Before Review
object detection 관련 주제로 Review를 다루게 됐습니다.
Focal Loss 같은 경우는 제가 학부 연구생 인턴을 진행할 때 Pedestrian Detection 개선 방법론으로 간단하게 알아만 봤던 주제인데, 이번 Review를 통해서 기존의 One-Stage Detector가 가지고 있던 문제점들이 어떤 식으로 개선이 됐는지 파악할 수 있게 되었습니다.
Review 시작하도록 하겠습니다.
Introduction
이 논문이 발표되는 시기에는 R-CNN 계열의 two-stage detector가 정확도 측면에서는 좋은 성능들을 보여주고 있었습니다. 이와 대비해서 one-stage detector는 two stage detector와 비교했을 때는 더 빠르고 간단한 구조를 보여주지만 , two-stage에 비해서는 낮은 정확도를 보여주고 있었습니다.
본 논문에서는 one-stage detector의 정확도가 낮은 이유를 극단적인 foreground – background class imbalance 문제로 인해 발생한다라고 주장하고 있습니다.
이 imbalance 문제가 무엇이냐면 쓸모없는 background box들이 one stage detector에는 너무 많다는 점입니다.
이러한 box들이 너무 많아서 학습 과정을 압도해버리는 점이 one stage detector의 문제라고 얘기하고 있습니다.
이러한 점을 해결하기 위해서 본 논문에서는 Cross-Entropy Loss를 조금 수정하는 방식으로 접근하고 있는 데 , 핵심 아이디어는 분류가 얼마나 잘 되는지에 따라서 가중치를 부여해 학습을 진행하는 것입니다.
뒷부분에서 자세히 설명하겠지만 , 결국 이러한 방식은 좀 더 hard negative 한 sample들에 더 높은 가중치를 줘서 , 집중적으로 학습시키고 , easy negative들이 (background) 학습을 overwhelm 하는 상황을 방지해준다고 합니다. 사실 , 여기까지 읽어 봤을 때는 뭔가 hard negative mining으로도 충분히 해결 가능한 것이 아닌가 라는 의문이 들긴 하지만 계속해서 읽어보도록 하겠습니다.
참고로 이러한 방식을 평가하기 위해 Retinanet이라는 Feature Pyramid Network(FPN) 계열의 새로운 Detector를 설계했다고 합니다.
정리하자면 본 논문에서는 Two – stage Detector와 견줄만한 혹은 능가하는 One – Stage Detector를 고려하고 싶었고 , 이 상황을 타개하기 위해 Class – Imbalance라는 문제를 정의했으며 , 이러한 문제점을 해결할 수 있는 Focal Loss를 도입해 One Stage Detector를 가지고 SOTA를 찍었다는 것이 본 논문의 Contribution이라고 합니다.
Class Imbalance
사실 , two-stage Detector에 대해서는 아는 게 별로 없어서 , 본 논문에서 서술하고 있는 Two-Stage Class Imbalance 문제에 대해서는 잘 이해를 하지 못했습니다.
단순하게 내용만 받아들인다면 , two-stage Detector의 Selective Search , EdgeBoxes , DeepMask , RPN 등등의 구조는 candidate object의 위치수를 빠르게 좁힘으로써 , background sample들의 필터링이 많이 이루어진다고 합니다.
이와 반대로 One-Stage Detector 같은 경우는 우선 candidate box들을 많이 만들어내야 하다 보니 , 이러한 점으로 인해 BackGround sample들이 많이 생성되고 Class-Imbalance 문제가 심해지게 됩니다.
그래서 앞에서 살짝 언급했다시피 , 본 논문에서는 이러한 상황을 타개하기 위한 새로운 Loss 함수를 도입합니다.
이 새로운 Loss함수는 잘 분류되는 case에 대해서는 Loss를 0으로 수렴시키면서 영향력을 약화시키고 , 좀 더 어려운 case에 대해서 집중적으로 다루도록 해주는 Loss입니다.
사실 본 논문에서 제시하는 Focal Loss의 정확한 형태를 따라 하는 것은 중요한 것이 아니고 , 위에서 설명한 아이디어를 적용할 수 있는 형태라면 비슷한 결과를 얻어낼 수 있다고 합니다.
그렇다면 이제 , 계속해서 언급했던 Focal Loss가 무엇인지 알아보도록 하겠습니다.
Focal Loss
아까 Introduction 부분에서 Class Imbalance 문제는 Hard Negative mining으로도 해결 가능한 거 아닌가라는 의문을 가졌는 데 , Focal Loss 도입부에서 이러한 언급이 간단하게 나와있습니다.
Class Imbalance 문제를 Hard Negative Mining으로도 해결할 수 있지만 , Focal Loss를 도입하면 자연스럽게 Hard Negative Mining을 적용시켜주는 방식이라 , 좀 더 좋은 접근 방식으로 소개하고 있는 것 같습니다. 사실 아직까지는 느낌이 확 오지는 않아서 후에 Experiments 부분을 읽을 때 Focal Loss를 도입했을 때와 , 도입하지 않고 Hard Negative mining만 적용했을 때의 실험 결과가 있다면 주의 깊게 볼 필요가 있을 것 같습니다.
- Binary Cross Entropy Loss
y에 해당하는 값은 1 , -1 값 둘 중 하나이며 , p는 모델이 class label을 y=1 이렇게 예측할 확률입니다.

Binary Classification이므로 다음과 같이 $ p_{t} $ 라는 값을 정의할 수 있습니다.
y = 1 일 때 P , 그게 아니라면 1 – P 이런 식으로 베르누이 시행으로 표기할 수 있습니다.
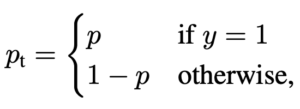
결국에는 아래와 같이 BCE Loss를 다음과 같이 표기할 수 있습니다.
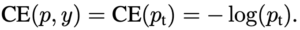
이렇게 고안된 BCE Loss 같은 경우는 $ p_{t} $ > 0.5 인 즉 , 쉽게 분류할 수 있는 sample들이 만들어 내는 Loss값이 꽤 있다고 합니다. 본 논문에서는 이렇게 표현하고 있습니다.
" One notable property of this loss, which can be easily seen in its plot, is that even examples that are easily clas- sified (pt ≫. 5) incur a loss with non-trivial magnitude. When summed over a large number of easy examples, these small loss values can overwhelm the rare class. "
우리는 이러한 쉬운 Sample 들의 영향력을 감소시키고 싶기 때문에 이들이 만들어내는 Loss를 0에 가까이 설계하고 싶은 상황이고 , 다음과 같은 Scaling 과정을 통해 Focal Loss가 정의됩니다.
- Focal Loss Definition
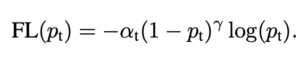
제가 계속해서 언급했던 아이디어만 상기시키고 있다면 단번에 이해할 수 있는 내용입니다.
- Easy sample이라면 학습에 별로 도움이 안 되는 친구이고 우리는 이 녀석의 Loss를 0에 가까이 보내버리고 싶다.
- Hard sample이라면 어려운 예제로 집중적으로 학습해야 하는 대상으로써 이 녀석의 Loss를 키움으로써 더 커진 Gradient들을 통해 학습의 효과를 키우고 싶다.
이러한 개념이 $ (1-p_{t})^{\gamma } $ 여기에 녹아져 있습니다.
$ p_{t} $ 이 녀석이 크다는 의미는 분류가 쉬운 예제이므로 $ (1-p_{t})^{\gamma } $ 값은 작아지게 되므로 Loss는 0에 가까워지게 됩니다.
반대로 $ p_{t} $ 이 녀석이 작다는 의미는 분류가 어려운 예제이므로 $ (1-p_{t})^{\gamma } $ 값은 작아지게 되므로 Loss는 기존 값보다 커지게 됩니다.
딱 원하는 상황이 나오게 됐습니다. 이러한 메커니즘으로 극단적으로 쉬운 예제들은 Loss가 거의 0으로 수렴하게 되며 , Gradient들이 작아지게 되고 학습에 큰 영향을 주지 않습니다.
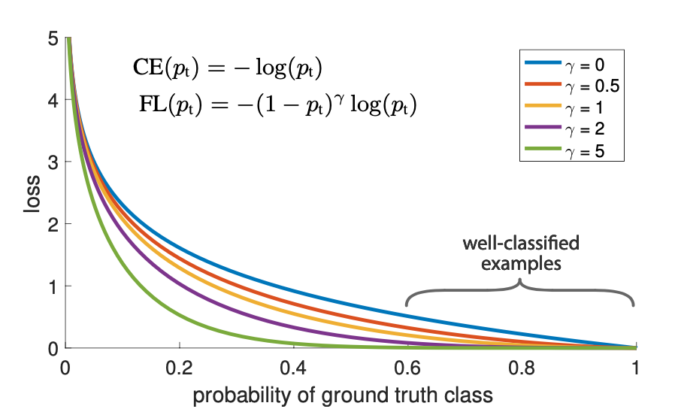
그래프를 확인했을 때 파란색 그래프($ \gamma =0 $)인 그래프가 기존 Cross Entropy Loss에 해당하며 , well-classified example들 쉬운 예제들에 대해서도 Loss값이 꽤나 존재하는 것을 확인할 수 있고
다른 그래프들 Focal Loss가 적용된 그래프들은 well classified example들에 대해서는 Loss값이 거의 없는 것을 확인할 수 있습니다.
Focal Loss는 이렇게 간단하게 알아볼 수 있었습니다. 이제 본 논문에서 고안된 RetinaNet에 대해서 간단하게 알아보고 Experiment들을 살펴보도록 하겠습니다.
RetinaNet Detector
본 논문에서 Focal Loss를 평가하기 위해 고안된 RetinaNet은 forward 과정에서는 ResNet을 사용하고 있으며 Backbone으로는 FPN 구조를 사용하고 있습니다.
FPN 구조가 무엇인지 기억이 잘 안 나서 찾아봤는 데 간단히 설명드리면 , 상단 layer의 feature map과 하단 layer의 feature map들을 skip connection을 통해 multi-scale detection task를 수행해주는 구조라고 보시면 되겠습니다.
그림을 확인하시면 이해에 더욱 도움이 될 것 같습니다.
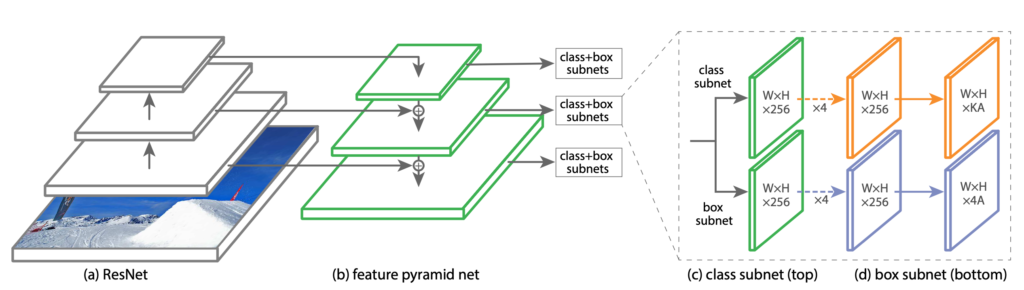
FPN 구조에 대해서 잘 알고 있었다면 본 Network를 이해하는 데 큰 어려움은 없을 거라 생각이 듭니다.
그리고 Classification과 Bounding Box Regression에 대한 각각의 Subnet으로 나뉘게 됩니다.
Experiments
먼저 그래프를 확인해보면 다음과 같은 데 살펴보자면
x 축은 inference time으로 작을수록 빠르다는 의미이며 , y축은 COCO AP로 정확도로 생각하시면 되겠습니다.
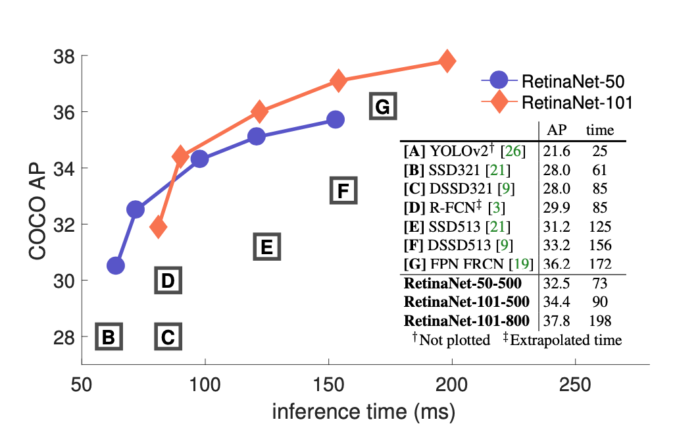
Table로도 구체적인 성능을 확인할 수 있으며 역시나 SOTA를 달성하고 있습니다.
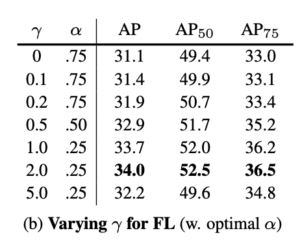
참고로 최적의 $ \gamma $ 와 $ \alpha $은 실험을 통해 찾았다고 합니다.
제가 확인해보고 싶었던 실험 결과도 Reporting이 되어 있었습니다. 바로 Hard Negative mining vs Focal Loss입니다.
결론부터 말하면 Focal Loss를 도입하는 게 더 성능이 좋다고 합니다.
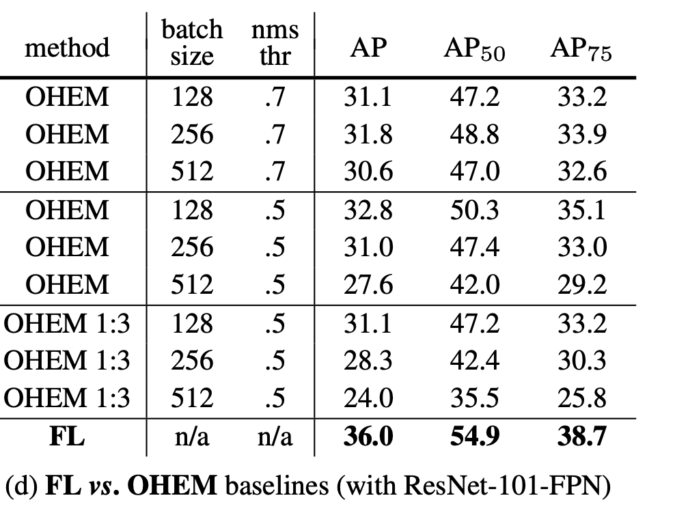
OHEM은 online hard example mining의 준말로 , 다양한 조건으로 OHEM을 진행했을 때와 Focal Loss를 사용했을 때 성능을 비교해봐도 Focal Loss가 더 좋은 성능을 보여주고 있습니다.
개념적으로는 둘 다 비슷한 거 같지만 , 본 논문에서 강조하는 둘의 차이점은 다음과 같습니다.
Focal Loss는 easy sample들의 영향력을 줄이는 것이지 , 아예 제외시켜버리는 것은 아닙니다. 하지만 OHEM은 easy example들에 대해서는 제외를 시켜버리는 구조로써 이러한 차이점이 있다고 합니다.
사실 , 저렇게 파악해도 뭔가 찝찝한 기분이 들지만 , 우선 이 정도로만 파악해두고 훗날 실력을 쌓고 다시 한번 읽게 됐을 때 새로운 insight를 도출할 수 있을 거라 기대하면서 마무리하겠습니다.
Conclusion
예전에 Detection 관련 Project를 할 때 궁금해했던 Focal Loss에 대해서 다뤄보게 된 리뷰였으며 추가적으로 Detection에 대한 간단한 복습까지 할 수 있었습니다. Focal Loss를 살펴본 결과 간단한 아이디어 이면서도 좋은 Performance를 보여주는 것을 확인할 수 있었습니다.



