Before Review
기존 비디오 연구 흐름과는 다르면서 조금 새로운 방향을 제시하는 논문입니다. 어떻게 보면 당연히 나아가야 할 방향이기도 하지만 연구가 많이 되지 않은 부분이라고도 볼 수 있을 것 같습니다.
비디오의 길이가 긴 상황에서의 효과적인 Video Understanding을 위한 방법을 제시한 논문입니다.
논문 리뷰 시작하도록 하겠습니다.
Introduction
비디오 데이터는 일반적으로 상당히 길이가 다양합니다. 뭐 요즘 유행하는 Youtube short나 Tik-Tok 같은 것들을 생각해보면 short-form 형태의 비디오 데이터가 많긴 합니다. 그럼에도 Long-form 비디오 역시 많이 존재한다는 것은 부정할 수 없을 것 같습니다. 현재의 비디오 데이터 자체는 long-form이든 short-form이든 폭발적이기 때문이죠.
각각의 목적에 따라 방법론이 다를 것 같습니다. 하지만 이런 이유 말고도 대다수의 연구들은 short-form 형태의 방법론에 집중이 되어있던 상황입니다. 왜냐하면 우선 비디오 진영의 활발한 연구가 진행된 지 그리 오래되지 않았습니다. 대다수의 방법론들은 Image 분야에서 사용되던 방식으로부터 유래되었기 때문에 image의 static 한 성질과 비슷한 short-form 형태의 연구가 주로 이루어졌습니다.
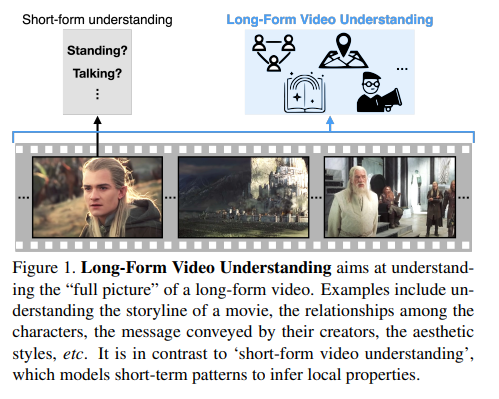
본 논문의 주장은 이렇습니다. 우리 이제 short-form에서 놀지 말고 long-form에서 놀자. 언제까지 짧은 클립만 가지고 연구할 거냐, 슬슬 레벨을 올려보자, 비디오의 전체 story를 이해시킬 수 있는 방법을 연구하자!! 사실 개인적인 생각으로는 아직 short-form도 정복된 것은 아닌 거 같지만 그래도 long-form으로의 이해도 필요한 단계가 오긴 왔나 봅니다.
당연히 저자는 주장에 뒷받침할 long-form 형태의 비디오를 이해할 수 있는 새로운 framework를 제안합니다. 이 과정에서 굉장히 fresh 한 아이디어가 하나 있는데요 이는 뒤에서 좀 더 자세히 얘기하도록 하겠습니다.
본 논문의 Contribution은 두 가지로 정리할 수 있을 것 같습니다.
- Long-form 형태의 비디오를 이해할 수 있는 Self-Supervised 방식의 framework 제안
- Large-scale의 long-form down stream task의 bench-marking을 제공합니다. Long-form task에 사용할 수 있는 LVU 데이터셋을 제공하였으며 공개된 AVA 데이터셋에 대하여 SOTA를 달성했다고 합니다.
Preliminaries
Long-form 비디오 연구가 아예 진행이 안된 것은 아니지만, text로 진행이 되었거나 video+text 방식 혹은 공개되지 않은 데이터셋에서 연구가 진행되는 등.. 그리 활발히 연구가 된 것은 아니라고 related work에서 잠시 언급을 합니다.
그나마 진행되었던 기존 연구와의 본 논문의 가장 큰 차이점은 비디오 데이터를 어떻게 바라보냐 입니다.
저는 여기서 좀 상당히 신선하다고 느꼈는데 제가 리뷰했던 그동안의 비디오 논문은 비디오 데이터를 단순한 frame의 집합으로만 여긴 경향이 있습니다. 즉, 비디오 데이터를 그냥 3차원의 볼륨을 가진 Tensor로만 처리를 한 것이죠.
좀 더 비유적으로 표현을 해보자면 비디오 데이터는 텍스트와 비슷하게 Sequence data의 성질을 가지고 있습니다. 따라서 frame을 단어로 보고 video를 문장으로 보는 식의 관점이 지배적이었습니다.
하지만 본 논문에서는 비디오 데이터를 그렇게 처리하지 않습니다. 저자는 object-centric representation을 통해 비디오 데이터를 접근합니다. 이게 앞서 언급했던 굉장히 새로운 시각인 것 같습니다.
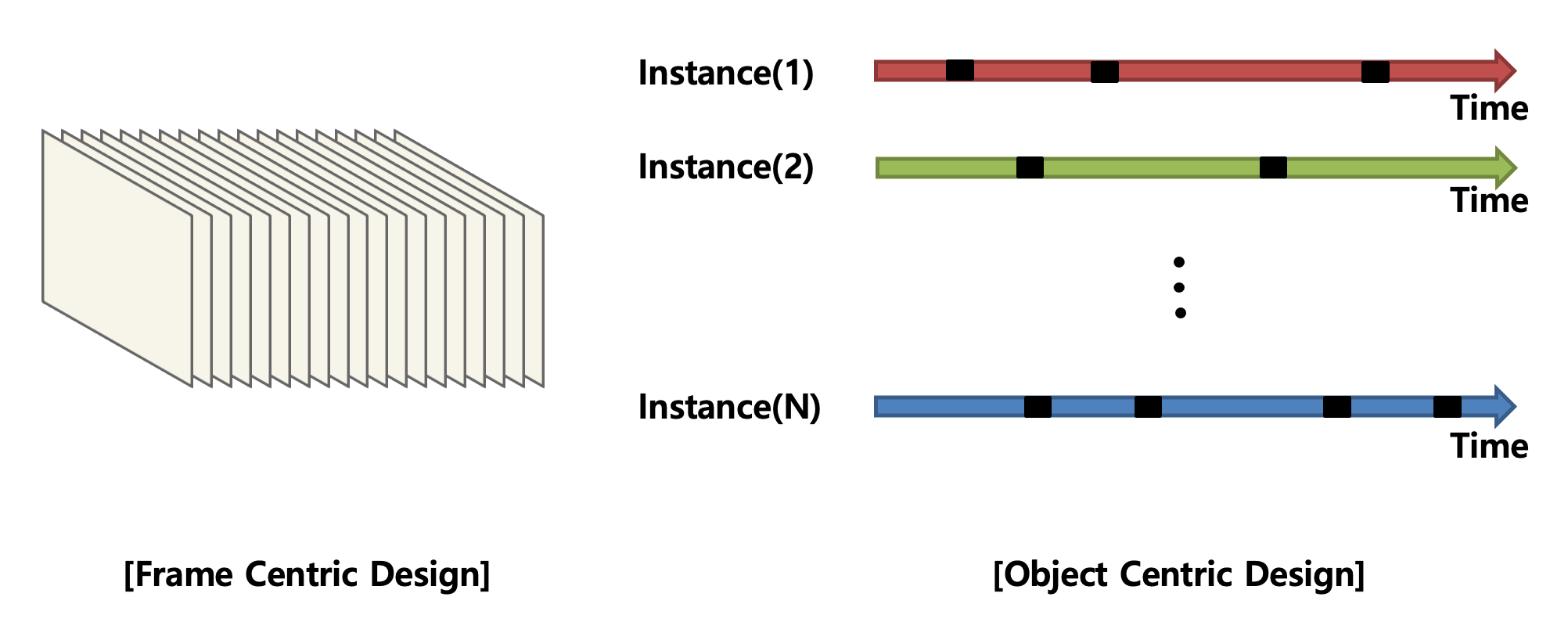
단순히 비디오를 width x height x time의 volume 덩어리의 pixel로 보는 것이 아니라, 시간과 공간의 흐름 속에서 비디오에 존재하는 각 instance 들끼리 서로 상호작용을 어떻게 하는 지를 modeling 해야 한다입니다.
Modeling
그렇다면 어떻게 modeling을 하는지 알아보도록 하겠습니다. 이제는 비디오 데이터를 단순히 2D 혹은 3D Conv방식으로 frame 전체를 태워서 feature encoding을 하지 않습니다.
Action and Object Detection
대다수의 비디오는 사람이나 물체의 성질이 visual world에서 전개되는 이야기의 중심적인 역할을 하게 됩니다.
따라서 가장 먼저 비디오 내부에 있는 모든 사람이나 물체를 찾는 것부터 시작됩니다. 여기서 사용되는 Detector는 Faster R-CNN을 사용했다고 하네요. $t$번째 프레임에 존재하는 $i$ 번째 objcet의 bounding box 좌표는 $s_{t,i}\in R^{4}$로 표현하며 여기에 해당하는 object feature는 $z_{t,i}$로 정의해주고 있습니다.
즉 이제는 frame 단위로 feature를 인코딩하는 것이 아니라, object 단위로 feature를 encoding 한다고 보면 됩니다.
Traking
하나의 instance(사람이나 물체 혹은 액션...)는 여러 프레임에 걸쳐서 등장하는 경우가 빈번합니다. 여기서는 그것을 따로 tracking을 해주는 모습입니다. \tau_{t,i}는 $t$번째 프레임에 존재하는 $i$ 번째에 해당하는 instacne의 인덱스를 표현한다고 합니다.
Shot Transition Detection
shot transition이라 함은 장면과 장면 사이의 전환을 나타내는 부분으로 영상 편집 효과를 생각하면 됩니다. 여기서는 rule-based thresholding 방식으로도 충분하기 때문에 PySceneDectector를 사용해서 검출했다고 합니다. 즉 비디오를 shot 단위로 쪼개기 위해 사용했다고 보면 됩니다.
뭔가 여기까지 보면 아직 정리가 잘 안 되는 것 같습니다. 뭔가 생뚱맞게 사람이나 물체를 찾고 있고 비디오를 shot 단위로 쪼개고 있고, 이제 이를 하나로 묶어줄 framework가 어떻게 설계되었는지 확인하도록 하겠습니다.
Long-Form Video Understanding
저자가 제안하는 long-form video understanding 방법론의 이름은 Object Transformer입니다. 이는 1) Object-Centric design 방식으로 고안되었고 , 2) Self-Supervised 방식으로 학습이 진행됩니다.
Object Centric Design
이제 비디오에 존재하는 모든 Instance를 포함하는 전체 집합인 $U$(people, tables, cars,...)가 있다고 해보겠습니다. 각각의 Instance $u\in U$는 이제 시공간상의 feature가 존재하고 있습니다. 왜 시공간이냐? 특정 frame에 위치하고 있다는 정보 = 시간 , frame에서 어디에 위치하고 있냐(bounding box) = 공간 이렇게 볼 수 있기 때문에 시공간이라고 표현하고 있습니다.
즉 이렇게 feature들의 집합으로 존재하고 있습니다. $\{ (t,s_{t,i},z_{t,i})|\tau_{t,i} =u,\forall t,i\} $
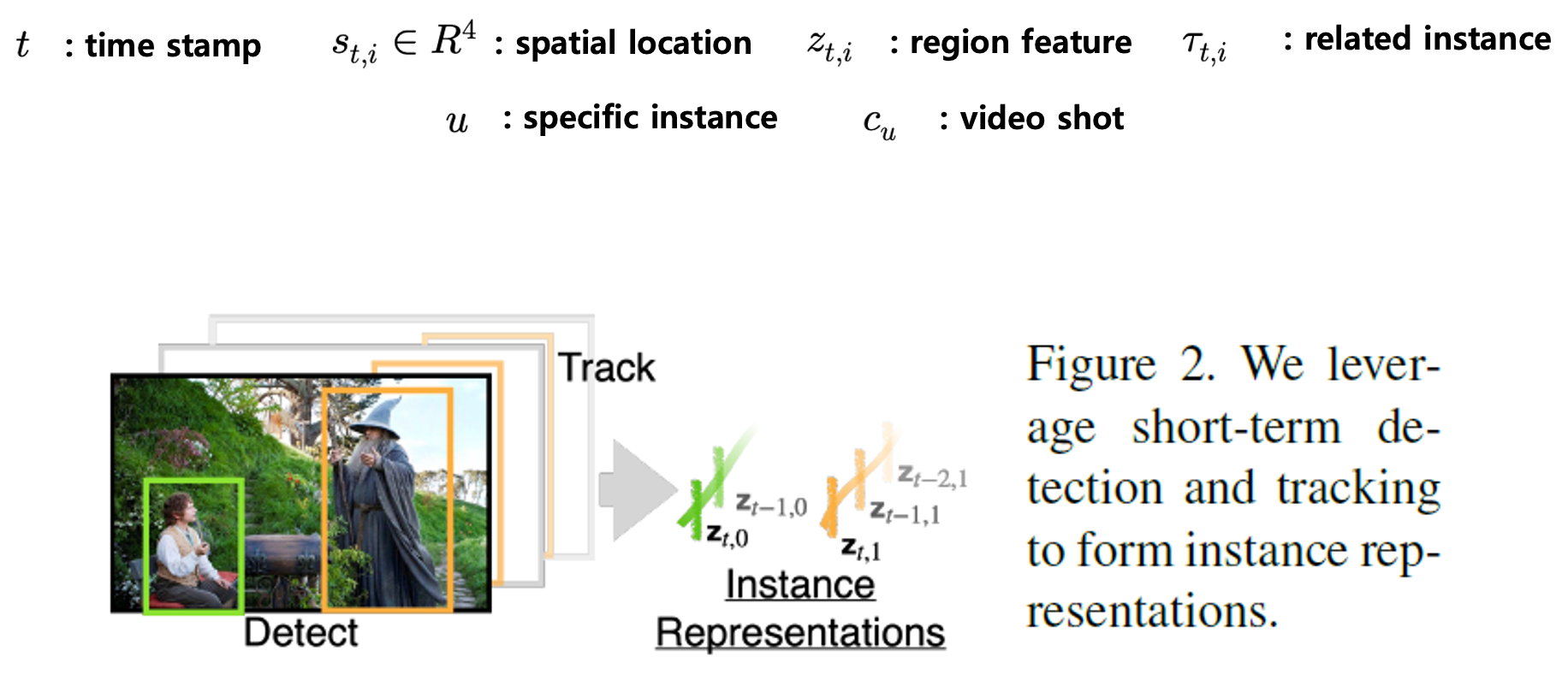
- $t$ 는 시간
- $s_{t,i}$ 는 boundind box 좌표
- $z_{t,i}$ 는 box에 해당하는 region feature
- $u$ 는 해당되는 instance 종류
- $c_{u}$ 는 해당되는 비디오의 shot
자 뭔가 상당히 많긴 하지만 여기서는 이렇게 비디오 데이터를 해석하고 있습니다. 조금 낯선 것 같네요. 이제 여기서 제안하는 transformer는 이 모든 정보를 취합해서 입력으로 전달받는 다고 하네요.
$y^{\prime }\doteq W^{(feat)}z^{\prime }+W^{(spatial)}s^{\prime }+E^{(temporal)}_{t^{\prime }}+E^{(instance)}_{u}+E^{(shot)}_{c_{u}}+b$
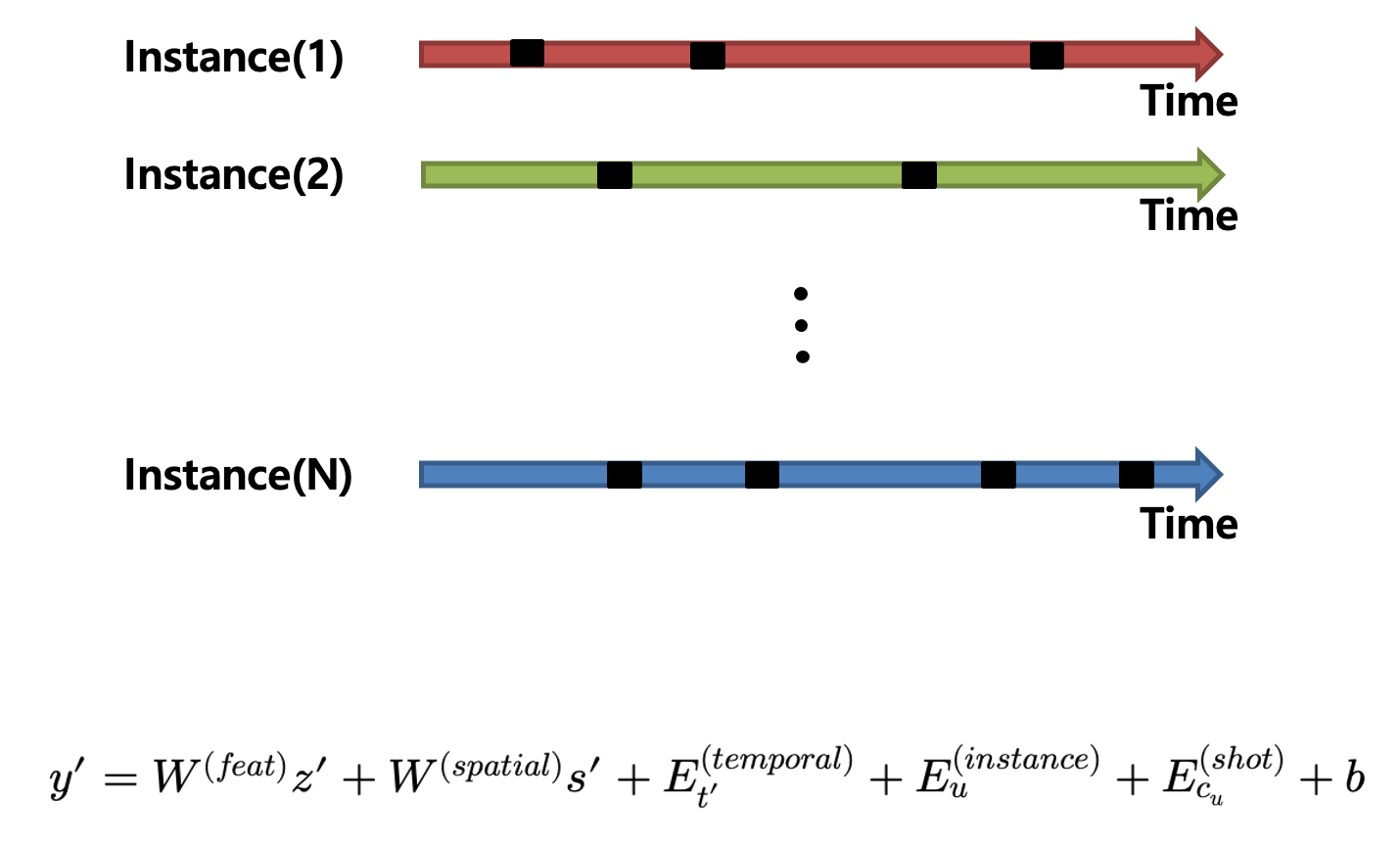
여기서 $W^{(feat)}$와 $W^{(spatial)}$은 z와 s를 768차원의 벡터로 projection 시켜주는 Linear Layer라 보면 됩니다.
$E^{(temporal)}$와 $E^{(shot)}$은 positional embedding으로 시간에 대한 정보를 처리하고 있으니 순서에 대한 처리를 진행하고 있습니다.
마지막으로 instance-level의 learnable 한 embedding을 해주고 있습니다. 목적 자체는 instance 끼리 구별력을 가질 수 있도록 하기 위함이라고 합니다.
기본 base로 사용되는 모델은 VideoBert라고 합니다. VideoBert를 읽어보진 않아서 자세히 설명을 드릴 수 없지만 최종적으로 여러 개의 attention Layer를 거치면서 나오는 output $V^{[CLS]}$는 video level의 representation vector라 생각하시면 됩니다.
이 output vector를 가지고 각각 end-task에 맞는 head를 붙이는 것으로 다양한 down stream task를 수행할 수 있다고 합니다. 하지만 down stream task로 바로 fine-tuning을 시키는 것보다 Self-supervised 방식으로 사전학습을 시키고 transfer learning을 시키는 것이 좀 더 Generalization 관점에서 좋다고 합니다.
모델의 자세한 구조나 forwarding이 어떻게 되는지를 논문에서 설명해주지도 않고 별다른 그림이 없어서 사실 별로 상상이 안 가기는 합니다. 핵심은 비디오 데이터를 새로운 방식으로 encoding 하였고, 그 motivation은 비디오의 존재하는 instance 끼리의 상호작용을 모델링하기 위함이라 볼 수 있습니다.
Self-Supervision
그렇다면 이제 Self-Supervision을 어떻게 제공하여 사전학습을 하는지 알아보도록 하겠습니다.
두 가지의 pretext-task로 사전학습이 진행됩니다.
Masked-Instance Prediction
간단합니다. 특정 instance에 해당하는 feature를 지우고 instance의 종류를 예측하게 만드는 것입니다. instance 간의 상호작용을 더욱 잘하기 위해서 진행한다고 보면 될 것 같습니다. classification 문제이므로 cross entropy loss를 사용하면 간단히 진행할 수 있습니다. feature를 어떻게 지우냐면 80%의 확률로 learnable 한 embedding vector로 변경하거나, 10%의 확률로 그냥 random 하게 생성하거나 10%의 확률로 그대로 유지하는 식으로 처리했다고 합니다. BERT에서 사용하는 방식 그대로 사용했다고 합니다.
예를 들어 어떤 object가 있어야 하는지, 혹은 이 사람이 무엇을 할지 masked region에 대해서 예측하는 것은 사람에게 쉽지만 이를 Machine이 처리할 수 있도록 하기 위해 즉, instance끼리의 semantic 한 interaction을 더욱 잘 인코딩하게 만들어줄 수 있습니다.
기존의 Self-Supervised 방식은 이러한 long-term pattern 즉, instance끼리의 interaction을 목표로 한 학습이 아니라 view-point, scale, occlusion과 같은 spatial representation에 robust 하게 작동할 수 있도록 만드는 식의 학습이 대부분이었다고 합니다.
Span Compatibility prediction
여기서는 Contrastive Learning을 통해서 representation learning을 합니다. 여기서 positive 하다는 것은 compatible이라고 표현하는 데 두 비디오가 compatible 하기 위해서는 같은 장면으로부터 왔거나, 바로 이어지는 장면이어야 한다 이렇게 정의하고 있습니다.
예를 들어 'wedding ceremony'는 'party'나 'dinner'와 좀 더 compatible하지 'camping'이나 'wrestling'과는 compatible 하지 않습니다. 흔히 representation learning에서 많이 하는 contrastive 방식으로 사전학습을 진행하고 있고 compatible의 정의는 비교적 직관적인 것 같습니다.
헤드를 하나 추가해서 $v=h^{(compact)}(v^{[CLS]})$ 이렇게 vector를 projection 시켜주고 있고, 학습 자체는 InfoNCE Loss를 통해 진행할 수 있습니다.
- $l^{(compact)}(v,v^{+},v^{-})=-log\left( \frac{e^{(v\cdot v^{+})}}{e^{(v\cdot v^{+})+\sum^{N-1}_{n=0} e^{(v\cdot v^{-})}}} \right) $
두 가지 Self-supervised 방식의 사전학습을 알아보았습니다. 간단하면서도 직관적이기 때문에 이해에 별다른 어려움을 없을 것 같습니다.
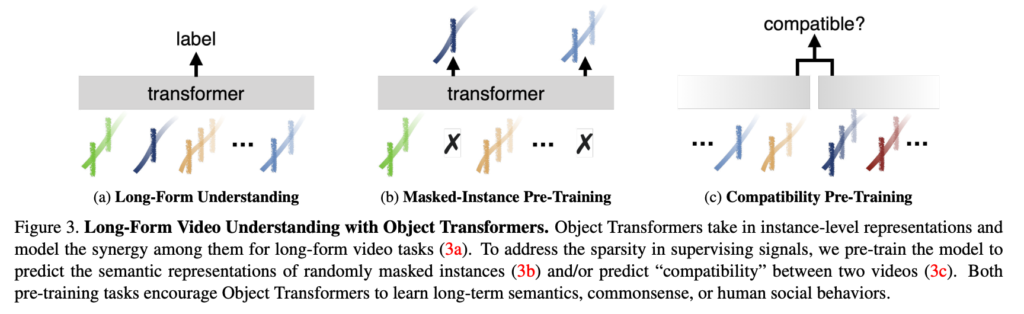
그림 (b)를 보면 몇몇 instance를 가려놓고 이 instace의 종류를 예측하는 Masked-Instance 방식을 보여주고 있고, 그림 (c)를 보면 두 비디오를 놓고 compatible여부에 대한 contrastive learning으로 학습이 됩니다.
Experiments
새로운 데이터셋에 대한 9가지 down stream task에 대한 benchmarking을 제공합니다. 이를 통해 기존의 short-form based 방식의 방법론과의 차이를 비교하여 본 논문에서 제안된 방식의 우수성을 보여주고 있습니다.
9가지의 down stream task는 classification 혹은 regression 문제로 분류할 수 있는데 classification 같은 경우는
- 비디오에서 나타나는 사람들 간의 관계를 예측하는 Relationship
- 비디오에서 나타나는 사람이 말하는 화법을 예측하는 Way of Speaking
- 비디오의 장면의 장소를 예측하는 Scene/Place
- 비디오의 영화감독을 예측하는 Director
- 비디오의 장르를 예측하는 Genre
- 비디오의 작가를 예측하는 Writer
그다음으로 Regression에 해당하는
- 비디오의 좋아요 비율을 예측하는 Like ratio
- 비디오의 조회수를 예측하는 View Count
- 비디오의 생성 날짜를 예측하는 Year
등으로 총 9가지의 task로 정의가 되어있습니다. 정말 의미가 있는지 의심이 드는 것도 있지만 그래도 비디오를 이해하는 데 있어 다양하면 다양할수록 좋다고 생각할 수 있을 것 같네요.

본 논문에서 제안된 Object Transformer가 writer와 year을 제외한 task에서는 모두 가장 높은 성능을 보여줍니다. 사실 writer나 year 같은 경우는 instance 간의 interaction을 그다지 필요로 하는 task가 아니다 보니 좀 낮은 성능을 보여주는 것 같습니다.
하지만 다른 모든 task에서 가장 좋은 성능을 보여주니 long-term modeling의 중요성을 입증한 듯싶네요.
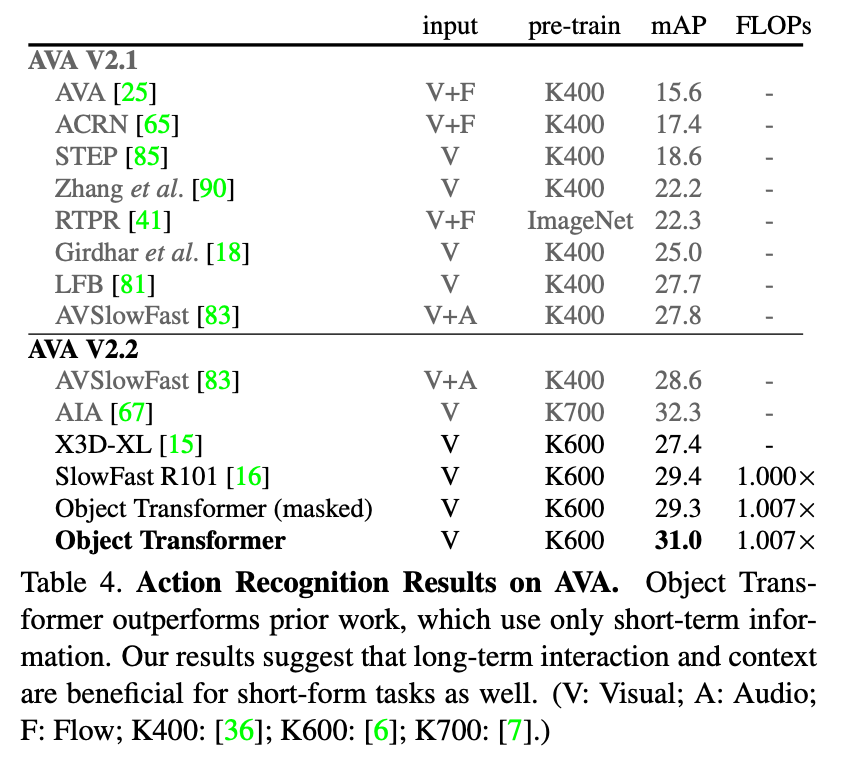
AVA라는 action recognition에서 사용되는 공개된 데이터셋에 대해서도 비교실험을 진행합니다. action recognition 같은 경우는 short-form video task라 볼 수 있는데 여기서도 제안한 방식을 도입하면 성능 향상을 확인할 수 있다고 합니다. short-form task에서도 long-form pattern을 학습하도록 하는 식의 접근이 먹힌 것이 꽤나 인상적인 결과인 것 같습니다.
이를 통해 제안한 방식이 long-form에서만 먹히는 게 아니라 short-form에서도 먹힌다는 것을 보여 방법론의 Generality 역시 입증한 것 같습니다.
다만 AVA에서만 실험을 보여주는 것은 조금 아쉬운 부분인 것 같네요.
Conclusions
아마 Long-form 비디오 연구의 서막을 개시한 논문인 것 같습니다. 인용된 논문을 찾아보니 벌써 Facebook이 Long-form 비디오에 대한 후속 연구를 진행하고 arXiv에 올린 것 같습니다.
핵심은 비디오 데이터를 바라보는 데 있어 새로운 시각을 제안하였고, 이를 적절하게 학습시킬 수 있는 Self-Supervised 기반의 framework를 제안하였습니다.
연구의 선두주자의 느낌이 나는 것처럼 새로운 데이터셋을 제안하였고 이에 대한 benchmarking을 제시한 논문으로 굉장히 좋은 논문인 것 같습니다.
역시나 문제 정의를 잘하는 것은 굉장히 중요한 것 같고, 언젠가 이런 연구를 해볼 수 있는 날이 오면 좋을 것 같습니다.



