Before Review
올해 해보고 싶은 연구 방향 중 하나가 바로 DETR을 활용한 object-centric representation입니다.
Object Detection을 하겠다는 의미가 아니라 object 끼리의 상호작용을 표현할 수 있는 feature representation을 고도화하고 싶고 이를 활용하여 다양한 video understanding task에 접목시키고 싶은 것이죠.
DETR을 읽으면서 꽤나 인상 깊게 읽었습니다. 공감이 되는 부분도 많았고요.
Introduction
Object Detection은 전통적으로 컴퓨터 비전 학계에서 가장 근본적으로 다루어진 문제입니다.
근본적으로 Object Detection은 이미지에 존재하는 bounding box와 그에 해당되는 category label의 집합을 예측하는 문제라고 볼 수 있습니다. 기존 object detection 연구들은 딥러닝을 접목시켜 괄목할만한 성능 향상을 이끌어낸 것은 맞지만 거기에는 굉장히 복잡한 처리 방식이 존재했습니다.
Detection 코드를 직접 까보신 분들은 알겠지만, anchor box를 만들고 NMS를 처리하는 부분이 굉장히 복잡하게 설계되어 있습니다. 사실 이러한 부분은 학습이 되는 구조도 아니면서 performance에는 많은 영향을 끼치게 됩니다. 따라서 진정한 의미의 end-to-end 방식이 아니라고 볼 수 있죠.
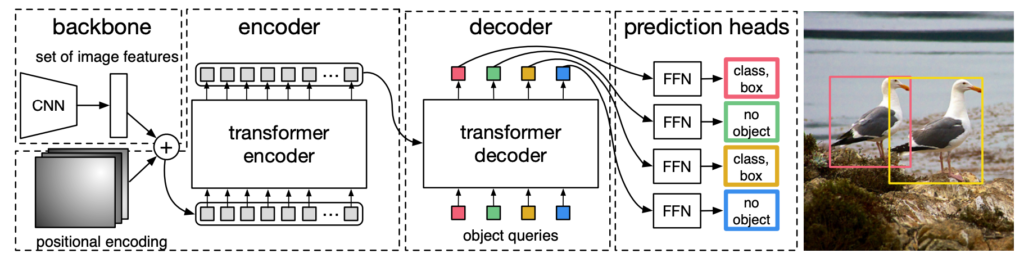
본 연구는 진짜 End-to-End Object Detection을 제안합니다. 미분 불가능한 연산은 일절 존재하지 않는 DETR(DEtection TRasnformer)을 제안합니다. 우선 기존 Faster RCNN과 이번에 제안하는 DETR의 전체적인 흐름을 한번 비교해 보도록 하겠습니다.
아래의 그림은 Meta AI 블로그에서 가져온 그림입니다.
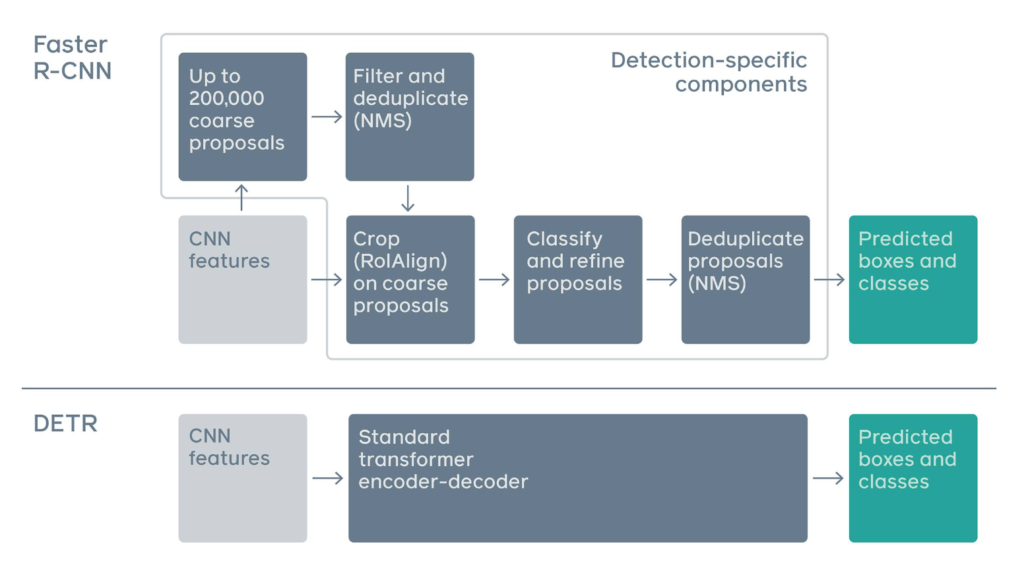
Faster R-CNN과 DETR의 구조를 비교하는 그림입니다. 해당 구조에 대해서 자세하게 말씀드릴 것은 아니고 느낌만 조금 보도록 하겠습니다.
Faster R-CNN의 코드를 까본 사람을 알겠지만 anchor 만들고 roi pooling 하고 NMS 때리고 하는 과정들이 정말 복잡하게 코딩되어 있어요. 어떤 동작은 CPU에서 작동하고 어떤 동작은 GPU에서 작동하고 아주 그냥 잡 기술의 끝판왕입니다. 선행 연구를 폄하하려고 하는 건 아니지만 그래도 공부하거나 활용하는 입장에서 이해하기 꽤나 어려운 것은 분명한 사실입니다.
그에 반해 제안하는 DETR 구조는 정말 간단합니다. 사전학습된 ResNet을 가지고 CNN feature를 추출하고 Transformer Encoder-Decoder 구조를 활용하여 detection 결과를 예측합니다. 이게 전부입니다. 본 논문에서는 prior knowledge (e.g., anchor, NMS)와 같은 component 없이 굉장히 simple한 파이프라인을 구축했다는 것 이죠.
기존 구조는 성능을 위해 고려해야 할 것들이 많았지만 제안하는 DETR은 그러한 복잡한 설계 없이도 경쟁력 있는 성능을 달성하였습니다. 물론 여기서 경쟁력 있는 성능이라 표현한 이유는 모든 지표에서 완벽하게 기존 베이스라인을 넘어서지는 못하고 부분적으로 아쉬운 모습도 있기 때문입니다.
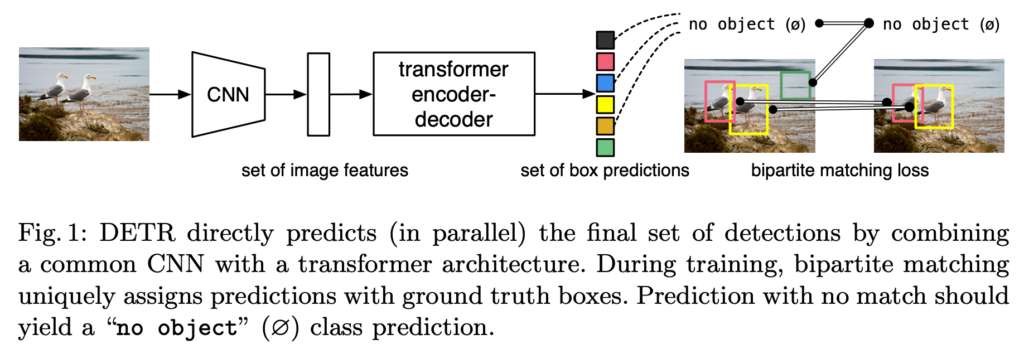
위의 그림은 제안하는 DETR의 간단한 구조도입니다. 사실 저게 다이기도 해요. 저도 논문을 보면서 느꼈지만 정말 복잡한 detection framework를 굉장히 단순화시켰구나 느꼈습니다.
제안하는 DETR의 핵심은 두 가지입니다. 바로 1) Transformer, 2) Bipartite matching loss로 정리할 수 있죠.
Transformer는 우리가 알던 그 Transformer가 맞습니다. 저는 논문을 읽기 전에는 그 ViT를 생각하고 있었는데 그냥 NLP에서 사용하는 Transformer였습니다. Bipartite matching loss는 헝가리안 알고리즘과 관련이 있습니다. 결국 Object Detection은 Set Prediction 문제인데 여기서 Transformer를 타고 나온 예측 set과 실제 정답 set 간의 일대일 매칭을 수행합니다. 물론 cost가 가장 낮아지는 matching을 찾는 것이 목표입니다. 이를 수행하는 것이 bipartite matching loss입니다.
방법론적인 얘기는 조금 뒤에서 하도록 하고 DETR의 contribution에 대해서 정리하고 마무리하겠습니다. DETR은 기존 object detection의 복잡한 파이프라인을 transformer 구조와 bipartite matching loss를 활용하여 굉장히 단순화시켰습니다. 또한 제안하는 구조가 단순히 detection 뿐 아니라 다른 task (e.g., panoptic segmentation)에서도 좋은 성능을 보여줍니다.
마지막으로 기존 Faster R CNN 베이스라인대비 경쟁력 있는 성능을 달성하면서 진정한 end-to-end object detection의 포문을 열었습니다.
The DETR model
Object detection set prediction loss
우선적으로 DETR은 고정된 $N$개의 prediction만 반환합니다. Transformer의 Decoder에서 나온 예측이 $N$개의 object만 처리할 수 있다는 의미입니다. NMS와 같은 알고리즘을 사용하지 않기 때문에 예측 결과가 이미지마다 다르지 않고 고정되어 있습니다.
통상적으로 $N$은 이미지에 존재할 수 있는 객체의 개수 보다 더 큰 숫자를 사용합니다.
자 그럼 일단 Loss를 한번 가정해 보도록 하겠습니다.
Decoder를 통해서 $N$개의 prediction이 나왔습니다. 기본적으로 $N$이 실제 이미지에 있는 object의 개수보다 많기 때문에 ground-truth는 그 차이만큼 $\phi$ (no object)로 패딩처리 됩니다.
그리고 우리는 여기서 헝가리안 알고리즘을 통해 ground-truth와의 최적의 matching $\hat {\sigma}$을 탐색합니다.
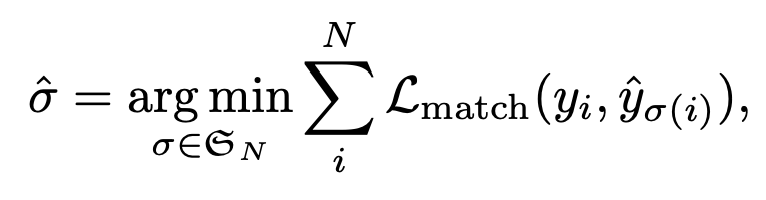
우선 헝가리안 알고리즘을 활용하기 위해서는 matching cost가 정의되어야 합니다. Prediction과 GT를 비교할 때 cost를 의미하겠죠. 우선 임의의 $i$번째 element에 해당하는 ground truth는 아래와 같이 정의됩니다.
- $y_{i}=(c_{i}, b_{i})$
여기서 $c_{i}$는 category label로 경우에 따라서는 $\phi$ (no object) 일 수 있습니다. 그리고 $b_{i} \in [0,1]^{4}$는 박스 좌표겠네요.
그리고 우리가 헝가리안 알고리즘 과정에서 $i$번째 element에 ground truth와 matching 되는 $\sigma(i)$번째 예측값에 대해서는 아래와 같이 표기합니다.
- $\hat {p}_{\sigma(i)}(c_{i})$ : $c_{i}$에 대한 confidence score입니다. 분류를 위한 확률이라 생각하시면 됩니다.
- $\hat {b}_{\sigma(i)}$ : 예측 box의 좌표입니다.
이러한 notation을 바탕으로 matching cost는 아래와 같이 정의됩니다.
- $\mathcal {L}_{match} (y_{i},\hat {y}_{\sigma (i)} )=-\mathbb {1}_{\left\{ c_{i}\neq \phi \right\} } \hat {p}_{\sigma (i)} +\mathbb {1}_{\{ c_{i}\neq \phi \} } \mathcal {L}_{box} \left( b_{i},\hat {b}_{\sigma (i)} \right) $
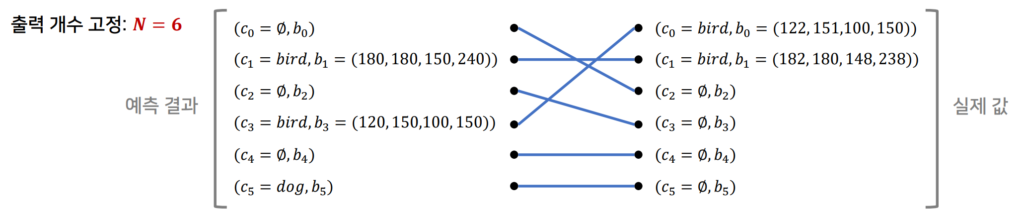
결국 $\phi$ (no object)를 제외하고 confidence score에 대한 term과 box 좌표에 대한 term의 선형 결합으로 이루어져 있습니다. 여기서 matching cost의 경우 confidence score에 대해서는 log-probability가 아니라 그냥 probability를 사용해 주는 것이 경험상 더 성능이 좋다고 합니다.
자 이렇게 해서 matching cost가 정의 됐습니다. 여기서 matching cost는 전체 Loss가 아닙니다. 최적의 matching을 위한 cost이지 최적의 matching을 찾았다면 다시 최종 loss를 계산해야 합니다. 본 논문에서는 Hungarian loss라고 정의합니다.
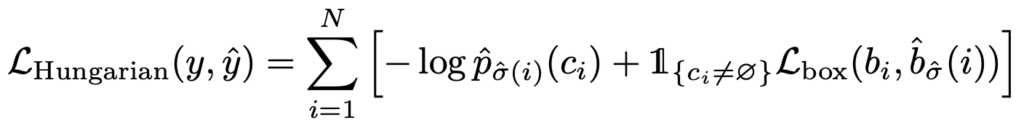
여기서 이제 $\hat {\sigma}$는 앞선 matching cost를 가장 작게 만드는 최적의 할당이라 보시면 됩니다. 여기서 구현상 디테일을 조금 설명드리면 $c_{i}=\phi$인 no object 상황이 학습을 압도하는 것을 방지하기 위해 loss를 10만큼 나누어 scale을 조금 조정했다고 합니다. 또한 matching cost와 달리 log-probability를 사용해주고 있습니다
Bounding box loss
다음으로 $\mathcal {L}_{box}(\cdot)$은 당연히 박스 좌표를 보정해 주는 term입니다. 기존의 detector들은 anchor 박스를 설정하고 gt box와의 차이를 바탕으로 학습을 진행했는데 여기서는 그게 아니라 box prediction을 directly 하게 진행하고 있습니다.
하지만 여기서 박스 스케일에 따라 loss가 서로 다른 scale을 가지기 때문에 이를 완화하기 위해 scale invariant 할 수 있는 generalized IoU loss를 사용했다고 합니다.
- $\mathcal {L}_{\text {box} } (b_{i},\hat {b}_{\sigma (i)} )=\lambda_{\text{iou} } \mathcal{L}_{\text{iou} } (b_{i},\hat{b}_{\sigma (i)} )+\lambda_{\text {L1} } \parallel b_{i}-\hat {b}_{\sigma (i)} \parallel_{1} $
L2 Loss 혹은 Smooth L2 Loss를 많이 사용하는 것으로 알고 있는데 여기서 L1 Loss를 사용한 이유에 대해서는 따로 서술하지 않고 있습니다.
DETR architecture
Loss는 위에서 다뤘으니 이제 구조에 대해서 알아보도록 하겠습니다.
사실 구조적인 측면에서 어려운 부분은 전혀 없습니다. 다만 positional encoding 관점에서 디테일만 조금 신경 써주시면 될 거 같네요.
Backbone
ViT를 사용하는 것이 아니기도 하면 애초에 ViT가 나오기 전에 개제 된 논문이라 patch embedding이 아닌 CNN feature를 활용하여 Transformer의 입력으로 넣어줍니다.
여기서 CNN feature는 가장 널리 사용되는 ResNet50 혹은 ResNet101을 사용했다고 합니다.
- $x_{\text {img} }\in \mathbb {R}^{3\times H_{0}\times W_{0}} \rightarrow f\in \mathbb {R}^{C\times H\times W} $
이때 채널 $C$는 2048차원을 가지고 있으며 공간적 해상도는 32배 $(H, W=\frac {H_{0}}{32} ,\frac {W_{0}}{32} )$ 다운 샘플링 된다고 합니다.
Transformer encoder
Transformer encoder는 우리가 흔히 아는 Transformer encoder가 맞습니다. Backbone을 통해서 얻은 CNN feature를 그대로 사용해 주는 것은 아니고 1 by 1 Convolution을 통해 channel dimension을 수행합니다.
- $f\in \mathbb {R}^{C\times H\times W} \rightarrow z\in \mathbb {R}^{d\times H\times W} $
그리고 여기 공간적 구조를 1d로 flatten 하여 encoder에 얻을 수 있는 형태로 reshape 해 줍니다.
- $z\in \mathbb{R}^{d\times H\times W} \rightarrow z\in \mathbb{R}^{d\times HW} $
이때 기본적인 transformer encoder는 permutation-invariant 합니다. 왜냐하면 self-attention 연산이 permutation invariant 하기 때문이죠. 하지만 여기서는 이미지의 locality에 대한 순서가 중요하기 때문에 permutation-invariant 한 성질을 좀 죽여야 합니다.
그래서 매 attention layer마다 고정된 positional encoding을 더해줘서 이를 방지하고자 합니다.
Transformer decoder
Transformer decoder 역시 우리가 흔히 아는 Transformer decoder가 맞습니다. 하지만 여기서 달라지는 부분이 조금 있습니다. 일단 여기서 $N$개의 object query를 사용합니다. 개념이 조금은 추상적일 수 있습니다.
우선 Transformer의 Decoder에서 Key, Value 값을 encoder의 출력으로 활용합니다. Key와 Value는 이미 앞선 CNN feature 들끼리의 dependency가 녹아져 있는 정보라 볼 수 있습니다. 이를 바탕으로 N개의 Object를 가정하고 복호화를 시도해야 합니다.
이를 위해서 저자는 학습 가능한 $N$개의 embedding을 object query로써 사용합니다. $N$개의 embedding이 서로 다른 object를 책임져주는 것이죠. 그리고 이 $N$개의 object query가 여러 개의 decoder layer를 거치고 나면 $N$개의 object에 대한 예측 값이 될 것이다라고 가정하는 것입니다.
이렇게 decoder를 거치고 나온 N개의 object feature를 활용하여 이제 Class와 Box 좌표를 예측하는 것이 다음 과정입니다.
Prediction feed-forward networks (FFNs)
마지막 FC Layer는 간단합니다. 3-layer perceptron with ReLU라고 하네요.
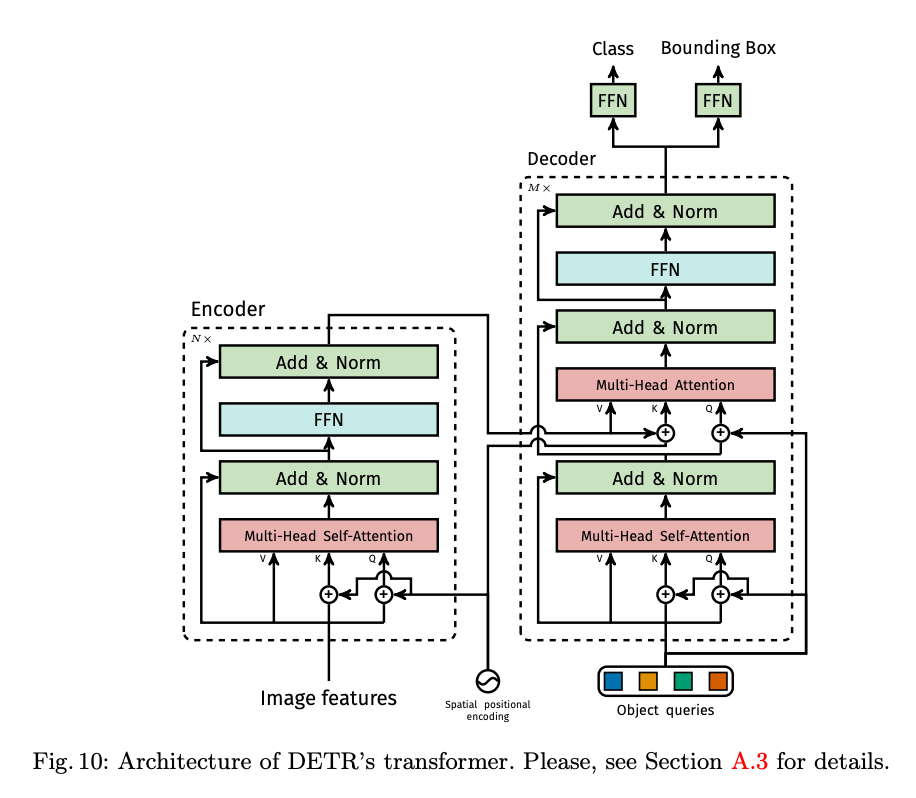
따라서 Transformer encoder/decoder 그리고 FFN까지 합친 모든 구조는 위의 그림과 같습니다.
Auxiliary decoding losses
여기는 학습 과정에서의 디테일입니다. Decoder Layer가 여러 개 있을 텐데 중간중간 weight를 공유하는 FFN을 붙이고 loss를 전달해 주는 것이 성능이 더 좋다고 합니다.
약간 GoogleNet(?)이랑 비슷한 거 같습니다.
Experiments
실험은 COCO 2017에서 진행했다고 합니다. 학습 이미지 기준 평균 7개의 instance가 존재하고 최대는 63개의 instance가 존재한다고 합니다. $N$을 100으로 사용했기 때문에 놓칠 일은 없겠네요.
Comparison with Faster R-CNN
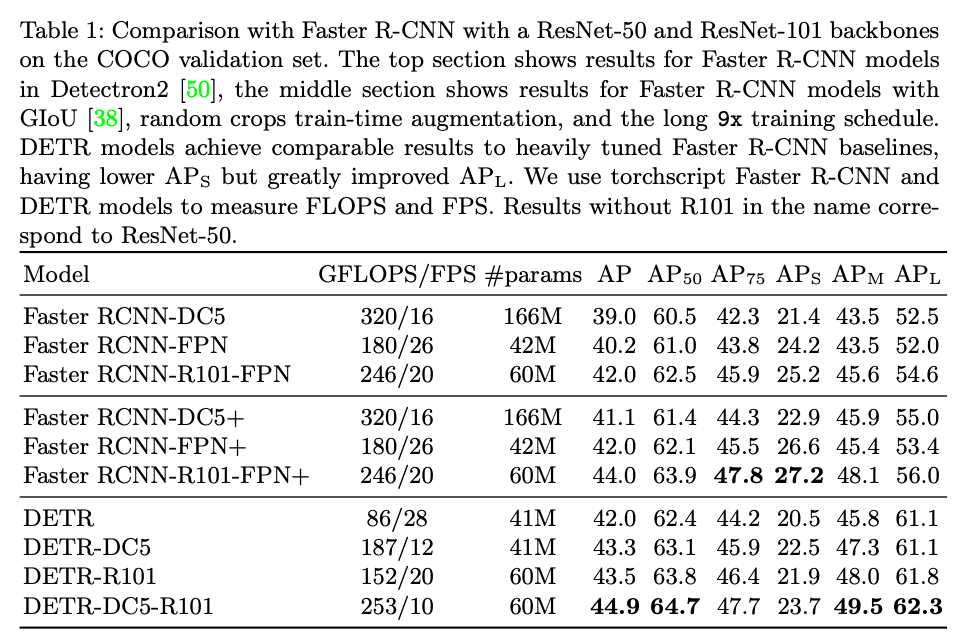
우선 Faster RCNN과의 비교입니다. Faster RCNN은 2015년 나온 이후로도 지속적인 발전을 거쳐 성능을 많이 올린 상황입니다.
이때 dilation convolution을 사용한 성능이 DC5로 표기되어 있습니다. 최종적으로 DETR-DC5-R101의 경우 $\text {AP}_{75}$나 $\text {AP}_{S}$를 제외하고는 모두 기존 베이스라인 대비 좋은 성능을 보여주고 있습니다.
대비되는 부분은 small에 대한 검출 성능과 large에 대한 검출 성능이 확실하게 차이가 나고 있습니다. 이러한 결과를 해석을 나름 해보자면
- ResNet의 가장 마지막 feature를 사용하기 때문에 detail에 대한 정보가 많이 손실되었다. 이는 FPN 구조를 사용하여 기존 Faster R CNN 같은 경우 보완을 해주고 있는데 DETR 지금 구조에서는 아직 고려가 되지 않은 상황입니다.
- Self Attention 연산은 Large Object에 대해서 더욱 이득을 보기 쉽다. Convolution에 비해 Receptive field로부터 자유로운 attention 연산이기에 큰 물체는 잘 잡지만 작은 물체는 attention 연산이 별로 도움이 되지 않는 것이죠.
물론 DETR이 20년도에 개제 된 연구이며 후속 연구(e.g., Deformable DETR)를 보면 small에 대한 성능도 많이 올라온 상황이긴 합니다.
Ablations
Number of Encoder Layers
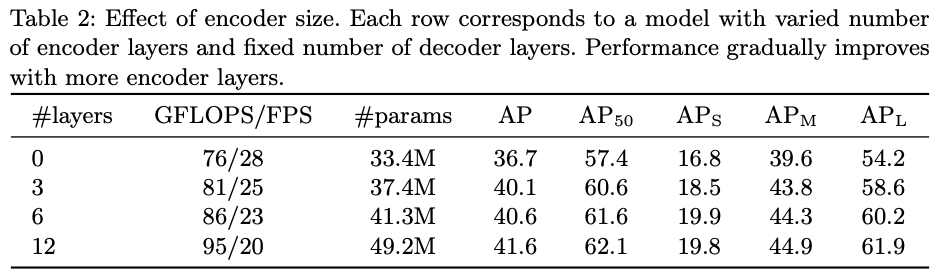
Encoder를 아예 사용하지 않은 상황에서 Layer의 개수를 늘려가며 비교한 실험입니다. 전체적인 AP에서는 3.9 drop이 발생하고 large 상황에서는 6.0 drop이 발생하고 있습니다.
전반적인 scene reasoning 상황에서 globa 한 정보를 capture 할 수 있는 encoder의 역할이 중요하다고 주장합니다.
Encoder Self-Attention

실제로 encoder가 무슨 역할을 하는지 살펴보면 결국 물체들을 구분하는 역할을 수행하게 됩니다. 학습을 마치고 나서 attention 상황을 보기 위해 그림에서 4개의 픽셀이 어느 부분에 attention을 주고 있는지 보여주고 있는 시각화입니다.
확실히 픽셀이 대응되는 물체와 높은 attention 가중치를 가지고 있어 물체를 서로 구분하는 모습을 보여주고 있습니다.
자기가 속해 있는 물체와 높은 상관관계를 가지는 것이 흥미롭습니다.
Number of Decoder Layers
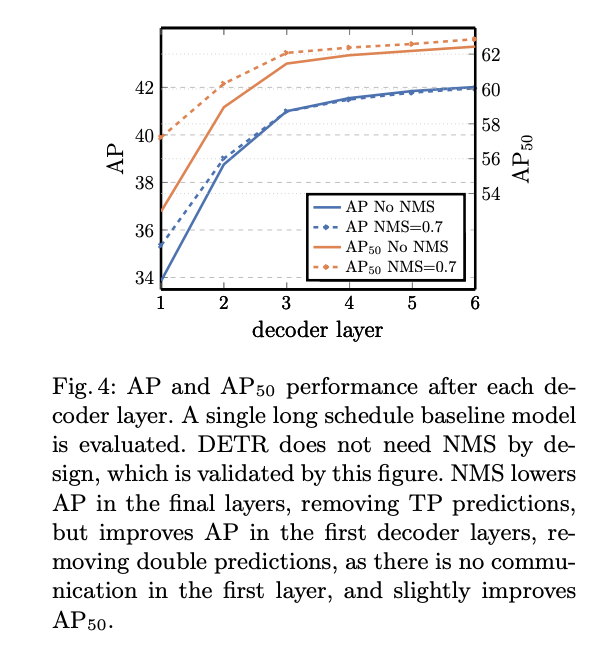
x축은 decoder layer의 개수입니다. 여기서는 NMS를 추가하는 실험을 진행하였습니다.
Decoder layer가 적을 때는 물체들을 잘 구분을 못해서 하나의 물체에 여러 개의 예측을 하려고 하는 경향을 보입니다. 즉, NMS를 통해 성능 이득을 보는 것이죠.
Decoder layer가 많을 때는 반대로 NMS를 한다고 해서 성능 이득이 거의 없습니다. 이는 이미 물체들을 잘 구분하고 중복되는 예측이 없다는 의미입니다.
Positional Encoding & Loss ablation
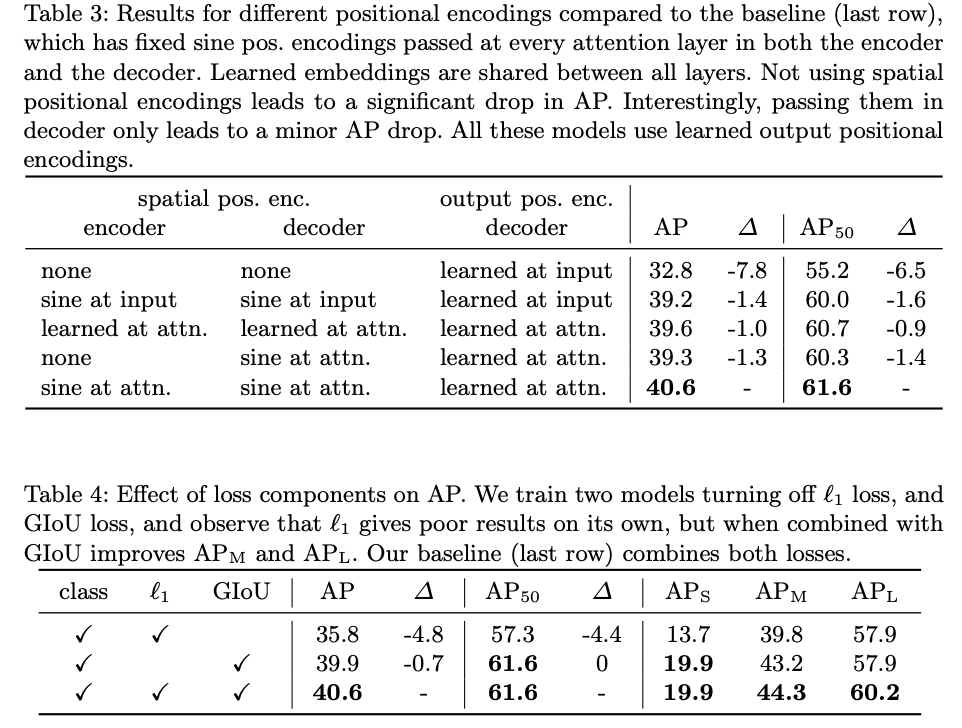
positional encoding 먼저 보도록 하겠습니다. 결론적으로 positional encoding이 중요한데 여기서 입력에 한 번만 해주는 것이 아니라 매 attention layer에 입력으로 넣을 때마다 해주는 것이 최종적으로 더 좋은 성능을 보여주고 있네요.
Loss ablation에서는 IoU의 역할이 중요한 것 같습니다.
Analysis

해당 시각화는 예측 박스에 대한 시각화입니다.
green에 대한 포인트는 작은 박스, red는 large horizontal, box는 large vetical box입니다.
이때 각 object query는 특정한 박스 크기에 대해 예측을 수행하며, 학습된 query가 object의 위치에 따라 다양하게 반응하는 모습을 보여주고 있습니다.
결국 object에 위치와 크기마다 반응하는 query가 다양하다고 보시면 될 거 같네요.
DETR for panoptic segmentation
panoptic segmentation은 instance + semantic segmentation이라 보면 됩니다. 제안하는 DETR 스타일의 구조를 바탕으로 panoptic segmentation에서도 나름 잘 작동하다는 실험을 보여주고 있습니다.

테이블을 보시면 모든 지표는 아니지만 DETR 구조가 panoptic segmentation에서도 꽤나 괜찮은 성능을 보여주고 있습니다.
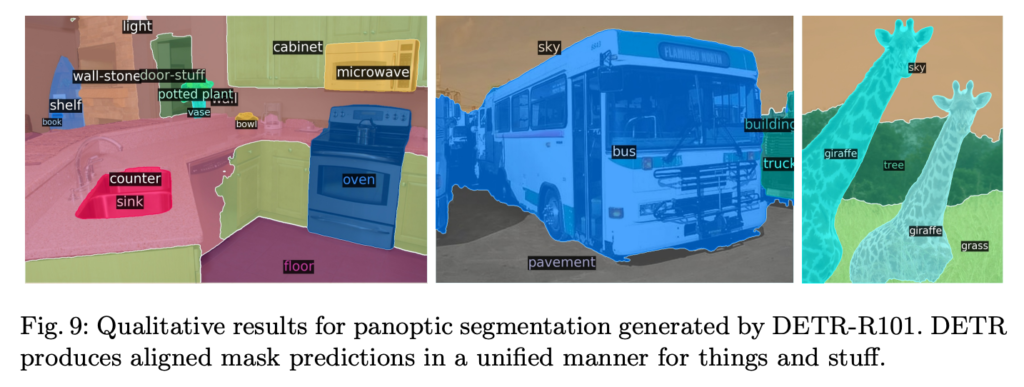
이쪽 task에 대한 정성적 결과는 처음 보다 보니 음 그래도 나름 잘 잡는 거 같네요..? 느낌적으로는ㅋㅋ
Conclusion
Object Detection은 복잡한 잡기술이 난무하는 연구로 알고 있었는데 해당 연구가 Transformer 구조를 바탕으로 나름 교통정리를 한 것 같습니다.
저는 앞으로 리뷰에서 DETR의 후속 연구 중 object detection에 집중하는 것이 아니라 DETR을 통한 object centric representation으로 다양한 머신 비전 문제를 푼 연구들을 찾아 follow up 하도록 하겠습니다.
리뷰 읽어주셔서 감사합니다.



