Before Review
이번에도 Temporal Action Localization 논문 리뷰입니다. 18년도 CVPR에 나온 논문이며 , 저번에 리뷰한 R-C3D보다 발전된 네트워크라는 생각이 들었습니다.
[CVPR 2016] Temporal Action Localizations in Untrimmed Videos via Multi-stage CNNs
[CVPR 2016] Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs
Before Review 이번 리뷰는 Video 분야에서 Object Detection과 유사한 , Temporal Localization problem을 multi-stage CNN을 처음 도입해서 문제에 접근한 Paper를 가져왔습니다. 논문에 이렇게 적혀 있었습니다..
taek-guen.tistory.com
[ICCV 2017] R-C3D Region Convolutional 3D Network for Temporal Action Localization
[ICCV 2017] R-C3D Region Convolutional 3D Network for Temporal Activity Detection
Before Review 이번 리뷰도 Temporal Action Localization 관련 논문으로 준비를 했고 , 저번 리뷰(S-CNN)의 후속 연구로 볼 수 있는 논문을 가져왔습니다. [CVPR 2016] Temporal Action Localization in Untrimme..
taek-guen.tistory.com
위의 두 개의 리뷰는 Temporal Action Localization을 수행할 때 단순히 Object Detection의 Pipeline을 적용하기 급급했던 느낌이 들었지만 , 이번 리뷰는 Object Detection의 Pipeline을 Temporal Action Localization에 적용하면 어떤 점이 문제가 있는지 문제를 제기하고 , 이를 개선시킨 논문입니다.
뭔가 주제를 하나 잡고 이게 어떻게 발전되고 있는지 추적하면서 논문 읽는 재미가 꽤 있는 거 같습니다. 논문 리뷰 시작하겠습니다.
Introduction
다른 Temporal Action Localization 논문과 비슷하게 시작합니다. Trimmed Video에서 Action Recognition 부분에서는 나름의 Progress가 있지만 , Untrimmed Video에서 Temporal Action Localization은 어려운 문제이기도 하지만 중요한 문제다 이렇게 얘기하고 있습니다. Temporal Action Localization은 Object Detection과 Pipeline이 비슷하여 , 당시 Temporal Action Localization의 접근 방식은 R-CNN 계열의 detection 구조를 착안하여 이를 Temporal Action Localization에 적용하는 방식이었습니다.
하지만 R-CNN 계열의 detection pipeline은 이미지 부분에서 성공적이었지 , 이를 video에 적용하려는 domain shift과정에서 발생할 수 있는 Gap을 고민해야 한다고 저자는 주장합니다.
즉 , Object Detection의 파이프라인을 사용하지만 이를 Video의 상황에 사용하기에 앞서 어떤 문제점이 발생할 수 있는지 정의하고 , 이를 개선하기 위해서 어떤 방법을 사용해야 하는지 제안하는 것이 본 논문의 Contribution이라 볼 수 있습니다. 저자는 아래와 같은 세 가지 의문점을 던지게 됩니다
How to Handle large variations in action durations?
Object Detection에서는 box들의 scale은 다르지만 , 그렇다고 그 bounding box들의 크기 차이가 크지 않습니다. 하지만 Temporal Action Localization 상황에서 Action 영역의 길이는 정말 몇 초에서 몇 분 이 정도로 제각각이라 비디오 구간 영역의 후보군을 만들어낼 때 약간 곤란한 상황이 발생합니다. 비디오의 길이가 정말 제각각인데 Receptive Field는 어떻게 설계해야 할까?
How to utilize temporal context?
Temporal Context Information이란 어떠한 instance 전후로 무슨 일이 일어나는지에 대한 정보를 의미합니다. 이는 비디오를 해석하는 데 정말 중요하게 사용이 될 수 있는 데 , 연기가 나고 있는 전투기가 아래로 추락하고 있다면 우리는 그 후에 이 전투기가 지상에 충돌하여 폭발할 것을 예상할 수 있습니다. 또 예를 들면 다이빙 대에 사람이 서 있다면 우리는 그 사람이 곧 다이빙을 할 것이라고 예상할 수 있습니다. 그렇다면 이렇게 Temporal Context Information을 잘 표현하는 Feature들은 어떻게 추출할 수 있을까?
How best to fuse multi-stream features
Action Recognition에서 좋은 효과를 보여주는 RGB-Video Frame과 Optical Flow를 fusion 시켜주는 시도를 저자는 Temporal Action Localization에서 적용을 하려고 하는 데 , 이것을 어떻게 설계하면 좋을 까에 대한 고민입니다.
제가 여기서 적은 의문점들을 저자는 Faster-RCNN 구조에 수정을 가해 TAL-Net이라는 network를 설계합니다. 간단하게 Faster R-CNN 파이프라인을 살펴보고 TAL-Net을 보도록 하겠습니다.
Faster R-CNN

Faster R-CNN은 object detection에서 진정한 End to End 방식을 접목시킨 Two-stage Detector입니다. Proposal generation stage와 classification stage로 구성이 되어 있는 데 위의 사진 중 왼쪽 그림을 보시면 됩니다.
먼저 , Input image가 들어오면 Feature map을 만들어내는 2D ConvNet을 통하여 2D Feature Map을 만들어주고 , 또 다른 2D ConvNet을 사용하여 , region proposal들을 만들어냅니다. Region Proposal Network에서 어떻게 작동하는지 궁금하신 분들은 [NIPS 2015] Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Network 논문을 참고하시면 될 것 같습니다.
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottle
arxiv.org
만들어진 Region Proposal에서는 RoI pooling을 사용하여 , 고정된 크기의 Feature map을 만들어줍니다. RoI Pooling을 통해서 나온 Feature를 가지고 DNN Classifier를 돌려서 Classification과 Box Regression을 진행해줍니다.
TAL-Net
위에 Introduction 부분에서 얘기한 세 가지 의문점들을 이제 하나씩 해결해보도록 하겠습니다.
Receptive Field Alignment
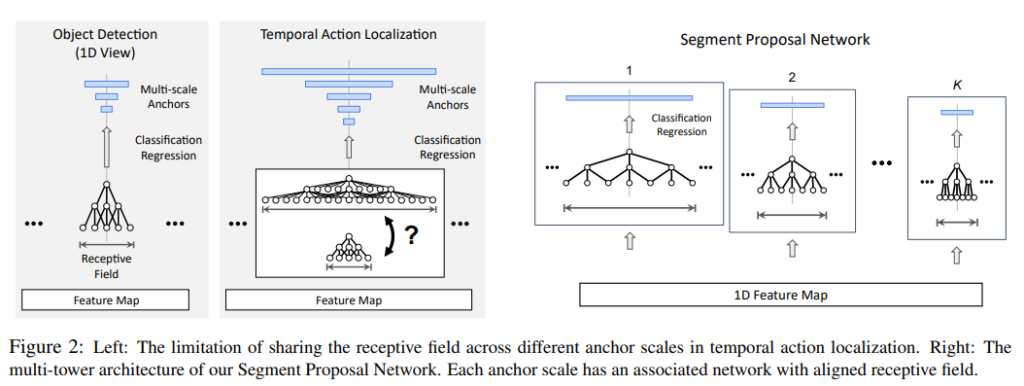
Proposal Generation 부분에서 Proposal들을 만들어주는 방식은 Detection 진영에서 보통 K개의 Filter를 가지고 1 by 1 Conv를 진행해준다고 합니다. 여기서 K는 scale의 개수가 됩니다. 이러한 방식은 Temporal Action Localization에서는 문제점을 가집니다. 이유는 위에서 언급한 것처럼 Temporal Action의 길이는 정말 다양하게 존재하는 데 , 고정된 Receptive Field를 가지고 진행해주면 다음의 문제가 생깁니다.
만약 Receptive Field를 크게 가지도록 고정시킨 상태라면 Large Anchor에 대해서는 적합하겠지만 , Small Anchor에는 불필요한 정보가 너무 많게 됩니다. 반대로 Receptive Field를 작게 가지도록 고정시킨 상태라면 , Small Anchor에는 적합하겠지만 , Large Anchor에는 정보가 부족하게 됩니다.
이러한 문제를 해결하기 위해 저자는 각 Anchor의 Temporal 길이에 맞춰서 Adaptive 한 Receptive Field를 가질 수 있는 방법을 고안합니다.
위의 그림에서 오른쪽을 살펴보면 Input으로는 1D Feature map이 들어가게 되고 , Anchor Segment들의 Scale에 따라서 Receptive Field를 다르게 취해주고 있습니다. 만들어줄 Anchor Segment의 Scale이 크다면 , Receptive Field는 크게 잡아주고 , 작다면 Receptive Field를 작게 잡아주고 있습니다.
"그렇다면 어떻게??"가 중요하겠죠 이제 천천히 살펴보면
예를 들어 우리가 원하는 Receptive field의 size를 $ s $라 두겠습니다.
단순하게 Convolution Filter들을 쌓아서 Receptive Field를 넓혀주는 방식은 가장 간단하지만 추가적으로 쌓아야 하는 Layer의 개수가 $ s $와 거의 Linear 하게 증가한다고 합니다. 쉽게 말해서 비효율적이죠 parameter 수가 많아지니... Pooling Layer를 이용하는 건 이보다는 낫지만 Resolution이 낮아지면서 Localization Accuracy를 희생하게 되는 구조가 되어버립니다.
Receptive field를 늘려주고 싶지만 Parameter 수를 많이 사용하고 싶지 않고 , Resolution을 살려주고 싶은 상황입니다. 저자는 Dilated Convolutuion을 제안합니다. Dilated Convolution의 작동 방식은 아래와 같습니다.
Dilated Convolution(Atrous Convolution)
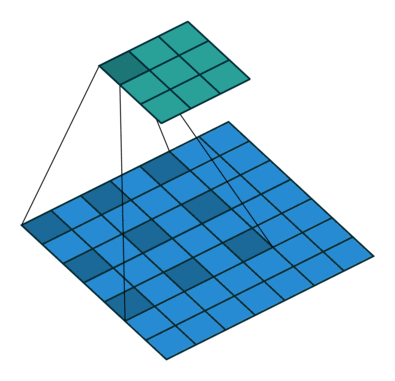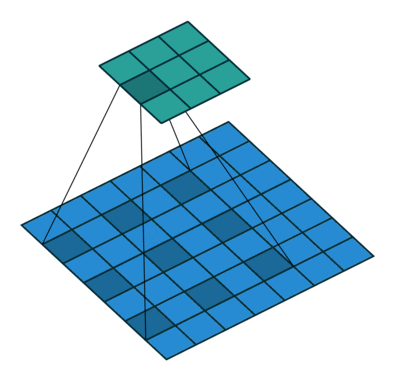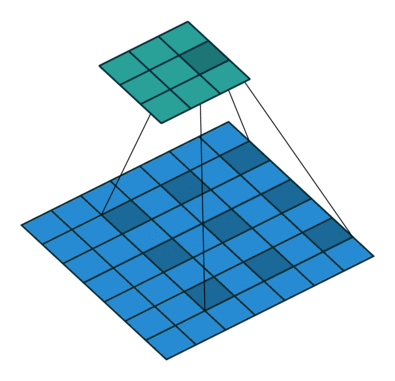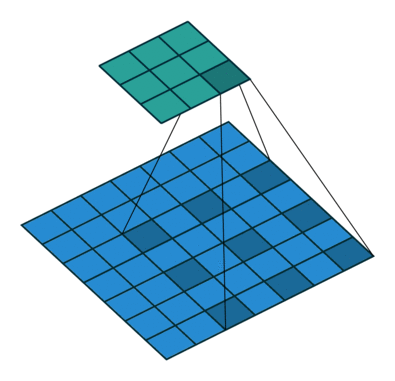
Dilated Convolution을 사용하면 지금 해결하고 싶은 상황을 해소할 수 있습니다. Receptive Field를 늘리면서 , Parameter 수는 그대로 가져가고 , Resolution은 줄어들지 않는 상황입니다.(물론 Padding은 이에 맞춰서 진행해야 합니다.)
여기서 dilation rate(sampling rate)를 첫 번째 Filter 같은 경우는 r1 = s / 6 두 번째 Filter 같은 경우는 r2 = 2 * s / 6로 정의해서 원하는 Target Receptive Field에 맞춰서 연산을 수행합니다.
이렇게 해서 Temporal Action Localization에서 Action의 Temporal 길이가 제각각인 문제점을 해결할 수 있었습니다.
Context Feature Extraction
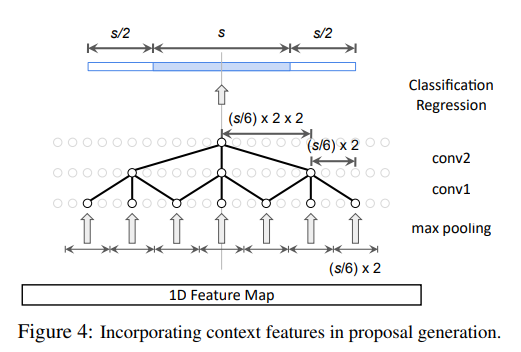
위에서 Temporal Context를 이해하는 것이 비디오를 이해할 때 중요하다고 예시를 들면서 설명을 했습니다. Dilated Convolution을 사용하면 Receptive Field를 Anchor에 scale에 맞게 설계할 수 있었습니다. 하지만 이 상황은 Anchor에 대한 Feature만 추출하는 상황입니다. 예를 들면 이 Anchor가 action을 담고 있다고는 하지만 이 전후의 상황도 고려하고 싶기 때문에 여기서 Receptive Field를 더 늘려주게 됩니다.
어떤 Anchor를 담당해주는 Receptive Field를 $ s $라고 할 때 , 앞 뒤로 $ s/2 $ 만큼 늘려주는 방식입니다. 어떻게 해주냐면 간단합니다. Dilated Convolution의 Dilation rate(sampling rate)를 두 배로 늘려주면 됩니다.
첫 번째 Filter : r1 = 2 * s / 6 , 두 번째 Filter : r2 = 2 * 2 * s / 6
좀 더 효과적인 비디오의 이해를 위해 단순히 Anchor 만 보는 것이 아니라 , 그 전후의 상황까지 조금 살펴보겠다는 의도입니다. 여기까지 진행해주면 길이가 제각각인 Feature가 생성되기 때문에 1D RoI pooling 연산을 거쳐준다고 합니다. 그 후 DNN Classifier(fully Connected Layer)를 통해 Classification과 Regression을 진행하게 됩니다.
Late Feature Fusion
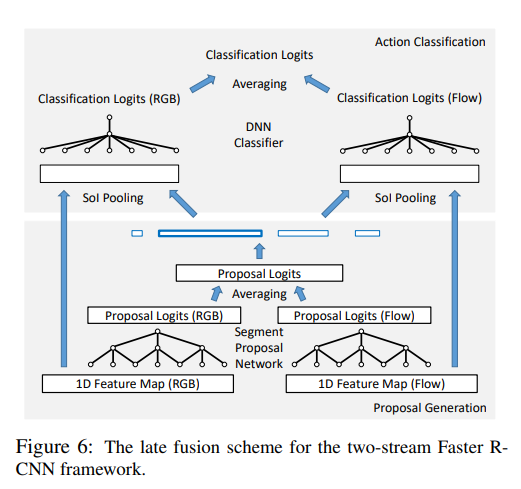
여기서는 Action Recognition 분야에서 자주 애용되던 방식인 RGB-frame과 optical Flow를 fusion 시켜주는 방식을 Temporal Action Localization에서 사용하였다고 합니다.
각각의 forwarding 과정을(RGB , flow) 독립적으로 진행하다가 각각의 Network에서 생성된 Proposal을 element-wise averaging 방식으로 합쳐준다고 합니다. 합쳐준 Proposal을 가지고 독립적으로 Classification 과정을 진행해주고 나온 Classification 결과를 또다시 element-wise averaging 방식으로 합쳐주고 그것을 최종 output으로 사용한다고 합니다.
early fusion 방식으로도 실험을 해보았다고 하는 데 , late fusion 방식이 early fusion 방식보다 더 좋은 성능이 나왔다고 합니다. 위에서 구상한 Pipeline을 독립적으로 진행하다가 중간중간 averaging 하는 방식으로 fusion 되는 구조인 것 같습니다.
Experiments
Averaing Recall(AR) : tIoU를 0.5부터 1.0까지 0.05씩 키워나가면서 Recall을 측정하고 모든 Recall을 평균 내준 것
Average Number of Proposals per Video(AN) : 비디오 당 생성된 Proposal의 평균 개수
Results for receptive field alignment
저는 여기서 Single과 Multi의 차이를 이해할 수 없었습니다. 뭐가 다른 건지 아무리 봐도 모르겠더라고요... 핵심은 Dilated Convolution을 통해 , Receptive Field를 Anchor의 scale에 맞게 설정해준 결과가 제일 높게 성능이 측정됐다가 되겠습니다.

Results for incorporating context features
아래의 테이블은 RGB frame이나 Optical flow를 입력으로 넣었을 때 Temporal Context 정보를 강화해준 것과 아닌 것의 성능 비교를 나타낸 테이블입니다. 꽤나 의미가 있는 게 이게 context Information을 추가한다고 해서 우리가 정보를 더 많이 사용한 것은 아닌 데 , 즉 Parameter 개수는 동일한데 성능이 개선된 것을 확인할 수 있습니다.

Results for late fusion
RGB와 Optical flow를 fusion 했을 때 성능 향상입니다. Action Recognition 논문을 제대로 읽어보진 않아서 왜 잘되는지는 잘 모르지만 , 아래 테이블처럼 Temporal Action Localization에서도 성능 향상을 관찰할 수 있습니다.
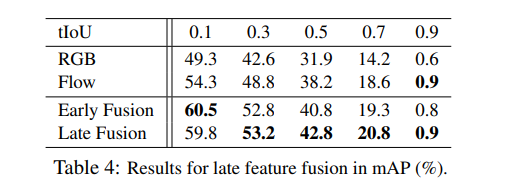
Action localization mAP on THUMOS'14
TAL-Net이 THUMOS'14 데이터셋에서는 다른 방법론들에 비해서 거의 SOTA급 성능을 달성한 것을 확인할 수 있습니다. 단순히 Detection 방법론을 따라 하는 것이 아니라 Temporal Action Localization에 맞게 끔 조절했기 때문에 어찌 보면 당연한 결과인 것 같기도 합니다.

Conclusion
이 논문의 가장 큰 Contribution은 Temporal Action Localization에서 별 다른 고민 없이 그냥 object detection pipeline을 사용하던 흐름 속에서 , image -> video 이렇게 도메인 변화 과정에서 발생하는 간극을 제시했고 , 이를 해결할 수 있는 파이프라인을 고안한 것이라고 생각합니다. 뭔가 이제 Temporal Action Localization 만의 분석을 통한 Insight를 담은 논문이 나온 것 같습니다. 연구가 더 어떻게 발전되는지 계속 리뷰하도록 하겠습니다.



