Before Review
이번 논문은 Video Scene Segmentation으로 읽게 됐습니다.
[2022 CVPR] Scene Consistency Representation Learning for Video Scene Segmentation 지난 리뷰에도 동일한 task에 대해서 다루었으니 관심 있다면 한번 살펴보시길 바랍니다.
Video Scene Segmentation 관련하여 카카오브레인, 서울대학교, 한양대학교에서 공동 연구를 한 논문이 나와서 읽어 보게 되었습니다.
리뷰 시작하도록 하겠습니다.
Introduction
영화와 같은 길이가 굉장히 긴 비디오를 AI system에게 이해하게 하는 것은 굉장히 어려운 일입니다. 보통 인간이 비디오를 이해하는 과정은 비디오를 meaningful unit으로 분할하고 이 unit 간의 relationship을 이해하는 식으로 진행됩니다.
결국 이런 관점으로 봤을 때 길이가 긴 비디오를 길이가 짧은 temporal segments로 분할하는 것은 high-level video understanding에 굉장히 중요한 작업이라고 볼 수 있습니다.
이러한 관점으로 많은 연구가 되고 있죠. 그중 Video Scene Segmentation은 시간 축에 대해서 Scene Boundary를 찾는 것이라 볼 수 있습니다. 본격적인 얘기를 하기 전에 여기서 사용되는 용어에 대해서 간단하게 정리하도록 하겠습니다.
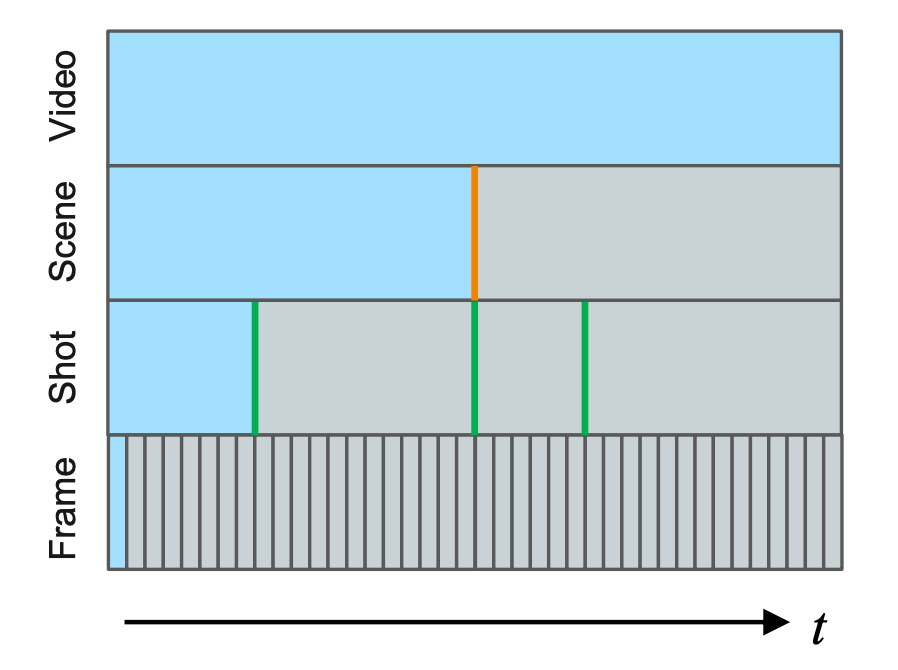
Snippet (Clip) : 보통 고정된 길이를 가지는 프레임의 연속된 집합입니다. 비디오 관련 논문에서는 보통 3D CNN Encoder를 많이 사용하고 여기에 들어가는 입력이 Snippet(=Clip) 단위로 고정된 시간 차원의 프레임 텐서가 들어갑니다.
Shot : 단일 카메라로 찍힌 프레임의 연속으로, 카메라나 장면에 대해서 별다른 방해나 전환이 없는 프레임의 집합입니다. Snippet(=Clip)의 연속으로도 이루어졌다고 볼 수 있습니다.
Scene : Shot의 연속으로 보통 짧은 story line을 만들 수 있는 정도의 프레임 집합체로 정의합니다. Scene의 정의가 조금 의미론적이라 모호하게 느껴질 수 있을 것 같습니다. 결국 여러 개의 Shot으로 구성된 Scene을 구분하는 것은 Challenging 한 Task입니다.
Video Scene Segmentation이 어려운 이유는 visual clue 만을 가지고 scene의 변화를 탐지하는 게 아니기 때문입니다.

위의 그림 (a)를 보면 남녀가 통화를 하는 장면이 나오고 있습니다. 같은 장면 내에서 visual 적으로 다른 shot들이 존재하고 있습니다. 그림 (b)를 보면 노란색 boundary를 기준으로 장면이 바뀌고 있습니다. 앞의 장면에서는 의료진과 환자가 대화를 하고 있는 것 같은데 뒤의 장면에서는 아예 공간이 바뀐 것 같습니다. 하지만 장면이 바뀌었지만 visual clue는 비슷합니다. 하지만 contextual 적으로는 다르기 때문에 둘은 서로 다른 장면입니다.
이렇게 Scene Segmentation을 잘하기 위해서는 장면이 가지고 있는 contextual 정보를 잘 이해하고 구분해야 합니다. 저자는 효과적인 self-supervised 기반의 pretext task를 통해 model이 이러한 contextual relationship을 학습하도록 제안합니다.
Intro에서 ShotCoL(2021, CVPR)이라는 논문을 언급하며 최근의 연구와 비교를 하고 있는데 이전의 연구 같은 경우는 shot 하나의 representation에만 집중하고 neighboring shot과의 contextual 한 relationship을 고려하지 않았기 때문에 한계점이 존재한다고 합니다.
Intro에서 이렇게 얘기를 하고 있으니 정말로 방법론이 이러한 contextual relationship을 고려할 수 있도록 설계가 되었는지 + ShotCoL이라는 방법론에 비해 더 높은 성능을 가져가는지 이렇게 두 가지를 중점적으로 보면 될 것 같습니다.
Preliminary
Video Scene Segmentation Task
입력으로 길이가 굉장히 긴 비디오를 받으면 이를 $ N $ 개의 shot $\left\{ s_{1},\ldots , s_{N}\right\} $으로 표현합니다. 이게 MovieNet이라는 데이터를 사용하게 되는데 하나의 shot 당 3개의 keyframe만을 공개하고 있습니다.
찾아봤는데 key frame을 어떻게 계산했는지는 나와 있지 않아서 조금 아쉬웠습니다. 무튼 비디오는 이제 $ N $ 개의 shot으로 표현되며 하나의 shot은 3개의 keyframe으로 구성되어 있습니다.
그리고 이제 video scene segmentation에 대한 학습 라벨은 binary mask, $\left\{ y_{1},\ldots , y_{N}\right\} where y_{i}\in \{ 0, 1\} $로 제공됩니다. 각각의 shot이 scene boundary 인지 아닌지를 나타내는 0,1로 구성된 mask입니다.
인접하는 shot 끼리는 비슷한 정보를 가지고 있기 때문에 이러한 local context를 활용하기 위해서 간단하게 sliding window 방식을 사용합니다.
예를 들어 $ n $ 번째 shot $ s_{n}$에 대해서 window는 양 옆으로 $ K $ 개의 shot을 참조합니다. 결국 window $ S_{n}=\{ s_{n-K},\ldots , s_{n},\ldots , s_{n+K}\} $는 $2K+1 $ 개의 shot sequence를 가진다고 볼 수 있습니다.
하나의 shot은 $ N_{k}$ 개의 key-frame들로 구성되어 있기 때문에 $ s_{n}\in R^{N_{k}\times C\times H\times W}$의 차원을 가지는 tensor라고 보시면 됩니다.
Model Architecture
여기서 사용하는 모델은 크게 두 개의 요소로 구성되어 있습니다.
우선 shot encoder($ f_{ENC}$)가 있습니다.
- $ e_{n}=f_{ENC}(s_{n}) \in R^{D_{e}}$
Shot을 구성하는 key frame 들을 하나의 vector로 embedding 하는 모듈입니다.
여기서 사용되는 인코더의 구조는 ResNet50이랑 Transformer를 사용했다고 합니다. Code를 봐야 알겠지만, ResNet으로 frame에 대한 feature를 기술하고 이를 Transformer를 활용해 하나의 shot feature로 aggregation 하는 것 같습니다.
다음으로 contextual relation network($ f_{CRN}$)가 있습니다.
- $ C_{n}=f_{CRN}(E_{n})$ ; $ f_{CRN}:R^{\left( 2K+1\right) \times D_{e}}\rightarrow R^{(2K+1)\times D_{c}}$
각각의 shot들이 shot encoder를 통해서 vector로 embedding이 되었으면 이제 window에 해당되는 모든 embedding을 가지고 contextual relation을 modeling 하는 부분입니다.
여기서 $ E_{n}$은 $ E_{n}=\left\{ e_{n-K},\ldots , e_{n},\ldots , e_{n+K}\right\} $로 window에 해당되는 영역만큼의 embedding 집합입니다.
결국 shot encoder로부터 나온 representation을 가지고 다시 좀 더 contextual relation이 가미된 representation을 얻을 수 있도록 한번 더 embedding을 해준다고 보면 됩니다. 이 부분이 잘 설계되어야 shot encoder도 더 좋은 representation을 가지도록 학습이 되겠죠.
뒤에 본격적인 Method 얘기를 하기 전 알아야 되는 구성 요소와 notation에 대해서 간단하게 알아보았습니다. 이제 본격적으로 저자가 제안하는 Boundary-aware Self Supervised Learning(BaSSL)에 대해서 알아보도록 하겠습니다.
Boundary-aware Self-Supervised Learning (BaSSL)
Overview
전체적인 파이프라인은 two-stage로 진행됩니다. Large-scale unlabeled data를 가지고 pre-train을 하고 small-labeled data를 가지고 fine tuning을 진행합니다. 본 논문의 주된 관심사는 pre-train 단계입니다.
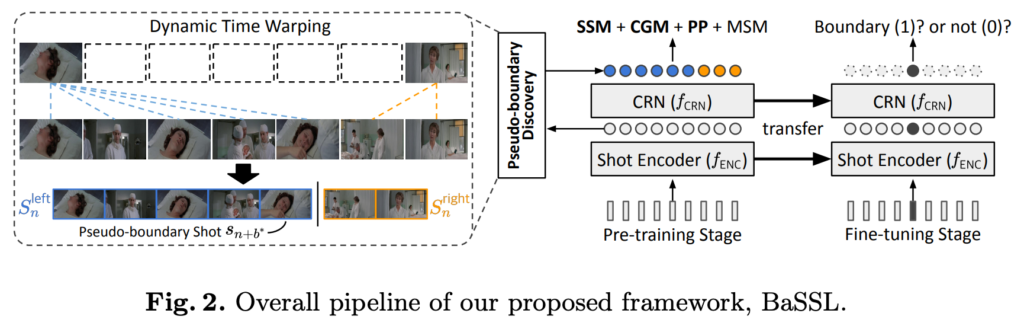
Pre-train 단계에서 input window $ S_{n}$이 주어지면 BaSSL은 shot 끼리 semantic transition이 최대로 변하는 지점을 탐색하고 그 부분을 pseudo boundary로 지정합니다. 그리고 이 boundary를 이용하여 여러 가지 self-supervised pretext task를 수행하죠.
그렇다면 일단 pseudo boundary는 어떻게 찾는지부터 시작해 보도록 하겠습니다.
Pseudo-boundary Discovery
일단 간단하게 생각해 보면 pre-train 단계에서의 목적은 semantic change를 capture 하는 능력을 기르는 것입니다. 방법이야 다양하겠지만 여기서는 pseudo boundary를 정의하고 boundary로 나눠지는 경계를 토대로 semantic relation을 학습시킵니다.
그런데 사실 pseudo boundary를 잘 찾는 것부터가 어렵습니다. Scene Segmentation은 학습을 통해서 boundary를 찾는 과정인데 pseudo boundary는 학습을 하지도 않고 일단 학습에 사용할 boundary를 찾아야 하는 것이니 많은 제약조건이 있겠죠.
일단 고정된 window 내에서 몇 개의 boundary가 있는지 모릅니다. 사실 window 안에 없을 수도 있죠. 그렇다면 간단하게 생각해서 일단 window 내에서 semantic transition이 가장 크게 발생하는 부분을 고려하면 되겠네요. 실제로 그 부분이 boundary가 아닐 수 있지만 pretrain 단계에서는 꽤나 유용하게 사용할 수 있다는 의미입니다.

위의 그림은 저자가 제안하는 방식으로 pseudo boundary를 찾았을 때의 모습입니다. 적어도 장면이 확연하게 바뀌는 부분에 대해서는 나름 잘 찾아주는 모습을 보여주고 있습니다. 사전 학습 단계에서는 저 정도의 rough 한 boundary를 가지고 학습을 한 다음에 finetuning 단계에서 segmentation 능력을 좀 더 고도화를 시킨다고 보면 될 것 같습니다.
저자는 Dynamic time warping을 토대로 boundary를 찾고 있습니다. 일단 formulation을 먼저 보여 드리면 아래와 같습니다.
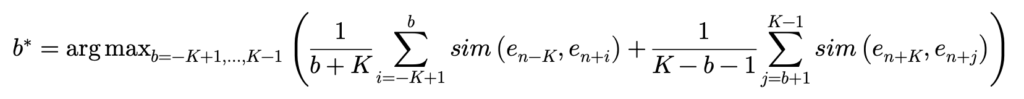
저도 처음에 수식만 보고서는 도저히 이해가 안 가서 간단하게 $ K=5 $를 잡고 toy example을 만들어 보면서 이해를 해보았습니다.
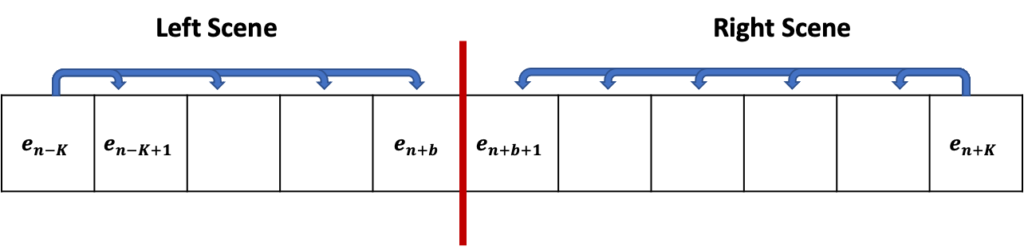
$ e_{n+b}$와 $ e_{n+b+1}$을 기준으로 두 개의 sequence가 생성됩니다. 수식을 보면 Left Scene 내에서 가장 왼쪽에 있는 shot인 $ e_{n-K}$와 나머지 shot 들끼리의 유사도를 모두 더해 평균 내주고 있습니다. Right Scene 역시 마찬가지로 계산하고 있습니다.
핵심은 $ b $의 인덱스를 조절해 가면서 하나씩 boundary를 바꿔보고 그때마다 Left Scene과 Right Scene의 유사도 평균들을 더 했을 때 최대가 되는 지점이 semantic transition이 가장 크게 발생하는 pseudo boundary라고 정의하는 것입니다.
간단하죠. 하지만 연산 복잡도는 제가 계산했을 때 $ O(K^{2})$으로 계산이 되는데 어차피 뭐 pseudo boundary는 학습 전에 미리 찾아놓고 돌려놓으면 되니 크게 문제가 될 것 같진 않습니다.
이렇게 Window 마다 similarity transition이 최대로 발생하는 지점을 무조건 하나는 결정하여 pseudo boundary로 사용을 해주게 됩니다.
물론 window에 우리가 원하는 scene boundary가 없을 수도 있고, 하나보다 더 많을 수 있지만 Self-Supervised 상황에서 나름 최선의 탐색 방법을 제안하는 것 같습니다. 자세한 boundary에 대한 학습은 finetuning 과정에 맡기는 것이죠.
Pre-training Objectives
위에서 찾은 pseudo boundary를 토대로 이제 4가지의 loss를 설계하여 boundary-aware pre-training을 진행합니다.
Shot-Scene Matching (SSM)
우리가 pseudo boundary를 찾았으니 이제 서로 다른 scene에 대해서 임시로 구분을 할 수 있게 됐습니다. 여기서 이제 할 수 있는 가장 간단한 Self-Supervised Learning은 Contrastive Learning입니다.
같은 scene에 있는 shot representation은 similarity가 유사해지도록 만들고 다른 scene에 있는 shot representation은 similarity가 멀어지도록 만드는 것이죠. 이때 Contrastive Learning framework는 SimCLR를 사용했습니다.
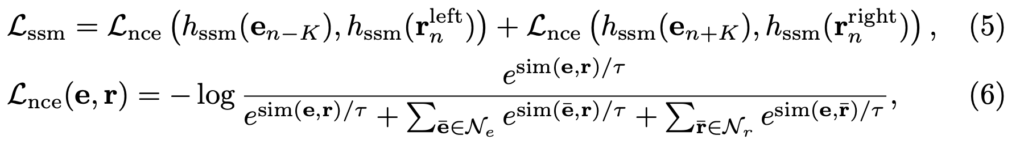
여기서 $ h_{ssm}$는 SimCLR에서 사용하는 것처럼 SSM을 위한 Linear layer head입니다.
$ r_{n}^{left}$는 left scene에 해당하는 shot representation을 모두 평균 내줘서 만든 scene representation입니다. $ N_{e}, N_{r}$은 다른 배치 내에 존재하는 scene을 토대로 만들어낸 negative pair입니다.
SimCLR 구조를 알고 있다면 이해하는데 어렵지 않습니다. SimCLR 구조를 모르신다면 저의 지난 리뷰 Self-Supervised Learning Framework를 한번 보시길 바랍니다.
Contextual Group Matching (CGM)
위에서 설명한 SSM을 통해서 어느 정도 shot representation을 우리가 원하는 방향으로 설계할 수 있지만 semantic clue까지 capture 하기에는 부족할 수 있습니다.
이를 보충하기 위해 저자는 classification task를 통해 추가적인 semantic information을 학습할 수 있는 구조를 제안합니다.

아까 찾은 pseudo boundary를 기준으로 이제 left scene, right scene이 구분될 수 있습니다.
이때 window에 대해서 center에 존재하는 shot $ s_{n}$에 대해서 triplet pair를 생성합니다. $ s_{n}$이 left scene에 존재한다면 left scene에 존재하는 shot 중 random 하게 selection 해서 positive pair를 생성하고 right scene에서는 negative pair를 생성합니다.
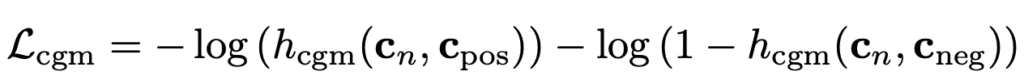
그리고 $ h_{cgm}$ head를 정의해 주는 데, 두 개의 shot을 입력으로 받고 matching score를 output으로 생성합니다. Binary Cross Entropy Loss를 사용했으니 positive pair 끼리의 matching score가 1에 가까워질 것이고 negative pair 끼리의 matching score는 0에 가까워질 것입니다.
SSM이랑 목적은 비슷한데 좀 더 shot representation을 더욱 정교하게 만들기 위해 만든 추가 module이라 생각하면 될 것 같습니다.
Pseudo-boundary Prediction (PP)
우리가 pseudo boundary를 만들었으니 이를 직접적으로 활용하는 가장 쉬운 방법은 pseudo boundary를 예측하게 만드는 것입니다.
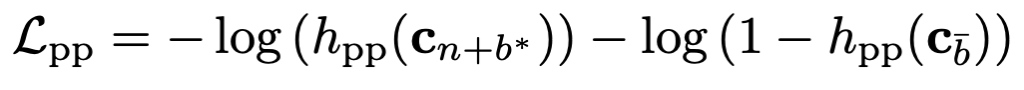
boundary에 존재하는 shot 인 $ c_{n+b^{\ast }}에 대해서는 $ h_{pp}$ head를 태워 boundary score를 1에 가깝게 만들어주고 boundary에 존재하지 않는 shot에 대해서는 boundary score를 0에 가깝게 만들어 줍니다.
Masked Shot Modeling (MSM)
마지막으로는 random 하게 15% 정도에 해당되는 shot을 masking 한 다음에 reconstruction 하는 loss를 통해 추가적인 pre-training을 진행합니다.
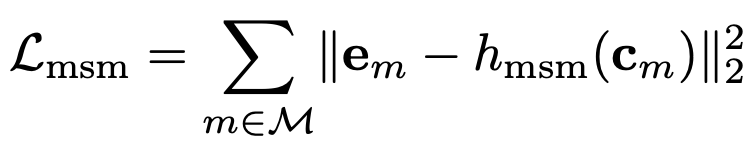
이따 ablation에서도 나오지만 사실 이 MSM은 거의 효과가 없고 약간, 좋은 게 좋은 거지라는 느낌으로 넣어준 모듈 같습니다.
Experiments
Comparison with State-of-the-art Methods
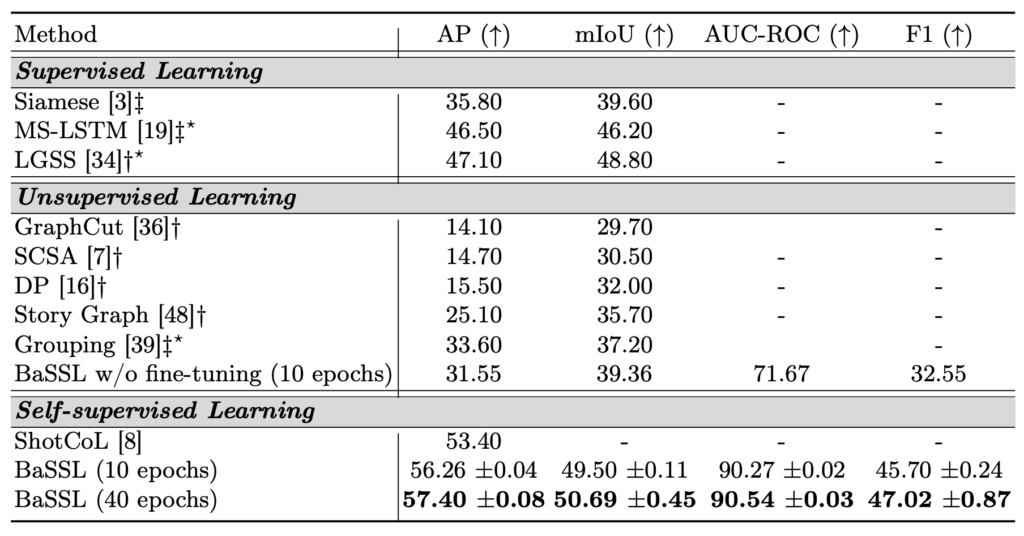
우선 benchmarking 실험입니다. 신기한 건 지도학습 기반 방법론들의 성능이 왜 이렇게 낮은지 의문입니다.
일단 Unsupervised Learning 쪽에 BaSSL w / o fine-tuning이 있는데 이는 사전학습만을 Self-Supervised로 진행하고 supervised annotation으로 finetuning을 하지 않은 경우입니다. 이 부분은 다른 비지도학습 대비 성능이 조금 떨어지는 것을 볼 수 있습니다.
Self-Supervised Learning의 경우 이전의 work인 ShotCoL과 동일하게 사전학습은 Self-Supervised로 진행하고 finetuning을 지도학습으로 진행했을 때의 성능입니다. 기존 work 대비 더 높은 성능을 보여주고 있습니다.
아직 Video Scene Segmentation 연구가 활발하게 이루어지고 있지 않아 Benchmarking에 들어가는 방법론이 많지는 않네요.
Comparison with Pre-training Baselines

여기서는 pre-train 방식을 다르게 했을 때의 성능을 비교하고 있습니다.
Supervised pre-training using image dataset은 image classification task를 바탕으로 사전학습을 진행하는 것이고 Shot-level pre-training은 ShotCoL에서 제안하는 방식 그대로를 사용한 경우입니다. 마지막으로 Boundart-aware pre-training은 저자가 제안하는 방식으로 pre-training을 진행했을 때의 성능입니다.
모델 architecture를 MLP나 MS-LSTM을 사용했을 때는 shot-level pretraining과 성능이 크게 다르지 않지만 transformer 구조로 사용했을 때 boundary-aware pre-training 방식과 합이 잘 맞아 굉장히 높은 성능을 보여주고 있습니다.
Ablation Studies
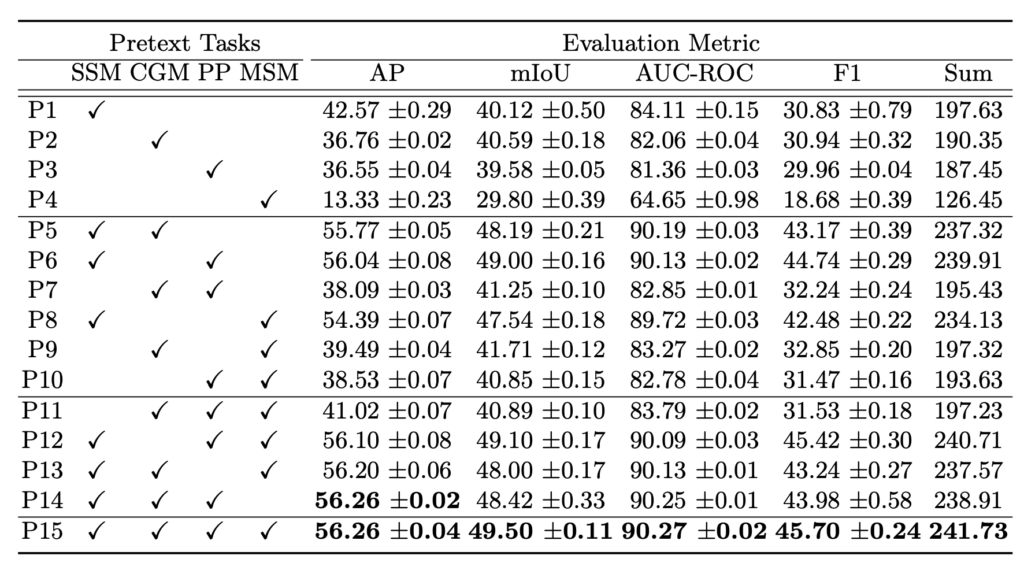
Ablation study입니다. 4가지 Loss를 토대로 만들어지는 모든 case를 다 진행했네요. 모든 case의 경향성을 보진 않았지만 SSM과 CGM만 사용해도 굉장히 높은 성능을 보여주고 있습니다.
제 생각엔 PP나 MSM 같은 경우는 좀 더 개선의 여지가 남아 있는 것 같습니다.
그래도 최종적으로 모두 사용해 주는 것이 미세하지만 모든 metric에서 가장 좋은 성능을 보여주고 있습니다.
Qualitative Analysis
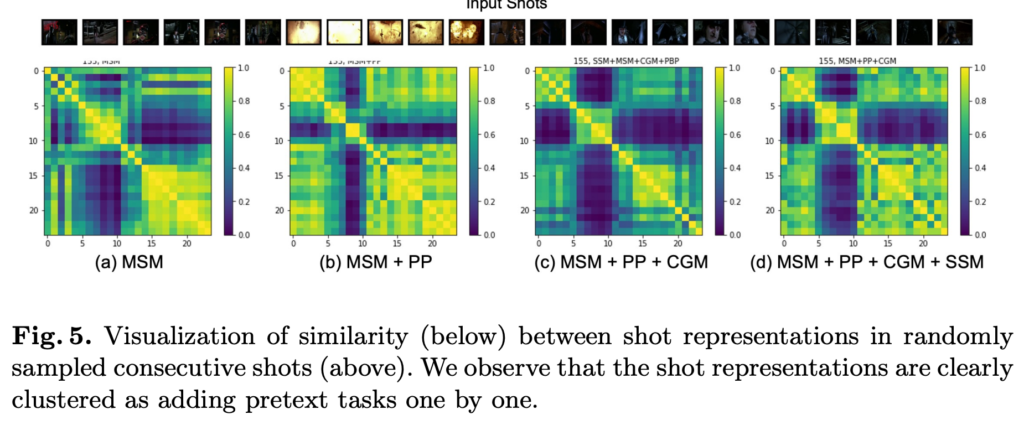
shot representation을 가지고 similarity matrix를 visualization 한 결과입니다.
(d)의 경우 모든 module을 사용했을 때 matrix의 형태가 scene을 잘 구분하고 있는 모습을 보여주고 있습니다.
Input shot을 보면 크게 세 가지 장면으로 구분이 되는데 첫 번째 장면과 세 번째 장면이 비슷한 visual information을 담고 있기 때문에 matrix에서도 서로 높은 유사도를 가지고 있는 반면에 두 번째 장면은 확실하게 다른 장면들과 구분이 되는 모습입니다.
Conclusion
앞으로 학계에서도 video scene segmentation 연구가 더욱 활발하게 진행 됐으면 좋겠습니다.
리뷰 읽어주셔서 감사합니다.



