Before Review
이번 X-Review는 처음 읽어보는 Video Question Answering(이하 VQA) 논문입니다.
VQA에 관심이 생긴 건 아니고, Graph Representation을 활용하여 semantic representation을 고도화하는 논문을 찾다가 VQA 진영에서는 이러한 Graph Representation을 많이 사용한다는 것을 알게 되어 논문 하나 잡고 리뷰하게 됐습니다.
저도 생소한 VQA인데 더군다나 Graph Representation에 대한 내용도 나와서 논문 읽느라 조금 힘들었습니다. 리뷰 자체는 실험 내용에 대한 해석보다는 방법론에 대한 이해에 좀 더 초점을 맞췄습니다.
리뷰 시작하겠습니다.
Preliminaries
Hyper Graph
분명 알고리즘 시간 때 Graph에 대해서 어느 정도 배웠지만 Graph Theory에서 사용되는 다양한 용어들은 아직 낯선 것 같습니다. 이 Hyper Graph라는 녀석도 마찬가지고요.
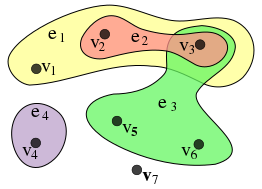
그래프 이론에서 하나의 에지가(hyper-edge) 두 개 이상의 노드를 연결할 수 있는 그래프를 hyper graph라 정의하고 있습니다. 보통은 node 끼리 공통점이 있을 때 hyper graph 구조를 사용하여 표현하곤 합니다. 예를 들어 가족, 수강생, 성별 이런 것들이 있겠네요.
Hungarian Algorithm
Hungraian Algorithm(Wikipedia)
헝가리안 알고리즘은 조합 최적화 문제에 대한 알고리즘 중 하나로 assignment, matching 문제를 해결할 때 주로 사용됩니다.
찾아보면서 결국 알고리즘의 핵심은 matching 과정에서 brute-force 방식처럼 모든 경우의 수를 다 따져가면서 최적의 matching을 찾는 것이 아니라 효율적으로 최적의 matching을 찾는 것이라 느꼈습니다.

예를 들어 파티를 준비하고 있을 때 파티를 위한 서비스를 고려하기 위해 업체를 선정하고 있다고 가정해 봅시다. 하나의 서비스 당 하나의 회사를 선택해야 하는 상황에서(A라는 회사가 두 개의 서비스를 제공하면 안 된다는 의미) 어떠한 경우의 수로 골라야 가장 저렴하게 준비를 할 수 있는지 찾아보는 문제가 되겠죠.
단순히 모든 경우의 수를 고르면 복잡도는 $ O(n!)$가 되겠죠. 이러한 방식은 효율적이지 못합니다. $ n! $의 복잡도를 가지는 알고리즘은 상당히 끔찍한 상황이라 보면 됩니다.

헝가리안 알고리즘은 위의 방식처럼 이분 그래프의 weight를 이용하여 적용할 수 있습니다. 알고리즘의 자세한 동작 과정보다는 일단 어느 상황에서 사용되는지 정도로만 정리하고 본 논문의 리뷰를 시작하도록 하겠습니다.
Introduction
Video Question Answering은 쉽게 말해 주어진 비디오 데이터와 관련된 질문을 함께 질문으로 입력으로 받아 비디오 콘텐츠 내 정보를 파악하여 질문에 알맞은 답을 내놓는 문제입니다. 제가 생각하기에는 영상 데이터를 이해하는 데 이거 만큼의 어려운 task도 없다고 생각합니다.

그도 그럴 것이 비디오 데이터를 구성하는 action, object 들끼리의 relation 정보가 temporal domain에 따라 어떻게 변화하는지 파악해야 하며 그 와 동시에 이를 잘 서술할 수 있는 text 정보와의 cross-modal representation까지 고려해야 하기 때문입니다.
다양한 entity 들의 집합들을 검출해야 하며 그들 간의 상호작용을 인지하고 시간에 따라 이러한 동적 변화를 파악하는 것은 아직 인공 신경망이 충분히 어려워할 수밖에 없겠죠. 이러한 어려움을 극복하고자 VQA 연구에서는 graph 구조의 representation을 활용하는 연구들이 활발하게 진행되고 있다고 합니다.
Scene Graph, Knowledge Graph, Spatio-Temporal Graph 등등 다양한 그래프 구조를 활용하여 semantic information을 modeling 하고 이를 활용해 VQA를 좀 더 잘 풀어보자라는 콘셉트입니다.

본 논문에서는 situation hyper-graph 구조를 활용하여 VQA에 적합한 representation을 학습하는 구조를 제안합니다.
기존의 연구들은 이러한 hyper graph를 적용하기 어려웠다고 합니다. 제가 이쪽 분야를 자세하게 follow-up 하고 있는 것은 아니라 저도 이유는 잘 모르겠네요. 암튼 최근 연구된 [2022 NIPS] Pure Transformers are Powerful Graph Learners 논문에 따르면 graph-specific 한 detail이 없어도 transformer를 사용하면 기존에 정교하게 설계된 graph specific model 보다 동등하거나 더 우수한 성능을 얻을 수 있다는 결과도 있습니다.
저자도 이러한 아이디어에 기인하여 transformer 구조를 통해 비디오를 나타내는 hyper graph를 학습하는 구조를 제안합니다. [2022 NIPS] Pure Transformers are Powerful Graph Learners에 따라 inference 단계에서는 graph computation을 필요로 하지 않으며 decoder의 출력 값을 cross attention module에만 던져주면 비교적 간단하게 situation hyper graph를 학습할 수 있다고 합니다.
좀 더 구체적으로 설명을 하자면 원래 Knowledge Graph 혹은 Scene Graph 같은 경우는 CLIP에 기반한 prior knowledge나 Faster RCNN 같은 pretrained object detector를 사용하여 graph를 구축하는 반면에 transformer를 사용하면 이러한 별다른 장치는 전혀 필요로 하지 않으면서 더 우수한 성능을 기대할 수 있다는 것입니다.
이때 situataion hyper graph를 학습하기 위해서는 결국 action에 대한 set을 예측하게 됩니다.
예를 들면 "Drinking form a bottle"이라는 action은 하나의 frame이 구성하는 static 한 actior-object, object-object들의 relation 변화로 이루어집니다. <person, hold, bottle> , <bottle, stands on, table> 이런 식으로 다양한 관계들이 매 frame 마다 존재하고 이 것들은 하나의 set을 이루게 됩니다.
결국 우리는 이러한 relation들을 모델링한다는 것은 프레임마다 relation에 대한 set들을 예측하는 것을 의미합니다. 이럴 때 Ground Truth set과 비교하기 위해 bipartite matching loss를 사용합니다. 여기서 아까 preliminary에서 다룬 헝가리안 알고리즘이 등장하게 됩니다. 자세한 설명은 뒤에서 하도록 하죠.
저자는 introduction에서 한 가지 주의 사항을 당부합니다. 본 논문은 hyper graph를 construction 하기는 하지만 기존의 scene graph generation처럼 완벽한 graph를 구축하는 것이 목적이 아니라 이 construction 하는 과정에서 발생하는 representation을 활용해 최종적으로는 VQA를 잘하는 것이 목적이라고 합니다.
자 그렇다면 저자가 제안하는 Situtation Hyper Graph for Video Question Answering(SHG-VQA) 구조는 어떻게 설계되었는지 살펴보도록 하겠습니다.
The SHG-VQA Model
Situtation Video Question Answering은 세 가지의 필수 단계로 구성되어 있다고 합니다.
1. visual entities를 검출하고 그들의 relationship, action을 파악하고 이것들이 시간에 따라 어떻게 변하는지 파악하는 능력
2. 질문을 올바르게 이해할 수 있는 언어 이해 능력
3. 첫 번째 단계에서 얻은 representation을 토대로 질문에 대한 reasoning을 올바르게 수행하는 능력
세 가지 단계 모두 중요하기 때문에 각 단계에서 sub-optimal 한 performance는 전반적인 process에 큰 영향을 끼치게 됩니다.
근데 그중에서도 첫 번째 단계인 visual structure를 이해하는 과정이 문제라고 합니다.
그냥 raw data로부터 단순히 feature를 embedding 시키면 high-level language guided reasoning에 부적절한 representation을 제공하기 때문에 이러한 mismatch 문제를 해결하기 위해 graph representation을 활용하는 것이죠.
정확히는 우리의 신경망 모델이 hyper graph 구조를 예측하도록 강제하다 보면 video representation만 좋아지는 것이 아니라 VQA에 도움이 되는 representation까지 학습이 된다는 것입니다.
Input Processing
Question Encoder
Text data는 기본적인 transformer encoder를 통해 처리됩니다. 일단 wordPiece tokenizer(Google이 BERT를 사전 학습하기 위해 개발한 토큰화 알고리즘)를 통해 토큰화가 되며 [CLS] 토큰과 함께 transformer encoder에 들어가 attention이 적용됩니다.

Video Encoder
입력으로 video tensor $ V $ 받아 일단 convolutional backbone에 태워 $ x_{V}$를 추출합니다.
- $ V \in \mathbb {R}^{T\times H\times W\times 3}\rightarrow x_{V} \in \mathbb {R}^{T\times h\times w\times d_{x}}$
이때 transformer는 순차적인 데이터를 처리하기 때문에 $ x_{V}$는 flatten 되어 처리됩니다.
- $ x_{V} \in \mathbb {R}^{T\times h\times w\times d_{x}}\rightarrow x_{V}\in \mathbb {R}^{Thw\times d_{x}}$
그리고 feature에 해당하는 차원$ d_{x}$은 다시 한번 linear layer를 거쳐 $ d $라는 latent space로 보내지게 됩니다.
- $ x_{V} \in \mathbb {R}^{Thw\times d_{x}}\rightarrow x_{V}\in \mathbb {R}^{Thw\times d}$
기본적으로는 positonal encoding을 사용해주고 있으며 Text encoder와 마찬가지로 [VIS]라는 token을 추가하여 비디오 전체를 대표하는 token을 활용해 줍니다.

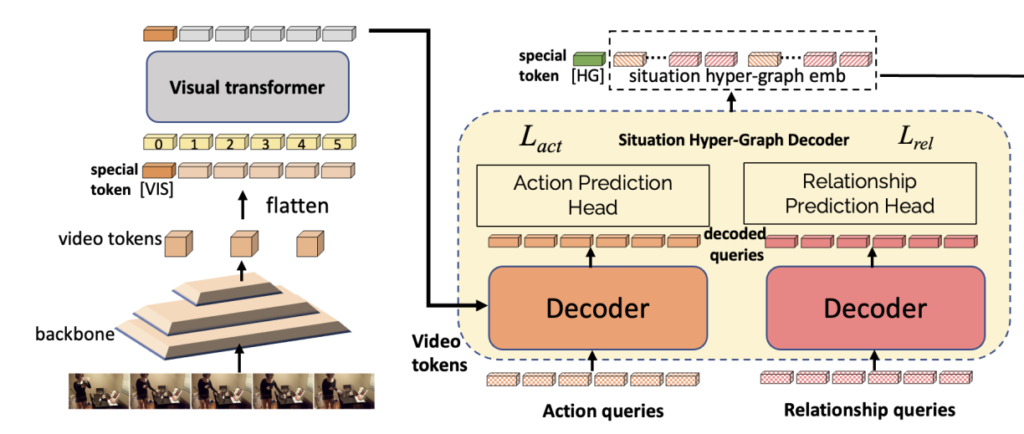
아래의 그림처럼 Visual Transformer를 거쳐서 나온 출력이 쿼리화 되어 action decoder와 relation decoder로 보내지게 됩니다.
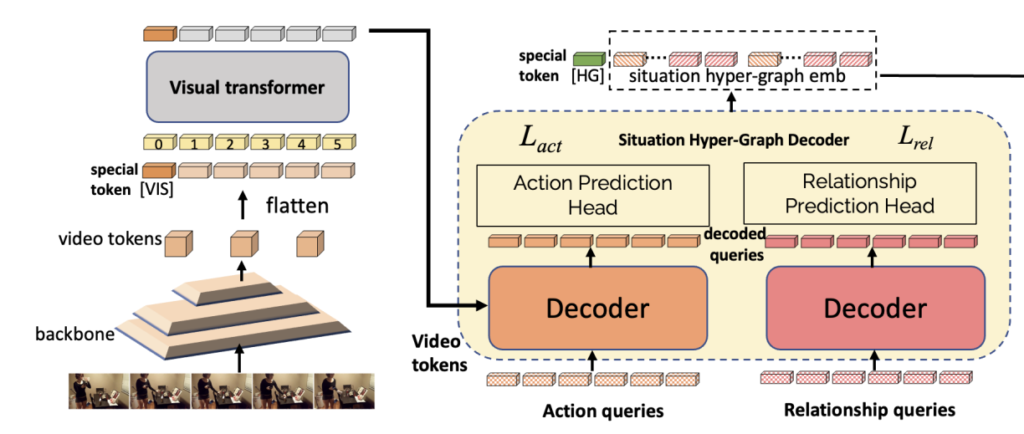
Action Decoder와 Relation Decoder를 통해서 나온 출력은 우선 각각 concat 되어 token들의 sequence를 생성하고 추가적으로 [HG]라는 special token을 활용하여 VQA에 대한 classification 문제를 해결하기 위해 대표 token으로 사용됩니다.
조금 복잡하다고 느낄 수 있지만 그냥 비디오 데이터, 텍스트 데이터 모두 transformer 구조로 처리되고 있으며 특히 비디오 데이터들은 action, relation을 나타낼 수 있는 latent query로 임베딩 된 다음에 별도의 decoder를 태워서 또 다른 loss를 통해 최적화되는 구조라 보시면 됩니다.
최종적으로 VQA를 수행하기 위해서는 classification이 수행되는데 이를 위해 Question과 Video에 대한 cross modal을 고려하기 위한 attention layer를 각각의 출력 층 마지막에 결합되어 Question & Answering 문제를 풀게 됩니다.
Situtation Hyper Graph Generation
보통 그래프를 generation 혹은 construction 한다고 하면
$ G=(V, E)$에서 set of vertices($ V $) , set of edges($ E $)를 예측하는 경우가 많지만 본 논문에서는 $ V $와 $ E $를 예측하는 것이 아니라 아래와 같이 action과 relationship을 예측하는 방식으로 formulation을 정의합니다.
정의되는 relationship은 object-relation-object , actor-relation-object처럼 정의가 됩니다. 즉, entity 간의 relation을 예측하는 것이죠. 그래서 우리는 모델이 relationship에 대한 집합 $ R $과 추가적으로 action에 대한 집합 $ A $를 예측하도록 강제합니다.
여기서 $ R $의 크기는 $|M|$로 표기하고 $ A $의 크기는 $|N|$으로 표기합니다. 즉 이때 우리는 각각의 decoder를 통해서 나온 set들의 sequence를 예측하는 문제입니다.

즉, $ A \in \mathbb {R}^{\left|N \right| \times T}$를 ground truth set이라 정의하고 $\hat {A}\in \mathbb {R}^{\left|N \right| \times T}$를 예측한 집합이라 정의하겠습니다. 그래서 이 set 들끼리의 최적의 matching 상태를 구하고 그 상태에서의 loss를 반영해서 학습하는 것이 핵심입니다.
일단은 Loss에 대한 formulation을 자세히 설명하기 전에 aciton과 relation에 대한 set을 어떻게 예측하는지 먼저 살펴보도록 하겠습니다.
그런데 개인적으로 여기서 video clip feature가 각각 쿼리로 어떻게 임베딩 되는지에 대한 detail이 main paper와 supplementary에 없어서 부족할 수 있지만 제가 파악할 수 있는 정보 내에서의 서술만 하도록 하겠습니다.
Action Decoder
우선 비디오 clip feature가 주어지면, 우리는 action들의 집합을 decode 하고 싶습니다.
- $ x_{V} \in \mathbb {R}^{Thw\times d}\rightarrow x_{action} \in \mathbb {R}^{T \times \left|N \right| \times d}$
Relationship Decoder
relation들의 집합도 마찬가지로 decoding 됩니다.
- $ x_{V} \in \mathbb {R}^{Thw\times d}\rightarrow x_{rel} \in \mathbb{R}^{T \times \left|M \right| \times d}$
논문에서 정확히 query embedding 과정에 대한 detail을 명시하지 않고 있지만 아마 위의 관계처럼 query가 embedding 되지 않을까 싶네요.
Prediction Head
위에서 Action, Relationship 디코더를 통해서 나온 출력들은 각각의 Prediction Head를 통해 예측된 set을 출력으로 내놓게 됩니다.
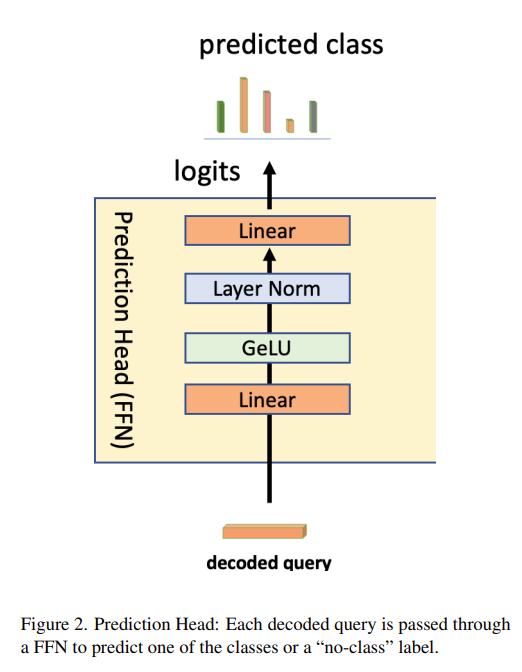
- $\hat {A} = \text{FFN}_{action}(x_{action}) \in \mathbb {R}^{T \times \left|N \right|}$
- $\hat {R} = \text{FFN}_{rel}(x_{rel}) \in \mathbb {R}^{T \times \left|M \right|}$
$ \hat {A} , \hat {R} $를 어떻게 구하는지 살펴봤으니 이제 bipartite matching loss는 어떻게 계산되는지 알아보도록 합시다.
Actions and relations set prediction loss
결국 핵심은 최대한 같은 class 끼리의 entropy를 낮추는 방향으로 학습이 진행됩니다.

이런 식으로 말이죠. 그리고 최대한 같은 class를 찾는 과정이 위에서 서술한 헝가리안 알고리즘을 통해 matching이 됩니다.
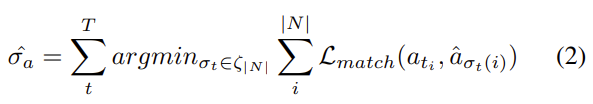
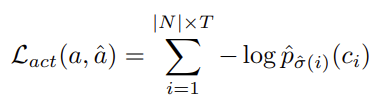
이게 수식으로 나타나면 위와 같은데 그냥 헝가리안 알고리즘으로 matching 찾아주고 matching 된 pair끼리 cross entropy loss 사용해주고 있는 모습입니다. Action set에 대해서만 설명드렸는데, Relation set에서도 동일하게 Loss가 정의됩니다.
이렇게 해서 각각 Action Set을 예측하는 $ L_{act}$와 Relation Set을 예측하는 $ L_{set}$이 정의가 됩니다.
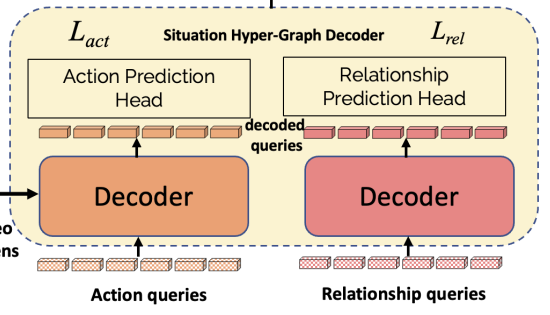
Situation hyper-graph Embedding
위에서 설명한 것은 hyper graph를 구성하는 action, relation에 대한 set을 예측하는 과정에 대해서 전반적으로 설명을 드렸습니다. 이제는 hyper graph를 embedding 하고 이 정보를 VQA에 어떻게 사용할 수 있는지 살펴보도록 하겠습니다.

위의 그림은 특정한 time step $ t $에 대해서 hyper graph embedding이 어떻게 이루어지는지 나타내는 그림입니다.
Action과 Relation 쿼리들이 Action, Relation 디코더를 통해서 차원이 그대로 유지되면서 나오게 될 것입니다.
- Decoded action queries : $ x_{action}^{(t)} \in \mathbb {R}^{\left|N \right| \times d}$
- Decoded relationship queries : $ x_{rel}^{(t)} \in \mathbb {R}^{\left|M \right| \times d}$
여기에 세 가지 token이 추가됩니다.
- Situtation ID : 몇 번째 frame 인지 나타내는 token입니다.
- Attention Mask : no class를 처리할 수 있는 attention token입니다.
- Type encoding : Action Token인지 Relation Token인지 구분하는 token입니다.
이러한 token들이 각각 decoded query에 추가되고 최종적으로 action query, relation query들이 concat 됩니다. 그리고 여기에서 이 hyper graph 전체를 대표하는 [HG]라는 special token을 추가하여 graph에 대한 embedding을 최종적으로 결정합니다.
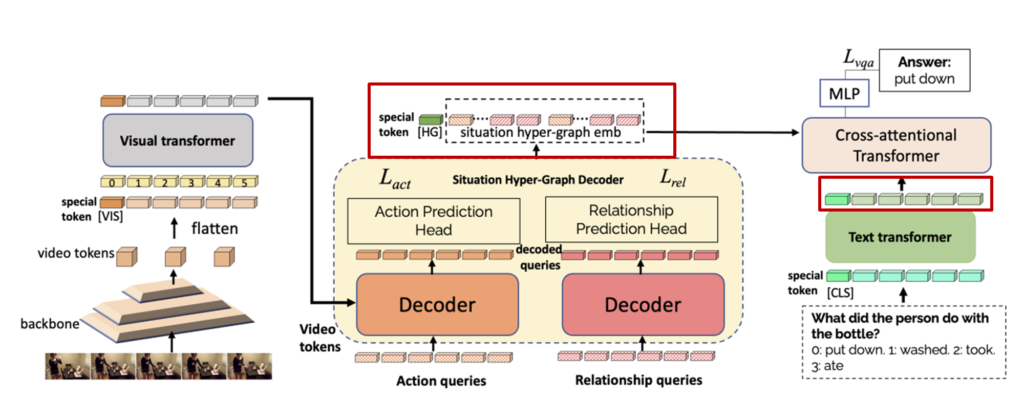
우리의 최종 목적은 일단 VQA이므로 VQA에 대한 Loss를 설계해야 합니다. Situtation Hyper Graph embedding과 Question에 대한 text embedding 간의 cross attention transformer를 사용하여 multi-modal representation을 처리하고 마지막 MLP layer를 통해서 QA에 대한 cross entropy loss를 사용합니다.
저도 이번에 알았지만 기본적으로 VQA는 객관식 문제를 푸는 작업이라 cross entropy loss로 최적화된다고 합니다.
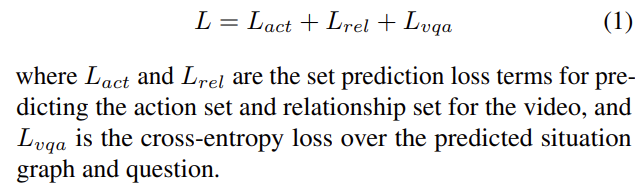
Results and Analysis
사실 아래 실험에서 등장하는 모든 metric과 실험 세팅에 대해서는 잘 모르겠습니다. VQA를 직접적으로 하려고 했던 건 아니라 가볍게 살펴보았습니다.
Comparison to State-of-the-Art
AGQA (Action Genome Question Answering)
AGQA는 기본적으로 세 가지의 평가 메트릭을 가지고 있습니다. Indirect references, novel compositions, and more compositional steps 각각에 대해서 설명은 드리지 않을 예정이니 궁금하신 분들은 직접 찾아보시면 될 것 같고 저는 그냥 성능이 얼마나 좋아지는지 정도만 참고할 예정입니다.
AGQA라는 VQA 데이터 셋에서 가장 sota 베이스라인은 HCRN이라는 방법론이라고 합니다. 따라서 아래 테이블에서 SHG-VQA 바로 위쪽에 있는 성능을 중점적으로 비교하시면 될 것 같습니다.

평가 메트릭이 많지만 결국에는 질문에 올바른 정답을 내놓았는지를 평가하는 정확도로 비교가 되고 있습니다. 대충 Overall 부분에서 정확도에 대한 평균만 비교하여도 성능이 매우 향상된 것을 볼 수 있습니다.
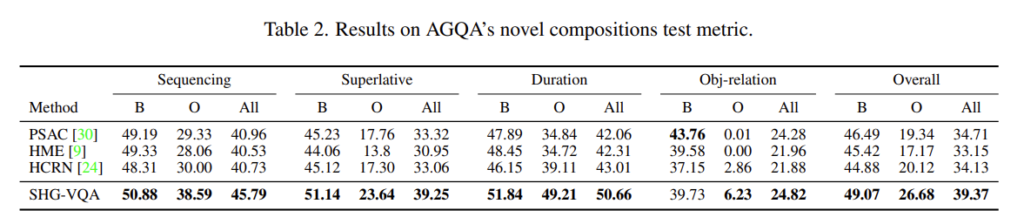
Novel Composition metric 상황에서의 성능 평가입니다. 역시 제안하는 SHG-VQA가 Overall 부분에서 정확도에 대한 평균을 비교해도 성능이 매우 향상된 것을 볼 수 있습니다.

Indirect reference 상황에서도 굉장한 성능 향상을 보여주고 있습니다.

테이블을 놓고 보면 성능이 낮아 보이지만 학습 데이터에서 SHG-VQA 같은 경우는 100,000개 정도의 QA pair 만을 사용한 반면에 다른 베이스라인들은 1000,000개가 넘는 pair를 가지고 학습을 했다고 합니다. 그럼에도 다른 베이스라인과 거의 동일한 성능을 보여주고 있는 것을 보면 적은 데이터 셋 상황에서도 나름 강인하게 동작하고 있는 것 같습니다.
STAR
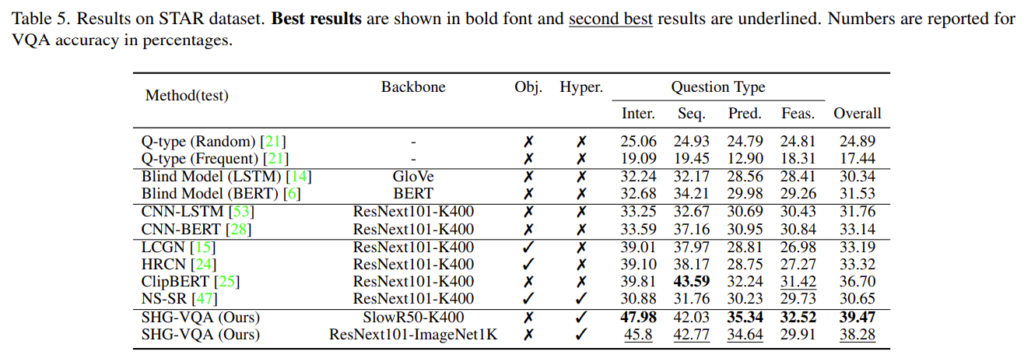
STAR 데이터 셋에서도 동일한 경향성을 보여주고 있습니다. Overall 부분만 보아도 다른 베이스라인 대비 압도적인 성능 향상을 보여주고 있습니다.
Ablation and Hyperparameter Analysis
단순 하이퍼 파라미터에 대한 ablation은 담지 않았고 제 생각에 중요하다고 생각되는 실험 두 개 정도만 리뷰에 담았습니다.
Impact of situation graphs quality

Oracle 실험입니다. Situtation Hyper Graph의 퀄리티가 VQA 성능에 어떤 영향을 미치는지 보여주는 실험입니다. 학습 과정에서 발생하는 hyper graph를 사용했을 때의 성능과 GT graph를 활용하여 VQA를 진행했을 때의 성능입니다. test에 대해서는 graph에 대한 GT가 없기 때문에 validation set으로 진행했다고 합니다.
당연히 GT graph를 활용했을 때 성능이 40.26에서 62.46까지 엄청나게 올라가는 것을 볼 수 있습니다.
근데 여기서 Prediction , Feasibility 같은 경우 비디오의 보지 못한 부분에 대한 질문이라 볼 수 있는데 이 부분에서는 GT를 활용해도 역시나 어려워하는 경향성을 보고 있습니다.
그럼에도 이 실험이 나타내는 것은 본 연구가 충분히 더 개선의 여지가 남아 있다는 것을 보여주고 있습니다. GT 성능을 따라잡는 것이 자연스러운 방향이겠네요.
Frame-wise set prediction loss

헝가리안 알고리즘 기반의 matching 후 set prediction loss를 사용했을 때와 하지 않았을 때 생성되는 그래프의 차이를 정성적으로 보여주고 있습니다.
이 실험이 보여주는 것은 graph 구조를 활용하여도 graph representation을 명시적으로 끌어낼 수 있는 loss가 없다면 최적으로 학습이 되지 않는다는 것을 보여주고 있습니다.
Conclusion
논문을 읽느라 너무 힘들었습니다... 논문 내용의 50%도 이해를 못 한 채 리뷰를 작성한 것 같습니다.
그래도 이런 낯선 분야와 방법에 대해서 천천히 익숙해질 필요도 있는 것 같습니다. 결국에 내가 하고 있는 분야의 논문만 읽으면 새로운 insight를 얻기 어렵기 때문입니다.
리뷰 읽어주셔서 감사합니다.



