Before Review
이번에는 비디오 관련 논문이지만 Video Representation Learning을 다룬 논문을 읽게 됐습니다. 본래는 Weakly Supervised Temporal Action Localization 쪽을 계속 follow up 할 생각이었는 데, 본 논문의 제목이 너무 흥미로워서 이번에 읽게 되었습니다.
읽으면서 이렇게 공감이 많이 되는 논문은 또 처음인 것 같습니다. 작년 비디오 관련 논문을 읽거나, 실험을 진행하면서 느꼈던 점은 비디오 관련 Task는 학습 데이터셋에 대해서 Overfitting이 너무 심한 거 같다는 느낌을 받았습니다. 이번 저자도 동일하게 문제를 제기하고 있습니다.
작년에 논문을 작성했던 컨셉중 하나도 비디오의 Background를 제거해 보다 General 하며, Discriminative 한 feature를 얻는 것이었는 데, 이번 논문도 비슷합니다.(하지만 더욱 General 하고 대단한..?)
핵심은 비디오의 Background 정보에 bias 되지 않도록 하는 Self-supervised 기반의 video representation learning 기법을 제안하고 있습니다. 아이디어도 상당히 간단하며 명료하니, 비디오를 잘 몰라도 부담 없이 리뷰 읽으실 수 있을 것 같습니다.
리뷰 시작하도록 하겠습니다.
Introduction
최근 나온 비디오 논문들이 하나 같이 입 모아 얘기하는 것은 Video 관련 annotation 문제입니다. YouTube나 Instagram, Tik-Tok 등 소셜/미디어 플랫폼들의 영상 관련 서비스가 큰 인기를 가지게 되면서 생기는 비디오의 데이터양은 기하급수적으로 늘어나고 있는 상황입니다. 하지만 비디오 데이터셋의 annotation cost는 특히나 더욱 어렵습니다. 데이터의 크기가 다른 데이터에 비해서 압도적으로 크기 때문입니다.
Annotation의 한계에서 벗어나기 위해서 Self-Supervised 기반의 Video Representation Learning이 비디오 분야에서 활발하게 연구가 진행되고 있습니다. 이미지 분야에서 사용되던 Self-Supervised 기반의 Video Representation Learning 기법이 Video로 넘어오고 있긴 하지만, 두 domain 사이에는 크게 다른 점이 하나 있습니다.
바로 비디오 데이터는 scene이나 object structure에 대해서 implicit biases를 가지게 된다는 점입니다.

무슨 말이냐면 어떠한 prediction을 진행할 때 temporal 한 정보를 활용하여 예측을 수행하는 것이 아니라, 비디오의 배경 정보만 보고 예측을 수행한다는 것입니다. 비디오는 연속적인 frame 속에서 temporal 한 semantic information을 잘 활용하는 것이 중요한 데, 실제로는 이러한 정보가 활용되는 것이 아닌, background의 시각적인 정보에 overfitting 된다는 점입니다. 그래서 결국 학습 데이터에 overfitting이 발생하고 feature representation이 scene-based 하게 된다고 합니다.
위의 사진 중 첫 번째 장면을 보면 정확히는 축구를 하는 것이 아니라, 잔디장에서 텀블링을 하고 있습니다. 다만 비디오의 전반적이 배경장면이 축구장과 흡사해서 Prediction은 Playing Soccer로 수행하고 있습니다.
두 번째 장면을 보면 또 정확히는 달리기를 하는 게 아니라 러닝머신 위에서 춤을 추고 있네요..ㅋㅋ 역시나 비디오의 전반적인 배경장면이 헬스 장위의 러닝머신이라는 점이 Dance가 아닌 Run으로 Prediction을 유도한 것 같습니다.
이에 본 논문의 저자는 feature representation이 scene-based가 아닌 motion pattern에 집중할 수 있도록 Background Erasing(BE) 기법을 제안합니다. motion pattern에 집중한다는 것은 결국 어떠한 sequence 한 움직임들의 관계를 capture 하겠다는 의도로 결국 temporal information에 집중하겠다 라는 말과 동치로 받아들이면 됩니다.
저자가 제안한 BE의 목표는 더욱 General 한 model을 만들겠다는 의도로 보면 되고, 또한 굉장히 Simple해서 기타 다른 Self-Supervised 기반의 방법론들에 바로 갖다 붙일 수 있다고 합니다. 이따 실험 파트에서 보겠지만 효과도 상당한 것 같습니다.
그렇다면 제안된 방법론에 대해서 이제 알아보도록 하겠습니다.
Proposed Method
Methodology
아이디어의 핵심은 노이즈를 추가해 배경을 지우겠다 이렇게 요약할 수 있는데 너무 추상적이니 자세히 설명해보도록 하겠습니다. 비디오 관련 많은 방법론들은 Optical-flow도 같이 사용하는 경우가 많습니다. 단순히 RGB frame만 사용하기엔 motion 정보가 부족할 수 있기 때문입니다.

위의 사진이 논문의 아이디어입니다. 세 개의 프레임의 연속으로 이루어진 장면이 있다고 칠 때, 위의 그림은 노이즈를 넣지 않은 장면입니다. 그런데 이제 아래의 상황은 가운데에 존재하는 프레임을 다른 프레임에 조금씩 더해줘서(픽셀 단위로 선형 결합을 이룬다는 의미입니다.) 노이즈 한 프레임들을 만듭니다.
약간 장면 전환되는 그런 느낌이라고 볼 수 있는데, 여기서 주목해야 할 점은 프레임 자체는 노이즈 해지지만 Optical-flow의 양상은 그대로라는 점입니다.
Optical flow의 양상이 그대로라는 점은 결국 Motion Pattern 즉, temporal 한 information은 그대로라고 해석할 수 있습니다. 따라서 저자는 이렇게 Noise 한 Clip과 정상적인 Clip 간의 Feature Representation을 동일하게 만들 수 있다면 프레임의 배경 정보에 집중하는 것이 아니라 Motion 정보에 집중할 수 있게 만들 수 있다고 주장합니다.
아래의 그림을 보면 이제 전체적인 그림을 볼 수 있습니다. 상당히 간단하니 부담 없이 이해할 수 있을 것 같습니다.
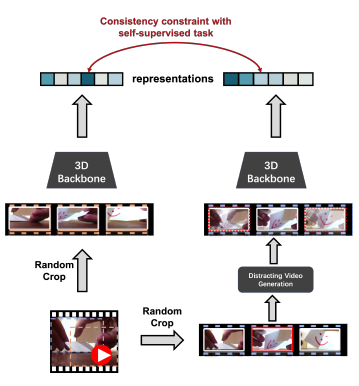
하나의 비디오 클립이 있다고 가정하겠습니다. 잘 보일지는 모르겠지만 저기 점선으로 Spatial 하게 Crop을 해주고 있습니다. 그렇게 Random Crop을 통해서 같은 Clip에서 추출되었지만 Spatial 하게는 조금씩 다른 두 Clip을 만들 수 있습니다. 이렇게 두 Clip을 만들면 어떻게 될까요?
두 Clip은 같은 Clip으로부터 만들어졌지만, 다른 Spatial 부분에서 Crop이 되었으니, 두 Clip은 픽셀 레벨의 분포는 다른 distribution을 가집니다. 하지만 동시에 두 Clip은 같은 Clip에서 추출되었으니 Semantic level에서는 동일장면이기 때문에 서로 Temporal Consistency를 가지게 됩니다.


위의 그림을 보면 무슨 말인지 이해할 수 있을 것 같습니다. Augmentation 느낌으로 비슷하면서도 다른 두 Clip을 만들었다 보면 됩니다. 핵심은 두 Clip은 Temporal 한 Consistency를 공유하게 된다 정도로 일단 기억하면 될 것 같습니다.
이제 Distracting Video를 생성해줍니다. 이 Distracting 비디오는 위에서 얘기했던 노이즈를 넣어준 비디오 클립이라 보면 되는데 위의 사진 중 파란색 점선으로 둘러싸인 클립을 봤을 때 빨간색 박스가 쳐진 프레임을 가지고 노이즈를 추가할 수 있습니다.

프레임을 합치는 방법은 간단합니다. 그냥 Linear Combination으로 만들어주는 데 formulation은 아래와 같습니다.
- $\hat{x}=(1-\lambda )\ast x^{(j)}+\lambda \ast x^{(k)},j\in[1,T]$
Clip에서 랜덤 하게 하나의 프레임(k번째 프레임)을 고정시키고 그 고정된 프레임을 가지고 다른 프레임에 더해주는 작업을 취해줍니다. 위의 사진처럼 각 프레임들이 노이즈 해진 것을 볼 수 있습니다. 하지만 우리는 위에서 알아봤던 것처럼 noise를 추가한다고 해서 motion pattern이 변하지는 않습니다.
이렇게 만들어주면 두 클립은 motion pattern이 비슷하면서 spatial 정보는 다른 상태입니다. 결국 우리는 model이 spatial에 집중하지 않고, motion pattern에 집중할 수 있도록 만들어주면 본 논문의 목적이 달성될 수 있다고 생각할 수 있습니다.
두 클립을 어떠한 3D Backbone을 태워주고 나온 feature에 대해서 두 feature representation이 같도록 만들어주면 원하는 Video Representation feature를 만들 수 있을 것 같습니다.
Plug and Play
위에서 알아봤던 Background Erasing은 결국 Frame 레벨에서의 노이즈를 만들고 이 노이즈에 강인하게 끔 Representation Learning 하는 것이 전부라 할 수 있습니다. 저자는 이제 이 아이디어를 다른 Self-Supervised 방법론에 적용할 수 있는 방향을 알려줍니다.
- Pretext Task
대다수의 pretext task 기반 self-supervised 학습 방법은 multi-category classification task로 cross entropy loss를 통해 최적화가 된다고 합니다. 어떠한 pretext가 transformation 집합 $R$로 정의된다고 치고 $M$번 연산을 진행된다고 치면 Loss function은 아래와 같이 일반적인 formulation으로 정의될 것 같습니다.
- $L_{p}=-\frac{1}{M} \sum^{}_{r\in R} L_{ce}(F(r(x);\theta ),r)$
그냥 crossentropy loss인데 pretext task에 맞춰 transformation이 가미됐다고 생각하면 될 것 같습니다.
여기서 Background Erasing의 최적화 방향은 아까도 얘기했듯이, 두 Clip의 feature representation이 같아지도록 하는 것이기 때문에 단순한 Distance term을 추가해줍니다.
- $L_{be}=\parallel \psi (f_{x^{o}})-\psi (f_{x^{d}})\parallel^{2} $
여기서 $\psi$는 feature를 projection 시키는 함수라 보면 되는데 backbone을 거치고 나온 임베딩 feature, $f(x) \in R^{C\times T\times H\times W}$의 차원을 가지게 됩니다. C는 feature 채널이고 T가 temporal 차원이라고 보면 됩니다.
이 feature에서 spatial global max pooling을 진행하는데 이유는 $x^{o}$와 $x^{d}$가 다른 pixel distribution을 가지기 때문에 해주는 것이라고 합니다. 따라서 feature는 $f(x) \in R^{C\times T}$가 됩니다.
따라서 Pretext 기반 Self-Supervised 기법에 BE를 적용한 최종 Loss는 $L=L_{p}+\beta L_{be}$로 정의할 수 있습니다.
- Contrastive Learning
이번에는 Contrastive Learning 기반의 Self-Supervised 학습 기법에 적용할 수 있는 방향을 제시합니다. Contrastive Learning은 positive pair끼리 feature similarity는 최대로 하고 negative pair끼리 similarity를 최소로 하는 식의 학습을 의미합니다. 그렇다면 Background Erasing을 넣었을 때, Positive와 Negative는 어떻게 정의가 되고, 이를 최적화시킬 Loss함수만 알아보면 될 것 같습니다.
비디오 데이터셋 $D$가 $N$개의 비디오로 구성되어 있다고 할 때, $D=\{ x_{1},x_{2},\ldots ,x_{N}\} $ 각 epoch 마다 비디오 하나를 random 하게 sampling 합니다. $x_{i}$를 sampling 했을 때 우리는 위에서 비디오에 노이즈를 추가해서 만들었던 Distracting Video를 만드는 과정을 살펴봤습니다.
즉, Original video 인 $x^{o}_{i}$와 Distracted video인 $x^{d}_{i}$을 얻을 수 있습니다.
이때 $x^{o}_{i}$와 $x^{d}_{i}$는 Positive로 정의합니다. 같은 비디오로 출발했기 때문입니다.
그러면 Negative는 어떻게 만들까요? 네 바로 다른 비디오끼리는 Negative로 볼 수 있습니다.
- $N_{1i}=\{ s(x_{n})|\forall n!=i\} $
근데 여기서 저자는 좀 더 어려운 objective를 부여하기 위해 Hard Negative를 부여합니다. Hard Negative는 같은 비디오이지만 서로 다른 clip들을 의미합니다. 정리하면 그냥 Positive는 같은 비디오 같은 클립이고 Negative는 같은/다른 비디오 다른 클립이라 생각하면 될 것 같습니다.
- $N_{2i}=\{ x^{h}_{i}|x^{h}_{i}!=x^{o}_{i},x^{h}_{i}\in x_{i}\} , N_{i}=\{ N_{1i}\bigcup N_{2i}\} $
그다음에 feature representation은 다음과 같이 정의됩니다. $z_{x}=\phi (f(x))$
$f$는 backbone network를 의미하며 $\phi$는 Projection Layer로 Linear Layer로 D차원으로 투영시키게 된다고 합니다.
그래서 Contrastive Learning 기반 Self-Supervised 방식에 Background Erasing을 적용한 최종 Loss는 아래와 같습니다.
- $L=-\frac{1}{N} \sum^{N}_{i=1} log\left( \frac{exp(z_{x_{i}}\cdot z_{x^{d}_{i}})}{exp(z_{x_{i}}\cdot z_{x^{d}_{i}})+\sum^{}_{n\in N_{i}} exp(z_{x_{i}}\cdot z_{n})} \right) $
Loss는 InfoNCELoss를 그대로 사용하고 있고 결국 Background Erasing 관점에서 Positive와 Negative를 어떻게 정의하는지가 관건이었습니다.
Experiments
저자는 풍부한 실험으로 본인들의 work이 general 하며 성능이 좋다고 얘기를 하고 있습니다.
Dataset and Backbone Network
데이터셋으로는 Action Video인, UCF101, HMDB51, Kinetics, Diving48을 사용하고 있습니다. 한 가지 알고 가야 할 점은 UCF101, HMDB51, Kinetics이 세 가지 데이터셋은 Background가 비교적 많다는 점이고 Diving48 데이터셋은 비교적 적다는 점입니다.
Backbone Network로는 흔하면서 많이 쓰이는 C3D, R3D, I3D를 사용했다고 합니다. 각 Self-supervised 방식으로 Pretrain을 시키고 Transfer Learning시에는 각 방법론마다 마지막 fully connected layer를 랜덤 하게 초기화시켜 사용했다고 합니다.
Action Recognition
비디오 분야에서 state-of-the arts 성능을 보여주는 Self-supervised 기반의 방법론에 본 논문에서 제안된 Background Erasing을 추가했을 때, Action Recognition이라는 downstream task에 대해서 성능 변화를 보여주는 테이블입니다.
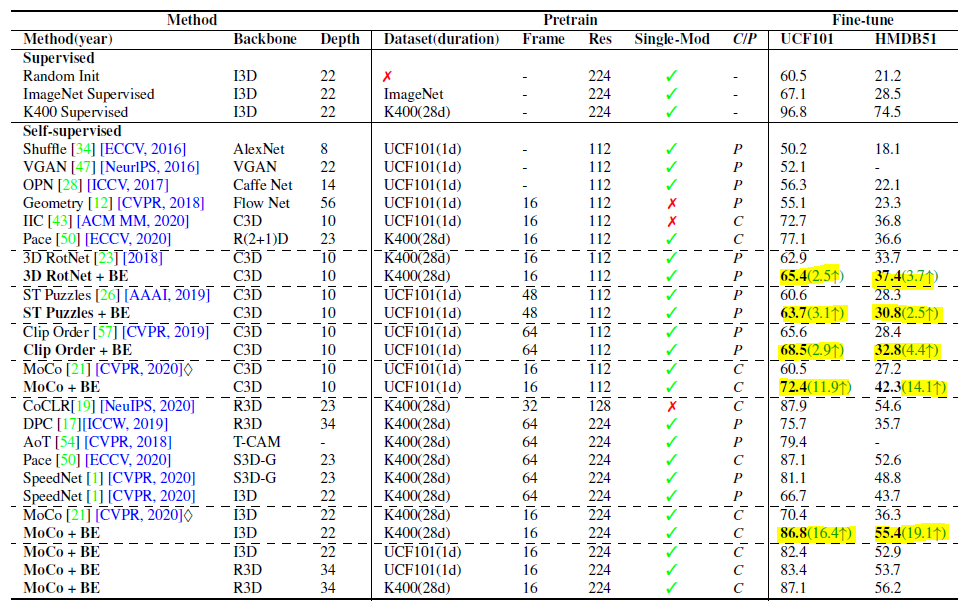
형광펜으로 칠한 부분이 Background Erasing을 적용했을 때 성능 gap입니다. BE를 적용해주면 모두 성능이 올랐을뿐더러 MoCo라는 Self-Supervised framework에서는 특히 시너지가 잘 맞는지 성능이 대폭 상승했습니다.
UCF 101 , HMDB51가 Background가 특히 많다고 저자가 얘기하는 데 그럼 Background가 상대적으로 적은 데이터셋에서는 효과가 없냐? 그건 또 아닙니다.
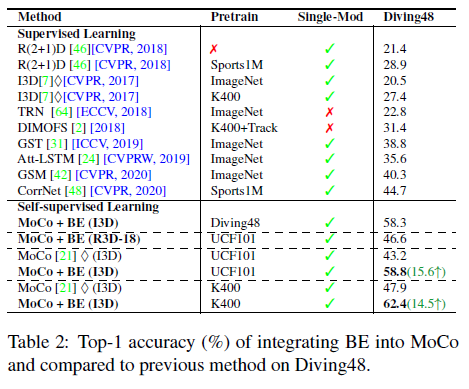
Diving48이라는 데이터셋은 다른 데이터셋 보다 Background가 더 적다고 합니다. 그럼에도 테이블을 보면 성능이 크게 향상된 것을 확인할 수 있습니다. 결국 이 Background Erasing을 통해 좀 더 motion pattern을 잘 표현할 수 있게 되면서 feature의 전반적인 표현력이 좋아진 것으로 해석할 수 있습니다.
Video Retrieval

Video Retrieval도 성능의 향상이 조금 있었다고 합니다. 이러한 결과 역시 representation이 더욱 discriminative 해졌기 때문에 성능이 향상되었다 볼 수 있습니다.
Variants of Distracting Video Generation
여기서는 노이즈를 추가하는 방식에 대한 Ablation을 보여주고 있습니다. 위에서 우리가 알아본 방법은 같은 비디오 내부에서 프레임 하나를 고정하여 그 고정된 프레임을 다른 모든 프레임에 더해줘서 노이즈를 추가하는 방법이었습니다. 사실 이런 방법 말고도 노이즈를 추가하는 방법은 많겠죠? 여기서는 다섯 가지의 방법을 가지고 결국 비디오 내부(Intra Video Frame)를 가지고 노이즈를 추가하는 게 가장 좋다고 보여줍니다.
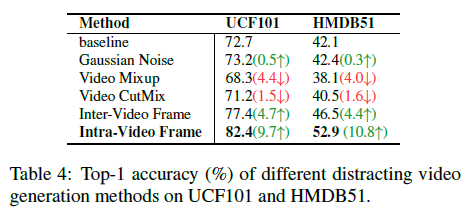
- Gaussian Noise : identical 한 while gaussian을 각 frame마다 더해주는 방식입니다.
- Video Mixup : 두 비디오를 가지고 frame by frame으로 보간을 해준다고 하는 데 정확히 뭔지는 잘 모르겠습니다..
- Video CutMix : 비디오의 특정 구간을 다른 구간으로 대체하는 것을 의미합니다.
- Inter-Video Frame : 다른 비디오에서 고정 프레임을 가져오는 방식입니다.
- Intra-Video Frame : 같은 비디오에서 고정 프레임을 가져오는 방식입니다.
Mixup이랑 CutMix 방식으로 노이즈를 추가하는 것은 오히려 성능이 떨어지고 있는데 이는 원래 비디오의 motion pattern을 해치게 되므로 temporal consistency가 망가진다고 합니다.
Intra Video Frame으로 노이즈를 만든 게 Inter Video Frame으로 만든 것보다 더 높은 성능을 보여주고 있습니다. 같은 비디오 내에서 추출된 프레임이 background bias를 지우는데 더 용이한 것 같습니다.
How does Background Erasing Work?
이 실험이 해석하기 조금 난해했는데 간단하게 정리만 하자면 static video classification의 성능이 증가할 때 Background Erasing을 통해서 얻는 향상률간의 관계를 보여준다 생각하면 됩니다.
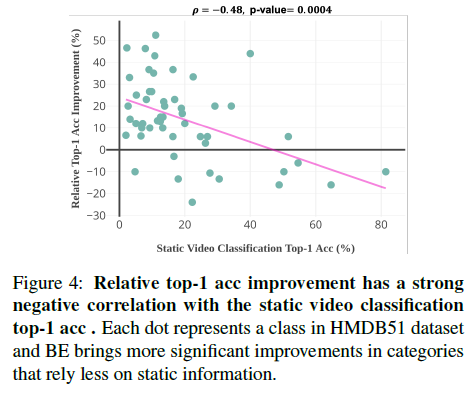
그래프를 보면 static video classification의 성능이 증가할 때 BE로 인한 상대적인 이득을 줄어들고 있습니다. static video classification은 저자가 문제를 정의한 부분이라 생각할 수 있는데, 이 static video classification의 성능의 증가와는 BE가 관계가 없다 즉, BE는 오로지 뭔가 flow가 존재하는 움직임이 존재하는 그런 상황에서 빛을 발휘한다 이 정도로 이해하면 될 것 같습니다. 피어슨 계수가 -0.48의 값을 가지는 것으로 결국 BE는 static 한 상황을 target으로 한 게 아니다 이렇게 얘기하고 있습니다.
Is Background Really Removed?
여기서는 재밌는 실험을 합니다. 정말 BE가 background 말고 moving subject에 더 집중을 하는 것인지 분석을 위한 실험이라 보면 되는 데, 이를 위한 하나의 데이터셋을 간단하게 만듭니다. HMDB51에서 action이 발생하는 부분만 모아서 만든 actor-HMDB51을 만들어서 몇 가지 실험을 진행합니다.
비교군은 다음과 같습니다.
- Random Initialization
- Kinetics MoCo Pretrain
- Kinetics MoCo + Background Erasing Pretrain
- Kinetics Supervised train
저자의 주장이 맞다면 (3)의 실험 결과가 (4)와 비슷하면서 (2)와 상당한 차이를 가진다면 저자의 주장은 타당하다고 볼 수 있습니다. 결과도 그렇게 잘 나와있네요.

Actor-HMDB51 데이터셋에서는 지도 학습과 겨우 2.9% 차이밖에 나지 않으면서 BE를 빼고 학습한 결과와는 16.1%의 차이를 보여주고 있습니다. 저자의 주장대로 motion pattern을 잘 학습했나 봅니다.
Visualization Analysis
여기서는 CAM을 조금 수정해서 모델이 어디에 집중하고 있는지 시각화를 해봤다고 합니다.
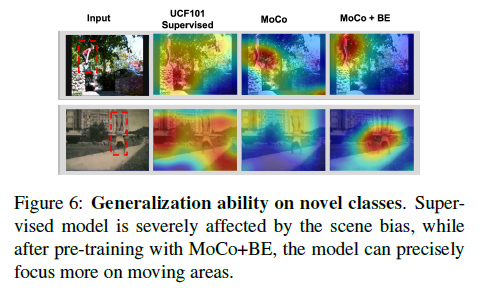
빨간색으로 칠해진 부분이 모델이 집중하고 있는 부분인데 흥미로운 것은 지도 학습 기반의 방법론보다 더욱 잘 motion 부분에 집중을 하고 있는 모습입니다. 정성적인 결과이니 그냥 흥미롭게 보면 될 거 같습니다.
Conclusion
이번연도 핵심적으로 연구해볼 방향 중 Video dataset에서 Background 정보를 어떻게 처리해야 하나 고민이 있었는데, 관련된 연구 중에서 좋은 논문을 읽게 된 것 같습니다. 저는 Background 처리를 Temporal Action Proposal 관점에서 구간을 아예 제거하는 식으로 생각하고 있었는데, 이렇게 Feature level에서의 Representation Learning을 통해 처리하는 것도 굉장히 좋은 접근인 것 같습니다.
비디오 진영에서 Representation Learning도 종종 읽어야 할 것 같은 게, 더욱더 표현력이 좋은 feature로부터 시작해서 downstream task로 가야 좋은 결과가 나올 수 있겠다 생각이 들었습니다. 본 논문에서 제안한 아이디어는 후에 제가 어떤 챌린지를 나가거나, 연구 과제를 진행할 때 기반이 될 수 있는 아이디어였던 것 같습니다.
리뷰 읽어주셔서 감사합니다.



