Before Review
이번 리뷰는 Temporal Localization 논문으로 준비했습니다. 이전에 리뷰했던 TSP : Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks 논문과 컨셉은 비슷하지만 접근 방식이 다른 방법론을 읽게 됐습니다. 문제 정의는 이전에 리뷰했던 논문과 동일합니다.
리뷰 시작하도록 하겠습니다.
Introduction
Untrimmed Video를 이해하기 위해서 비디오 분야에서는 Temporal Localization 연구가 활발히 이루어지고 있습니다. 이러한 상황에서 저자는 다음의 문제를 주장합니다. "Temporal Localization" Task는 시간의 흐름에 따른 Boundary에 민감하게 사전 학습이 되어야 하는데 기존의 사전학습 방법들은 Action Classification 데이터셋으로 사전학습이 되고 있다. 문제 정의 자체는 이전에 리뷰했던 TSP : Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks 논문과 동일합니다.
Image 분야에서는 대용량의 데이터셋인 ImageNet 데이터셋이 있습니다. 비디오 분야에서도 대용량의 데이터셋은 존재하지만 모두 Trimmed 형태의 Action Classification 용도의 데이터셋입니다.
이게 핵심입니다. Temporal Localization Task는 구간을 예측하는 작업으로써 Boundary Sensitive 하게 사전학습이 되어야 할 필요가 있습니다. 하지만 현재의 비디오 분야 대용량 데이터셋은 모두 Action Classification 용도의 데이터셋으로 비디오 레벨의 어노테이션만 존재하고 Boundary level의 어노테이션은 구하기 힘든 상황입니다.

즉 , 우리가 Transfer Learning을 진행하는 데 있어 Pretraining task와 Target task 간의 Gap 존재한다는 것을 저자는 문제로 삼고 있으며 이를 해결하기 위해 새로운 Pretraining 방법을 제안합니다.
기존의 존재하는 Trimmed Video 형태의 대용량 비디오를 활용하여 새로운 Untrimmed Video를 만들어내는 것이 핵심입니다. 즉, Trimmed video를 여러 개 이어 붙이는 형태로 Untrimmed Video를 만들 수 있고 boundary annotation 또한 자동으로 만들 수 있기 때문에 annotation에 발생하는 Cost가 없다고 주장합니다.
이렇게 새로 만들어진 Pretrain dataset과 저자가 제안한 Pretraining 기법을 도입하여 세 가지 Temporal Localization Task인 1) Temporal Action Localization , 2) Video Grounding , 3) Step Localization 분야에서 SOTA의 성능을 달성했다고 합니다.
Method
사실 Method는 굉장히 간단합니다. 결론만 얘기하자면 비디오를 이어 붙이고 이에 맞춰서 사전학습을 진행한 뒤 Down Stream Task를 학습한다 이렇게 정리할 수 있습니다. 요지는 1) 어떻게 이어 붙일 것 인지 , 2) 어떻게 사전학습을 시킬 것인지 이 두 가지를 집중해서 보면 될 것 같습니다.
Boundary Sensitive Video Synthesize
Trimmed video data는 각 비디오 별로 action class가 할당되어있습니다. 서로 다른 class의 비디오를 이어 붙이거나, 같은 class라도 시각적으로는 다른 영상인 두 영상을 이어 붙이면 그럴듯한 Untrimmed Video를 만들 수 있습니다. 본 논문에서는 네 가지 타입의 Boundary를 정의합니다.
- Different Class Boundary
아마 가장 직관적으로 알 수 있을 것 같습니다. 서로 다른 Class의 비디오로부터 두 개의 비디오를 Sampling 해와서 이어 붙이는 방법입니다.
Synthesized에 해당하는 행을 보면 두 개의 서로 다른 클래스인 Trimmed 영상을 이어 붙이는 것으로 ActivityNet과 비슷한 Untrimmed 비디오를 만들 수 있습니다.
만드는 방법은 위의 수식과 같은데 정말 별거 없고 T라는 point 이전과 이후에는 Video1 , Video2에서 추출한 프레임을 사용하며, T라는 point 경계에서는 두 프레임을 weighted blending 하는 방식으로 shot transition을 이용해 자연스러운 장면 전환을 할 수 있게 처리했습니다. 새로운 사전학습 데이터를 만든다는 관점에서 저러한 자연스러운 장면 전환 효과 없이 급작스럽게 프레임이 바뀌면 학습하는 입장에서는 trivial solution(자명해)에 해당한다고 합니다.
- Same Class Boundary
이번에는 같은 Class인 비디오로부터 Boundary를 만들어내는 방법입니다. 이것도 그림으로 보면 이해하는데 어려움은 없을 것 같습니다. 목적 자체는 같은 Class인 비디오를 이어 붙임으로써 Visual 적으로는 다르지만 Semantic Similarity가 강한 구간을 만들어내겠다는 것입니다.
그림을 보면 달리고 있는 장면을 담고 있는 비디오입니다. 기존의 ActivityNet을 보면 달리는 장면이라도 장면이 전환되면서 시각적으로는 변화가 생기지만 달리고 있다는 의미론적 관점에서는 동일합니다. 이러한 상황이 Untrimmed Video에서는 많이 발생한다는 점을 고려하여 본 논문에서도 같은 Class 끼리 이어 붙여줌으로써 이러한 상황도 사전학습이 잘 될 수 있게 처리해주었습니다.
여기서는 shot transition 없이 그대로 이어 붙였다고 합니다.
- Different Speed Boundary
여기서부터는 Class가 아니라 frame rate를 손봐서 데이터를 만들어줍니다. 예를 들어 장면이 전환되는 부분 background에서 foreground로 혹은 action에서 또 다른 action으로 전환되는 장면 전환의 속도가 비디오마다 다르기 때문에 frame rate를 조금 손봐서 이러한 부분도 처리를 해준다고 합니다.
아래의 Synthesized 데이터를 보면 frame rate를 수정하여 장면 전환이 금방 이루어지고 이는 temporal information을 보다 더 잘 catch 할 수 있게 해 줍니다. 왜냐하면 frame rate가 높아서 장면 전환이 오래 걸린다면 temporal 축으로 봤을 때는 거의 동일한 정보만을 얻게 되고 이는 학습을 함정에 빠트린다고 저자는 얘기합니다.
- Same Speed Boundary
Same Speed Boundary는 그냥 아무런 처리가 되지 않은 원래 그 상태의 비디오로 개념적인 완성도를 위해 약간 공집합 같은 느낌의 Boundary입니다.
Boundary Sensitive Pre-Training
자 이제 사전 학습시킬 데이터셋을 만들었으니, 사전학습을 어떻게 시킬지 고민을 해야 합니다. 본 논문에서는 Supervised 기반의 task를 가지고 사전학습을 진행했고 세 가지의 architecture를 제안합니다. 하나씩 살펴보도록 하겠습니다.
- Pretraining by classification
가장 간단한 방법은 새로 합성한 데이터의 타입들을 하나의 class로 설정해서 합성 데이터의 class를 맞추는 작업을 할 수 있을 것 같습니다. 정말 간단합니다. Loss함수도 그냥 Cross Entropy Loss를 사용했다고 합니다. 이렇게 하면 좋은 점이 새롭게 정의되는 타입에 대해서도 class만 추가해서 사전 학습시키면 되기 때문입니다. 확장성이 좋다는 얘기를 저자는 하는 것 같습니다.
- Pretraining by regression
또 하나의 방법은 chage point를 예측하는 regression 방식으로 사전학습을 진행하는 것입니다. 이것도 Smooth L1 Loss를 통해 학습을 진행했다고 합니다.
Pretraining Architecture
본 논문에서는 사전학습을 진행할 수 있는 세 가지 구조를 제안합니다. 사실 이것도 굉장히 단순합니다.

최종적으로는 분홍색으로 칠해진 Feature를 down stream task로 넘겨준다고 보시면 됩니다.
(a) Two-Stream
같은 구조의 Encoder를 가지고 하나는 기존의 Action Classification 방식으로 학습을 시키고 , 하나는 이번에 제안한 BSP(Boundary Sensitive Pretraining) 방식으로 학습을 시키는 것입니다. 최종적으로 사전학습이 끝나고 나서는 두 정보를 합치기 위해 Feature를 Concat후 Down Stream Task로 넘겨줍니다.
(b) Two-Head
여기서는 같은 인코더를 공유하면서 Classifier만 따로 학습시키는 구조입니다. 같은 구조를 가지고 두 개의 Task에 대해서 학습을 시키기 때문에 end-to-end joint training을 통해 backbone network가 잘 융합될 것이라는 가정을 저자는 합니다.
(c) Feature-distilation
여기서는 단일 Network를 추가 학습을 하는 데 Vanilla Teacher는 기존 지도 학습 방식으로 Action Classification으로 학습이 된 Network이며 , BSP Teacher는 본 논문에서 제안된 방식으로 학습된 Network입니다.
Feature Distillation Encoder는 앞의 두 Teacher와 비슷한 Feature를 생성하게 끔 Matching Loss를 통해 비슷한 Feature를 만들어내는 Feature Distilation Task를 수행하게 됩니다.
matching Loss는 그냥 두 feature 간의 L2-norm을 최소화시키는 Loss 함수입니다.
Experiments
실험은 세 가지 temporal localization task인 temporal action localization , 2) video grounding에 대하여 각각 본 논문에서 제안한 사전학습을 진행하고 성능을 측정했습니다.
- Comparison to the state of the art
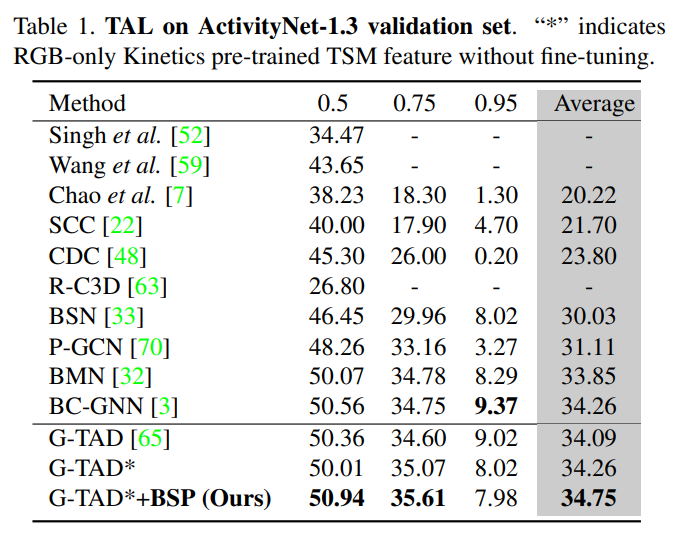
Temporal Action Localization에서 SOTA를 차지하고 있던 G-TAD에 BSP feature를 사용하는 성능이 꽤 많이 올라갔습니다. 확실히 Temporal 상황을 고려한 사전학습을 진행하니 기존 Base보다 성능이 올라가는 것 같습니다. 추가적으로 본 논문은 Optical flow를 사용하지 않기 때문에 연산량도 기존 TASK 보다 훨씬 줄어들었다고 합니다.
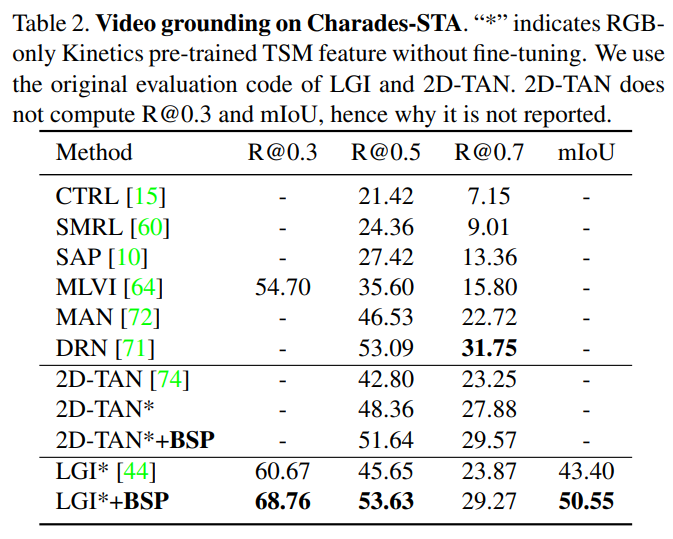
Video Grounding 분야에서도 성능 향상을 확인할 수 있습니다. Video Grounding은 간단하게 얘기해서 text형태의 쿼리를 던져서 원하는 구간을 찾는 것이라 보면 됩니다. 사람이 수영하고 있는 부분 찾아줘 이런 식일 때 수영하고 있는 구간을 반환하는 Task라 보면 됩니다.
- Feature Visualization
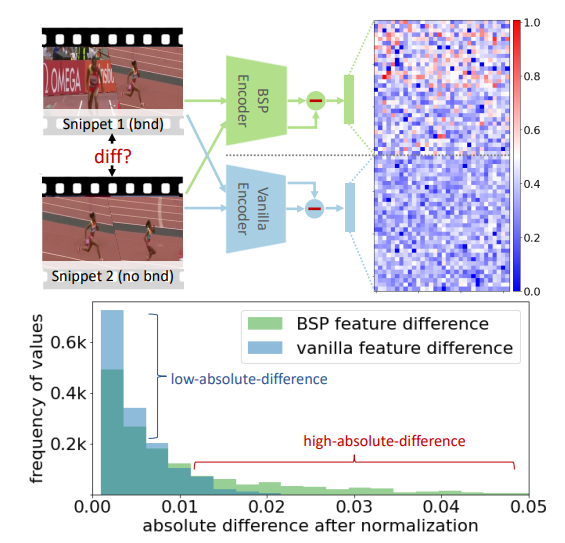
논문에서 제안된 BSP feature와 기존 사전학습 방식의 Vanilla feature를 비교했습니다. 연속적인 clip 간의 절대적인 feature representation 거리를 측정하였고, 사진에 보이는 행렬은 연속적인 clip 간의 feature의 차이를 32 by 32 형태로 reshape 한 것입니다.
먼저 일종의 feature 간의 차이를 나타내는 matrix는 BSP 방식이 좀 더 distinct 한 feature를 가지고 있다고 주장하는 게 저기 보이는 빨간색 부분이 더 많기 때문에 그렇다고 합니다. 아래의 Vanilla feature는 두 연속적인 clip 간의 feature 차이가 크지 않아 빨간색인 부분이 없다고 하네요. 사실 뭔가 분석 자체가 그렇게 의미 있는 분석은 아닌 거 같다는 생각이 듭니다..
아래의 히스토그램을 보면 두 연속적인 clip 간의 feature distance를 히스토그램 방식으로 나타낸 것입니다. 거리가 크면 클수록 temporal information을 잘 catch 했다고 주장합니다.
의미를 나름 부여해보고자 했던 visualization 인 것 같은데 개인적인 생각으론 ViSiL이나 TSP에 나와있는 Heatmap 방식으로 Visualization 했다면 좀 더 좋았을 것 같다는 생각이 듭니다.
- Qualitative Result
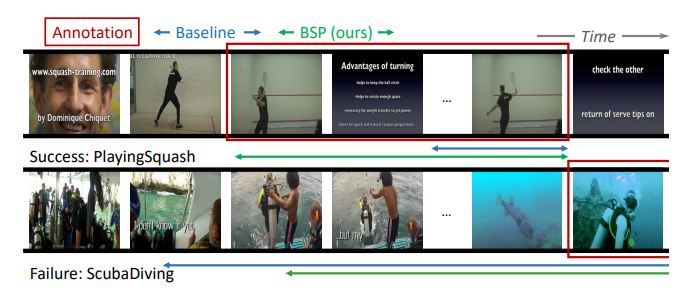
정성적 결과입니다. 논문에는 저 Figure밖에 없어서 뭐지 공간이 없었나, 아니면 생각보다 정성적 결과가 안 좋았나 이런 생각이 들었습니다. 위의 사진은 Baseline인 G-TAD 대비 더 잘 예측을 할 때를 보여주지만 아래의 사진은 Baseline과 BSP가 둘 다 실패했지만 BSP가 더 합리적이다 이렇게 얘기는 하고 있습니다.
뭔가 정성적 결과 자체는 의심이 들 정도로 부족하다는 느낌을 받긴 받았습니다.
- Ablation studies

마지막으로 아까 정의했던 4가지 boundary에서 조합을 다르게 하여 사전 학습시켰을 때 결국에는 4가지의 모든 boundary case를 넣어서 학습시키는 게 가장 성능이 높다 이렇게 주장하고 있습니다.
Conclusion
작년도 연구과제를 진행하거나, 논문을 작성할 때 많은 부분을 차지했던 것이 TSP : Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks 논문이었습니다. 이 논문과 문제 정의는 동일하면서 방법론은 저희가 이전에 진행했던 Objectrieval과 상당히 유사한 논문이었습니다.
보면서 느낀 건 사람 생각하는 건 비슷비슷하기도 하구나 이런 느낌이 좀 강하게 든 논문이었습니다. 확실히 Temporal Localization Task는 어노테이션이 제공되는 데이터셋의 한계 때문인지 Overfitting이 강하게 되어있다는 느낌을 이번 연도에 다양한 실험을 해보면서 느꼈는데, 본 논문의 Contribution은 그러한 문제점을 어느 정도 해결할 수 있는 방향을 제시하는 것 같습니다.
확실히 Temporal Localization의 앞으로의 연구 방향은 Annotation의 의존도를 낮추는 것 같습니다. 본 논문에서는 직접 annotation 없이 기존의 대용량 Trimmed video dataset을 가지고 temporal localization에 사용할 수 있는 사전학습 데이터셋을 만들 수 있는 방법을 제안함으로 써 논문이 Accept 된 것 같습니다.
리뷰 읽어주셔서 감사합니다.



