Before Review
이번 논문 리뷰는 Semi-Supervised 형식의 Temporal Action Proposal 논문을 가져왔습니다. 현재 활동하고 있는 연구실에서 공부하고 있는 방향이
- Untrimmed Video를 가지고 ForeGround와 BackGround를 효과적으로 구분해내는 방법론
- labeling 된 Data가 아니더라도 , 위의 작업을 수행할 수 있는 Semi-supervised 혹은 self-supervised 방법론
이렇게 두 가지입니다. ForeGround를 구분해주는 작업은 보다 더 효과적인 정보들만 사용을 해주기 위함이고 , Supervised가 아닌 방식을 찾아보는 이유는 결국 비디오 데이터는 어노테이션의 과정에서 소요되는 자원이 너무 많기 때문에 , 필연적으로 Semi-Supervised나 , self-supervised 방향으로 가야 하는 것 같습니다.
그래서 이번에 준비한 논문은 Semi-Supervised와 Self-Supervised 기반의 Temporal Action Proposal 논문으로 , Labeled Data와 Unlabeled Data를 동시에 사용하면서 , 어느 구간이 Action인지 분류하는 방법론입니다.
기존의 fully-supervised 방법론이랑 , semi-supervised 방법론을 능가하는 성능을 보여주는 대단한 framework가 등장한 것 같습니다. Code도 공개가 되어있고 , 지금 찾아보려고 하는 방향이랑 일치하는 논문인 것 같아 , 실제 Code를 가지고 다양한 실험을 진행해보려고 합니다.
Introduction
Temporal Action proposal 방법론은 이전에 제가 다루었던 Temporal Action Localization 랑 비슷한 면이 있습니다. 조금 더 단순한 task를 진행하는 데 , Action(ForeGround)인 것 같은 구간을 Localization 하는 작업으로 Action의 Label이 무엇인지는 예측하지 않습니다.
위의 Task를 수행할 때 , Supervised 기반의 방식은 엄청난 양의 Annotation을 필요로 합니다. Frame Level로 이 Frame이 무슨 action인지 라벨링이 필요하며 , BackGround인 Frame도 따로 구분을 해주어야 합니다. 점점 미디어 콘텐츠 시장의 발달로 인해 Video Retrieval이나 , Temporal Action Localization 분야에 대한 필요성이 증가할 텐데 어노테이션 된 비디오 데이터셋은 그리 많지 않습니다. 그렇다고 필요할 때마다 어노테이션을 직접 하는 작업은 상당한 시간과 비용을 요구하는 일입니다.
따라서 Labeling 된 데이터 셋에 대한 의존도를 낮추는 것은 필연적인 흐름인 것 같습니다. 처음으로 Semi-Supervised 방식의 Temporal Action Proposal 방법론이 제안된 건 Learning Temporal Action Proposals With Fewer Labels 논문으로 2019년에 나왔다고 합니다. 저 논문을 읽어보진 않았지만 Mean Teacher Framework를 사용했다고합니다.
또 다른 패러다임은 Self-Supervised 방식입니다. 비디오 관련 task에서 나름의 성과가 있었지만 , Self-Supervised 방식이 Temporal Action Proposal에는 한 번도 적용이 되지 않았다고 합니다.
이에 본 논문의 저자는 본인들이 처음으로 Self-Supervised 방식과 Semi-Supervised 방식을 결합한 하나의 framework(SSTAP)를 제안했다고 합니다.
본 논문을 이해하기 전에 알아야 하는 몇 가지 개념들을 살펴보고 SSTAP에 대해 얘기해보도록 하겠습니다.
Preliminaries
여기서는 Semi-Supervised 기반의 방법인 Teacher-Student Frame work 가 무엇인지 알아보도록 하겠습니다.
Mean Teacher framework
Mean Teacher Framework에서는 student model과 teacher model이 존재하는 데 , 이 두 개의 model은 동일한 neural network로 구성이 되어 있습니다. student model은 labeled data를 통해서 구한 supervised loss 가지고 weight를 update 해주게 되고 , teacher model은 student model의 weight를 exponential moving average (EMA)를 취해서 weight를 update 해주는 데 수식은 아래와 같습니다.
θ(teacher)t=αθ(teacher)t−1+(1−α)θ(student)
student model의 weight를 재귀적으로 계산해서 , teacher model에 weight가 update 되고 , teacher model은 Unlabeled data를 받아와서 output을 만들어 냅니다. 이때 , Teacher model이 만들어 내는 output이 가능하다면 Student model이 만들어내는 output과 비슷하면 좋겠죠? 그래서 Teacher model과 student model이 얼마나 일관성이 있는지 , Consistency Loss를 통해서 이를 조정하게 됩니다.

여기서 , Student model은 Supervised Loss를 만들어내는 동시에 , Teacher model과 얼마나 일관성이 있는지 , Consistency Loss를 또한 만들어내서 Student model의 학습이 이루어집니다. 그 후 다시 EMA를 통해서 Teacher model이 update 되는 구조 이러한 과정이 반복되면서 결국 Teacher model은 unlabeld data를 가지고도 student model과 비슷한 output을 만들어내게 됩니다. 이러한 Framework가 SSTAP Semi-Supervised Branch에서 적용이 됩니다.
SSTAP
위의 그림이 SSTAP의 overview를 보여주는 그림입니다. Labeled Video와 Unlabeled Video를 둘 다 사용하고 있으며 Feature Encoding 과정을 거친 후에 2가지의 Branch로 나뉘고 있습니다.
위쪽 Branch는 Temporal-aware Semi-Supervised Branch로 Encoding 된 Feature를 가져와서 Temporal feature flip , Temporal feature shift라는 어떠한 변화를 가해준 뒤 Base Module이라는 곳에 입력으로 넣어준 뒤 , Mean-Teacher Framework를 통해 Output을 만들어내고 , Loss를 계산해주고 있습니다.
아래 Branch는 Relation-aware Self-Supervised Branch로 똑같이 Encoding 된 Feature를 가져오지만 여기서는 Labeling 되지 않은 Data만 사용해서 Feature를 얻어줍니다. 그 후에 Feature에 Random Masking , Feature Clip Shuffle라는 변화를 가해준 뒤 Base Module이라는 곳에 입력으로 넣어주고 최종적으로 Maksed feature Reconstruction , Clip order prediction이라는 Task를 수행하면서 Loss를 만들어냅니다.
간략하게 전체적인 흐름에 대해서 설명을 드렸고 , 두 개의 Branch내에서 Feature에다가 어떠한 perturbation을 가해주고 있습니다. perturbation이란 작은 변화를 가해 , 전체 시스템에 큰 영향을 초래하는 그러한 변화를 의미한다고 합니다. 자세한 이야기는 이어서 바로 하도록 하겠습니다.
그리고 Base Module은 아래와 같습니다. Boundary Matching Network(BMN)에서 사용한 BaseModule을 조금 더 확장해서 설계했다고 합니다.
자 그럼 이제 두 개의 Branch가 있다는 사실은 알았으니 , 각각의 Branch에서 무슨 일이 일어나는지 알아보도록 하겠습니다.
Problem Description & Feature Encoding
Input Data는 Untrimmed Video를 입력으로 받아옵니다. 본 논문의 목적은 Untrimmed Video 내부에 있는 Action Instance들의 위치를 비교적 적은 Annotation Label로 예측하는 것입니다. 다시 한번 얘기하지만 , Action의 Class는 신경 쓰지 않고 , Action의 구간만 예측하는 작업입니다.
Feature Encoding은 two-stream network 여기서 제안된 구조를 사용하여 , Feature를 추출했다고 합니다.
S={sn}lSn=1 Untrimmed Video sequence들이 이렇게 있을 때 각각의 Sequence들을 , 중첩되지 않게 σ개의 frame을 포함하도록 나누어줍니다.
그럼 각각의 Sequence는 T=lsσ T개의 sampling 된 Segment들을 가지게 됩니다.
이 Segment를 two-stream network에 넣어주면 , ϕ={ϕtn}Tn=1∈RT×C의 visual feature를 얻을 수 있게 됩니다. 여기서 C는 Encoding 된 feature의 차원이라 보시면 됩니다.
Temporal-aware Semi-Supervised Branch
위에서 잠깐 설명드린 것처럼 , 여기서는 Mean Teacher Framework를 가지고 진행이 됩니다. 이때 , Student Model에 들어가는 입력에는 Temporal feature shift , Temporal feature flip이라는 Perturbation이 적용되는 데 , 각각이 무엇인지는 그림으로 보면 더욱 이해가 쉬울 것 같습니다.
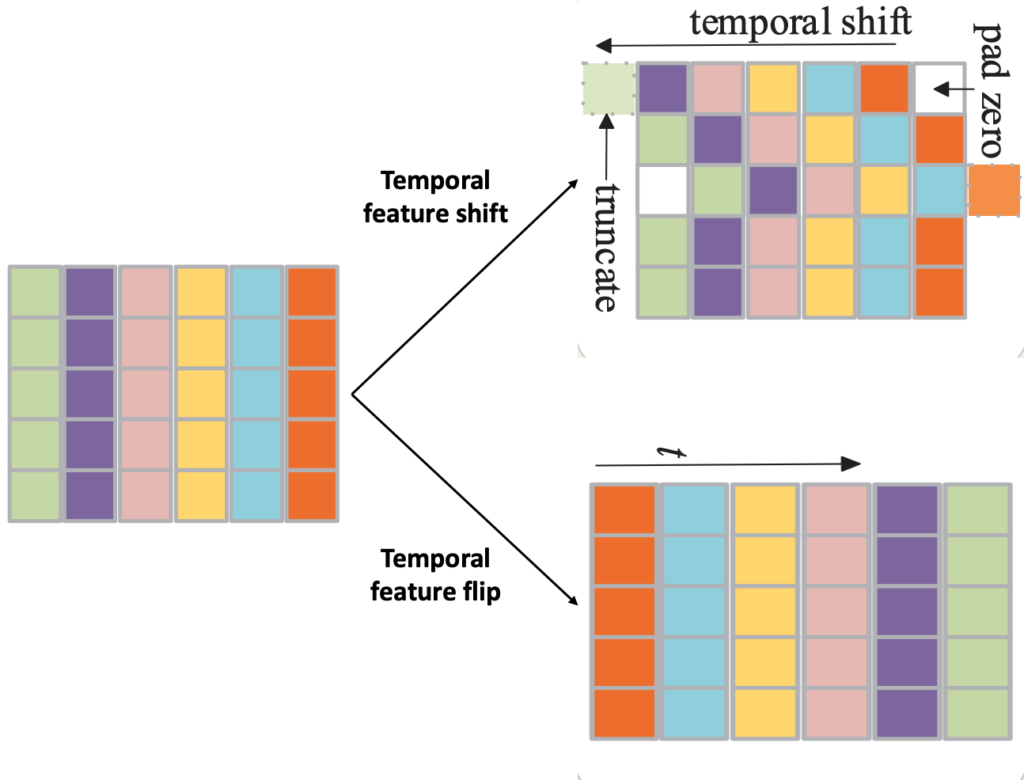
Temporal feature shift는 비디오 feature의 시간 축을 따라 랜덤 하게 몇몇 채널을 양방향으로 이동시키는 작업입니다. 비어지는 곳은 zero-padding을 진행해주고 , 넘어가는 곳은 그냥 버려줍니다. Temporal feature flip은 우리가 이미지 flip을 했던 것처럼 , feature를 flip 하는 것입니다.
이러한 작업이 저자는 Data Augmentation 느낌으로 좀 더 다양한 Feature를 제공하면서 , Temporal 축으로 Robust 한 학습을 도와준다고 합니다.
이제 , Loss는 어떻게 구하는지 살펴보면 , Labeled sample을 가지고는 Supervised Loss를 잘 정의할 수 있습니다. 하지만 Unlabeld sample에 대해서는 Supervised Loss를 구할 수 없으니 , consistency loss(L2-loss)를 가지고 처리를 해주게 됩니다. Consistency Loss는 Labeled data와 Unlabeld data 둘다에 적용이 되게 됩니다. Loss에 대해서는 자세한 설명을 하고 있지는 않아서 이 정도로만 얘기를 할 수 있을 것 같습니다.
Lsemi=Lsupervised+λ1Lshift+λ2Lflip 이고 이때 , Lshift와 Lflip은 consistency loss로 계산해준 것입니다.
Relation-aware Self-Supervised Branch
여기서는 Self-Supervised 기반의 Task들이 수행되는 Branch입니다. Masked feature reconstruction과 Clip-order prediction을 진행해주는 데 , 각각이 무슨 Task인지 그림으로 살펴보도록 하겠습니다.
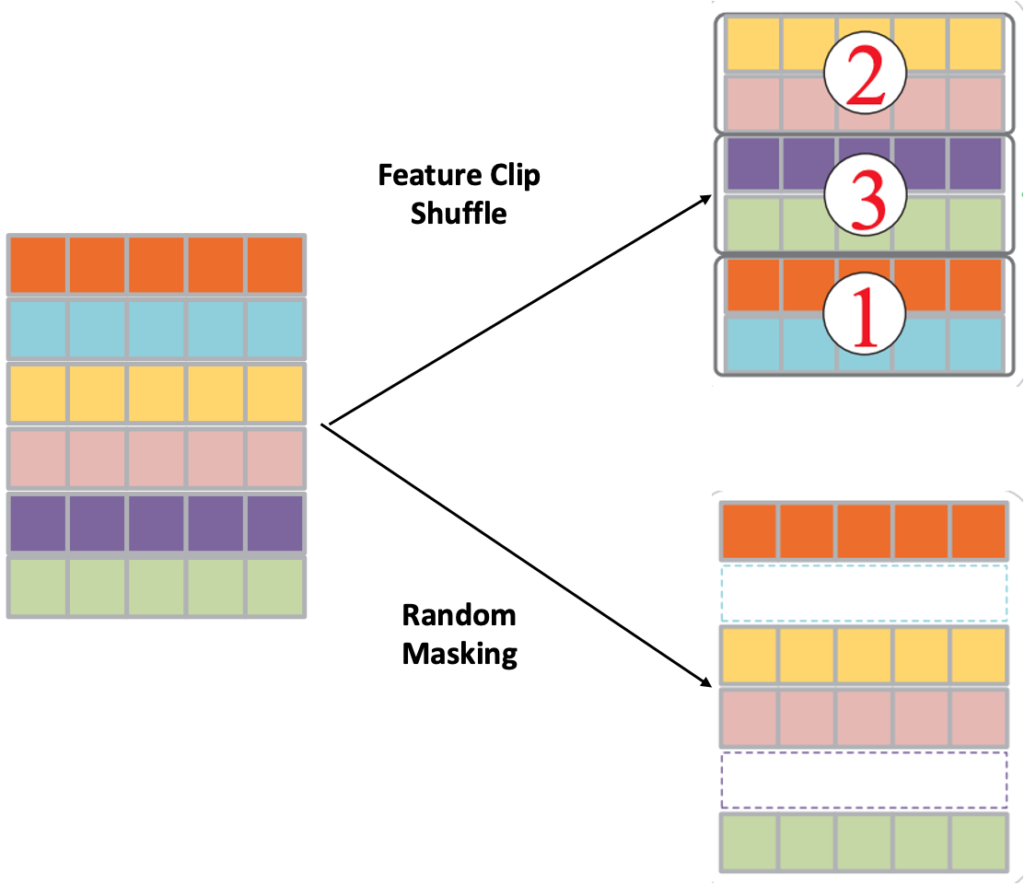
Feature Clip Shuffle은 Feature들의 순서를 임의로 섞었다가 , 올바른 Feature Clip의 순서를 예측하는 작업으로 , classification task로 진행이 됩니다.
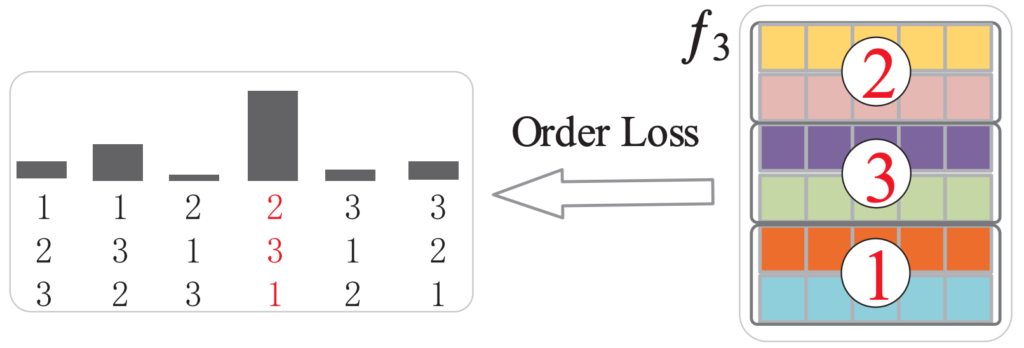
가장 높은 확률의 순서를 가지고 예측을 해서 , Order Loss를 구해주고 , 이러한 작업을 통해서 단순히 시간 순서대로 였던 Feature에 변화를 줘서 , 좀 더 discriminative 한 temporal representation을 학습하게 된다고 합니다.
Random Masking은 feature의 시간 축에서 , 어떤 시간 point의 feature를 지웠다가 다시 올바르게 복원하는 작업으로 써 Rregression task로 진행이 됩니다.
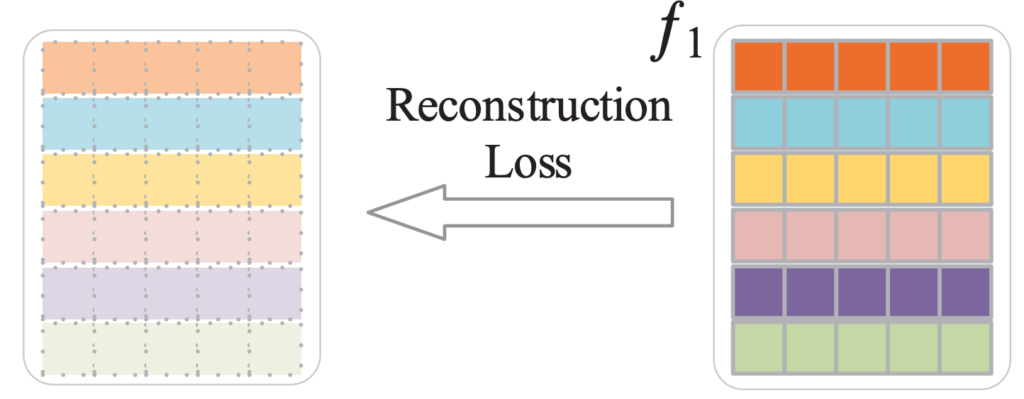
자세하게 서술을 하고 있지는 않아서 어떻게 Reconstruction이 일어나는지는 나와있지 않지만 , 이를 통해서 temporal semantic relation을 학습할 수 있게 된다고 합니다.
전체 Loss는 Semi-Supervised Loss와 Self-Supervised Loss로 구성됩니다.
Ltotal=Lsemi+λ3Lreconstruction+λ4Lorder
이때 Lreconstruction는 L-2 Loss를 사용했고 , Lorder는 CrossEntropy를 사용했습니다.
이렇게 Jointly 하게 Semi-Supervised 방식과 Self-Supervised의 방식을 End to End 방식으로 학습할 수 있는 Framework가 제안되었습니다.
Experiments
우선 , 데이터셋은 THUMOS'14와 ActivityNet v1.3을 사용했다고 합니다. 참고로 본 논문의 저자는 본인들이 제안한 방법이 feature - agnostic (feature에 상관없는)을 보이기 위해 activitynet으로 fine tuning 되지 않고 Kinetics로 Pretrained 된 I3D feature 또한 사용했다고 합니다. Boundary Matching Network(BMN)과 똑같은 전처리를 진행하였고 , 동일하게 Soft-NMS를 적용했다고 합니다.
Temporal Action Proposal Generation
Temporal Action Proposal Task의 목적은 action instance를 포함하는 Proposal을 만드는 것이며 , Ground Truth와 가능하면 overlap이 높게 끔 , 즉 Recall이 높게 끔 Inference 하는 것이 목적이라 보시면 됩니다.
Average Recall(AR)을 metric으로 사용하며 , 다양한 IoU threshold를 가지고 측정하게 됩니다. 또한 Average Number of proposals (AN)을 같이 사용하여 AR@AN을 metric으로 사용해줄 것인데 AN이 클수록 후보 Proposal들을 많이 만들어서 Inference 했다고 보시면 될 것 같습니다.(따라서 Recall이 더 높겠죠?)
- Comparsions with fully-supervised methods
먼저 , Supervised 방법론들과 비교입니다.
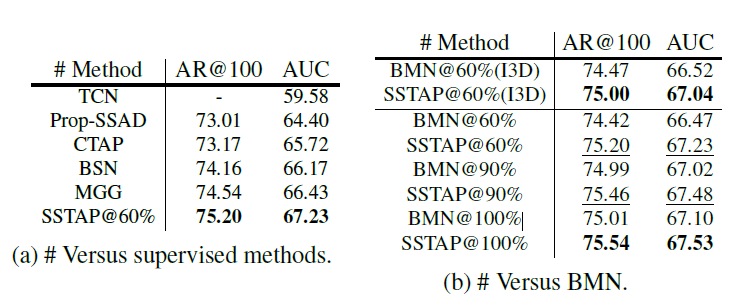
ActivityNet v1.3의 validation 데이터셋을 가지고 기존의 Supervised 기반의 Temporal action proposal 방법론들과 비교입니다. 뒤에 @60%는 라벨링 된 데이터를 60%만 사용했다는 의미입니다.
인상 깊은 점은 본 논문에서 제안된 SSTAP로 60%의 라벨링 데이터만 사용했을 때의 성능이 BMN@100%보다 조금 더 높게 측정되었다는 점입니다.
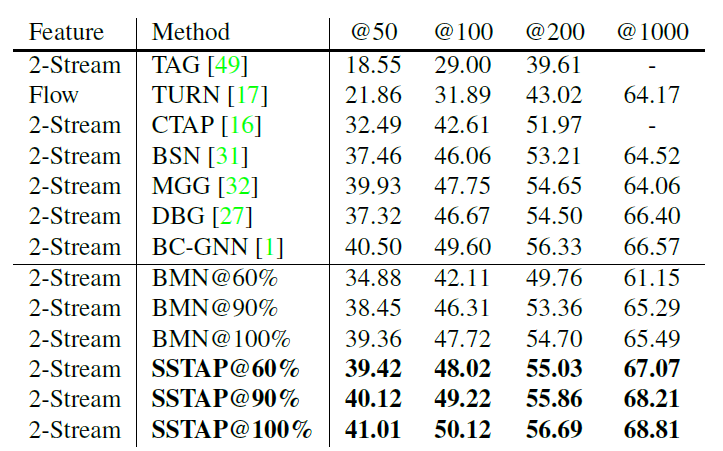
THUMOS'14 데이터셋을 가지고 비교한 Table입니다. 마찬가지로 좋은 성능을 보여주고 있고 SSTAP 방법론이 labeling 된 데이터를 더 사용할수록 성능이 좋아지는 것 또한 확인할 수 있습니다. I3D feature를 사용했을 때도 성능이 잘 나온다고 합니다. 이를 통해 본 논문에서 제안된 SSTAP 방법론이 feature-agnostic 하다고 얘기하고 있습니다.
무튼 , SSTAP가 비교적 더 적은 annotation 된 데이터를 가지고 기존의 Supervised 방식의 성능을 뛰어넘는 결과를 확인할 수 있었습니다.
- Comparsions with semi-supervised baselines
이거는 Semi-Supervised 방법론들과의 비교입니다. fair comparison을 위해 동일한 video feature와 post-processing을 거쳤다고 합니다.
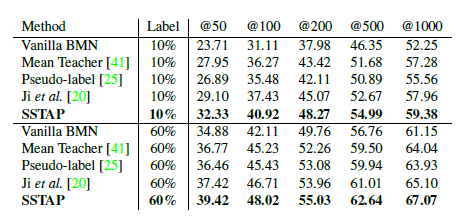
SSTAP가 다른 Semi-Supervised 방법론들과 비교했을 때 가장 좋은 성능을 보여주고 있습니다.
Ablation Study
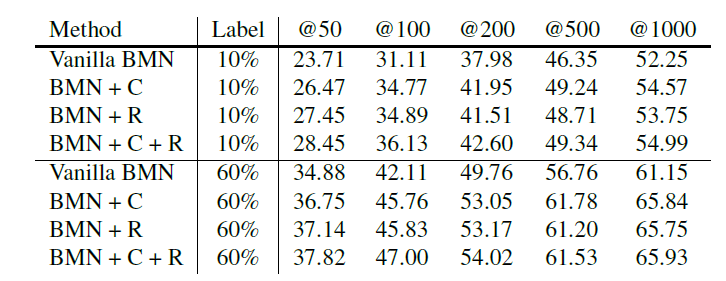
본 논문에서 제안된 components들이 성능 향상에 도움이 되는지를 분석한 Table입니다.
- F : Temporal feature flip
- R : masked feature reconstruction
- C : clip-order prediction
- S : temporal feature shift

우선 , 모든 Components를 사용했을 때 가장 좋은 성능이 나왔지만 , 다른 조합의 경우는 뭔가 성능이 왔다 갔다 하는 거 같습니다.
위의 Table은 self-supervised branch의 효과를 확인하기 위함입니다. BMN에서 clip-order prediction , masked feature reconstruction을 각각 추가했을 때 성능 향상을 확인할 수 있습니다.
Action Detection with SSTAP
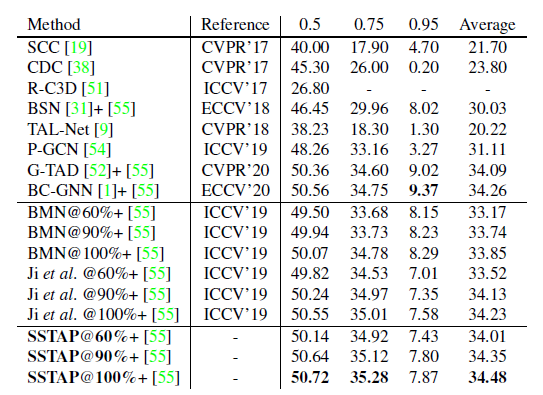
SSTAP가 만들어낸 Proposal을 가지고 , Temporal Action Localization의 성능을 측정했다고 합니다. SSTAP가 만들어낸 Proposal + BMN의 classification 부분을 결합하여 성능을 냈다고 합니다. 테이블을 확인하면 알겠지만 , 100%의 labeling 된 데이터를 사용하면 SOTA의 성능을 내고 있고 , 60% 정도만 사용해도 좋은 성능을 보여주고 있습니다.
Generalization Experiments
SSTAP framework가 BMN 말고도 다른 architecture에서 잘 작동하는지 증명하기 위해 SSTAP에 G-TAD framework를 결합했다고 합니다.
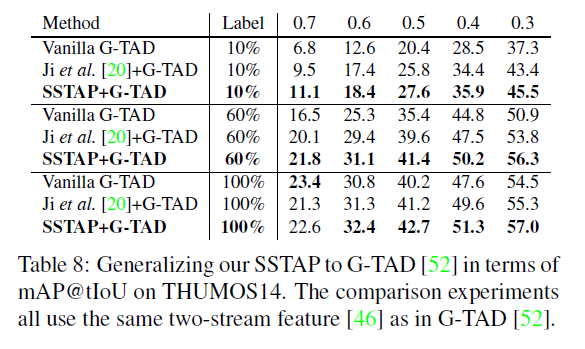
기존 G-TAD의 성능보다 SSTAP framework를 결합하니 더 성능이 향상된 것을 확인할 수 있습니다.
Conclusion
우선 , Semi-Supervised와 Self-Supervised의 개념을 동시에 적용해서 비교적 labeling 된 data가 적은 상황에서도 SOTA의 성능을 보여주는 Framework를 제안한 것은 정말 대단한 것 같습니다. 또한 많은 실험 결과를 보여줌으로써 SSTAP framework의 효과를 다양하게 보여준 것이 본 논문의 중요한 Contribution인 것 같습니다.
이제 직접 코드 가지고 , 가지고 있는 데이터셋들로 어느 정도의 성능이 나오는지 확인을 해보려고 합니다. SSTAP는 action dataset만 가지고 진행했는 데 , object나 , 사건 중심 데이터셋에서는 어떤 경향성을 보여주는지 확인하려고 합니다.
이전에 Temporal Localization 논문들을 찾아봤을 때는 Supervised가 대다수였는 데(16~18년도 논문) 최근 논문의 동향을 살펴보니 거의 다 Weakly Supervised , Semi-Supervised의 방법론들이 많이 나와있었습니다. 아무래도 Frame level로 어노테이션이 된 Video Dataset은 한정적이고 , 새롭게 만들려면 비용이 많이 드니 , 이러한 흐름은 자연스러운 흐름인 것 같습니다.
Video Retrieval이나 , Temporal Action Localization에서 Supervised가 아닌 접근은 어떻게 진행이 되고 있는 지도 한번 살펴봐야겠습니다. 리뷰 읽어주셔서 감사합니다.



