라지는 데 , 같은 Row에 위치했다면 Proposal에 위치는 같은 상태입니다. 같은 Column에 위치했다면 starting point가 같은 상태입니다.
- Boundary Matching Layer
그렇다면 저 BM confidence map은 어떻게 만들어내는 것일까요? 먼저 본 논문에서 제안하는 BM Layer를 통해 temporal feature sequence $S_{F}\in R^{C\times T}$를 BM feature map $M_{F}\in R^{C\times N\times D\times T}$으로 Encoding 해줍니다. Encoding 된 feature map을 가지고 연속적인 Convolution layer를 거쳐서 confidence map $M_{c}\in R^{D\times T}$를 얻을 수 있습니다.
confidence map에 대한 자세한 얘기는 조금 뒤에 하도록 하겠습니다.
우선 처음에 temporal sequence feature를 받아와서 BM feature map으로 만들어주는 BM layer에 대해서 좀 더 얘기를 해보자면 , $S_{F}$에서 N개의 point를 각 feature의 길이마다 균일하게 sampling 하는 것입니다. 결국 어떤 proposal을 담당할 feature를 만들어준다고 생각하시면 됩니다. feature 하나당 이제 D*T 만큼의 duration과 , starting point를 다르게 부여해주는 데 D길이만큼의 duration에 variance를 준다고 보면 되고 , T길이만큼의 starting point를 다르게 부여한다고 보시면 됩니다.
그러면 그 작업은 어떻게 하느냐? Sampling mask를 가지고 진행한다고 합니다. 여기 나오는 Sampling mask는 데이터셋에 관계없이 고정된 값을 사용해주고 있어서 , 연산속도에 있어서 상당히 빠르다고 합니다.
sampling mask : $W\in R^{N\times T\times D\times T}$ 로 이 가중치 행렬을 처음에 구해줬던 temporal feature sequence에 곱해주면 BM feature map이 생성되는 것입니다.
따라서 sampling mask를 가지고 행렬 곱을 취해주면 BM feature map $S_{F}\odot W=M_{F}\in R^{C\times N\times D\times T}$ 을 구할 수 있습니다. 이렇게 만들어준 BM feature map은 풍부한 feature와 temporal context를 포함할뿐더러 , 적절 한 proposal를 탐지할 수 있는 potential이 있다고 합니다
- Boundary Matching label
BM Layer를 통과해서 나온 BM feature map을 연속적인 CNN layer를 통과시켜서 결국에는 confidence map이 나오는 데 , 이걸 가지고 어떻게 학습이 되는지 설명을 해보도록 하겠습니다. 결국 여기서 쓰이는 Label은 우리가 생성해준 Proposal(i, j) 이 다른 모든 ground_truth proposal과의 IoU를 계산한 뒤 그중 최댓값을 사용하게 됩니다. 결국 저 confidence score map에 들어가는 값을 높여주기 위해 BM Layer와 CNN Layer가 학습이 된다고 보시면 되겠습니다.
Boundary Matching Network
앞선 설명은 간략하게 BMN에서 사용하는 confidence map이 무엇인지 , BM feature map은 어떻게 뽑는지 말씀을 드렸습니다. 이제는 BMN의 세 가지 Module에 대해서 설명해보도록 하겠습니다.
- Base Module
Backbone Network라 보시면 됩니다. 비디오를 읽어와서 Sequence Feature를 만들어주고 만들어준 feature들을 남은 두 개의 Module에 공유해줍니다.
- Temporal Evaluation Module
여기서는 sequence 한 feature를 받아와서 각 Location에 대해서 이 Point가 starting point인지 , ending point인지 구분하는 확률 값을 반환해준다고 보시면 됩니다.
- Proposal Evaluation Module
여기서 이제 바로 아까 설명했던 BM confidence map을 생성하는 곳입니다. 앞서 설명드린 것처럼 , sequence 한 feature를 받아와서 먼저 BM Layer에 전달해주어서 BM feature map을 반환받고 이를 다시 CNN layer에 태워서 Confidence map을 만들어주고 있습니다.

Experiments
- Comparison with SOTA methods
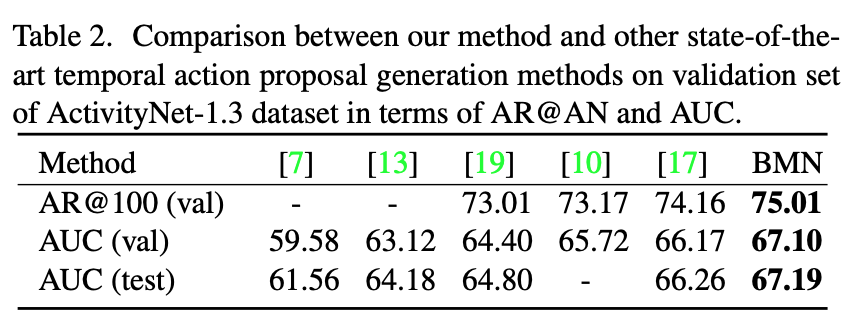
우선 Activitynet1.3에서의 성능입니다. 보시는 바와 같이 다른 방법론들 대비 SOTA의 성능을 달성하고 있습니다. 하지만 성능 향상의 폭은 그렇게 크지 않은 모양입니다.
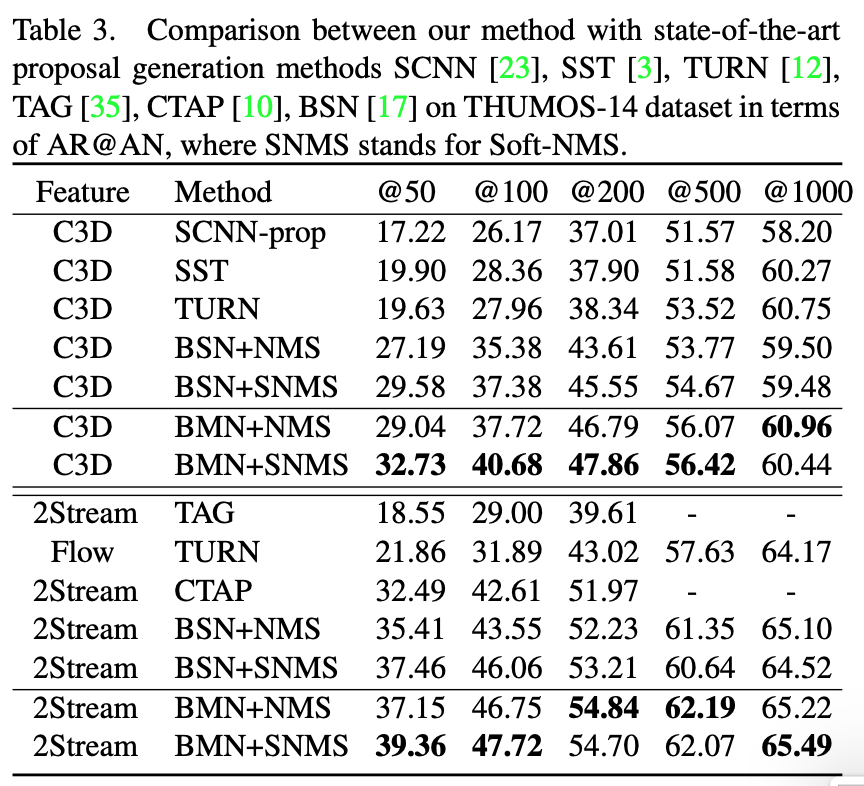
THUMOS14'에서의 성능입니다. 흥미로운 것은 sequence feature를 만들어줄 때 Backbone Network를 다르게 실험해도 가장 좋은 성능을 보여 준다는 점입니다. BMN의 framework가 잘 설계되었기에 backbone network에 관계없이 좋은 성능을 보여주고 있는 것 같습니다.
- Ablation Comparison with BSN
BMN이 나오기 전에 SOTA였던 BSN과 비교 분석을 진행하고 있습니다.

살펴봐야 하는 부분은 우선 , PEM 모듈을 추가했을 때 성능 향상을 확인할 수 있었습니다. 확실히 본 논문에서 제안된 TEM module을 통해 global 한 confidence를 고려하는 것이 효과가 있는 모양입니다.
또 하나는 BMN의 inference 속도가 BSN에 비해 약 10배 이상 차이 나게 빠르다는 점입니다.
마지막으로는 e2e 방식 즉 , TEM과 PEM을 따로따로 학습시킨 것이 아닌 , jointly 하게 학습시켰을 때 가장 좋은 성능을 보여주며 이는 BMN의 framework의 optimization이 전반적으로 잘 수행이 된다는 것을 의미합니다.
- Generalizabilty of Proposals
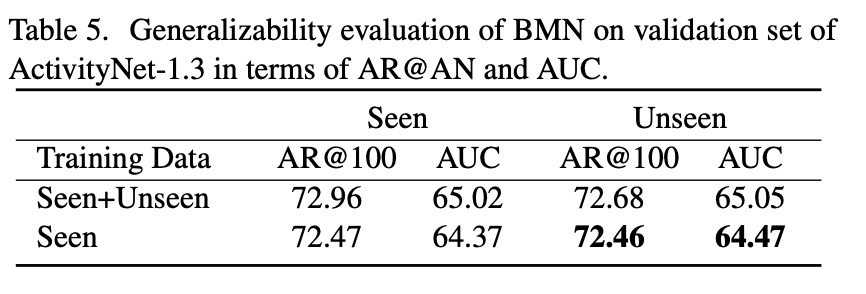
또 하나 흥미로운 것은 Temporal action proposal Task는 보지 못했던 Action에 대해서도 대략적인 Proposal을 할 줄 아는 것이 좋은 상황인데 , BMN이 그렇다는 것입니다.
사실 Action이라는 것이 Visual 하게 본다면 다르지만 Semantic 하게 본다면 비슷한 경우가 많습니다. 예를 들어 마라톤 달리기와 멀리 뛰기를 위한 달리기가 비슷한 것처럼 말입니다.
즉 Model이 학습하지 못한 Action이지만 , Action 자체에 대한 일반성을 잘 학습을 하였다면 비슷한 Action은 Proposal 할 수 있을 것입니다. 위의 테이블이 그러한 경우입니다. 우선 학습 데이터를 두 가지로 분할을 시킵니다. Seen Dataset , Unseen Dataset으로 나누고 , 둘 다 학습시켰을 때와 Seen dataset만 학습시켰을 때 과연 Unseen dataset에 대해서는 Inference를 어떻게 하는지 보여주고 있습니다. 결과는 Unseen dataset에 대해서 학습을 시키지 않아도 학습을 시켰을 때와 비슷한 Proposal을 만들어주고 있습니다.
이 결과는 나름 의미가 있는 것이 , 정말로 Action Proposal Task에서 Action이나 Event 자체가 가지는 일반성을 잘 학습할 수 있다면 우리는 비디오에 있는 확실한 Background를 Action Proposal Network로 필터링할 수 있게 된다는 의미입니다.
Conclusion
최근에 나오는 Temporal Action Proposal이나 Temporal Action Detection 논문들의 baseline으로 작용하는 BMN에 대해서 알아보았습니다.
사실 이 BMN framework에 TSP feature를 활용해서 Temporal Action Proposal을 직접 해보았는 데 , 정성적인 결과는 나름 만족스러웠습니다. 확실한 Background는 필터링이 되는 것 같았습니다.
이제 이 BMN 말고도 21년도에 나온 새로운 SOTA 논문들을 가지고도 한번 Proposal Task를 진행해봐야겠습니다.
리뷰 읽어 주셔서 감사합니다!



