Preliminaries
CLIP (Contrastive Language Image Pretraining)
CLIP은 OpenAI가 공개한 Vision-Language Pretrain 방법론입니다. 인터넷 웹에서 수집된 4억 개의 (이미지, 텍스트) 쌍을 이용하여 사전 학습을 수행한 연구입니다.

기존 Contrastive Learning의 패러다임을 아신다면 이해가 빠르겠지만 CLIP은 결국 어떤 이미지와 어떤 텍스트가 올바른 쌍을 가지는지 맞추는 방식으로 학습이 진행됩니다.
이 과정에서 Text Encoder와 Image Encoder는 동일한 embedding space를 가지게 됩니다.
무슨 말이냐면 이미지-텍스트 쌍을 올바르게 찾는 문제를 풀다 보면 Positive pair 간 Image-text representation이 유사해질 수밖에 없고 Negative pair 간 representation은 서로 다른 구별력을 가질 수밖에 없습니다.
대용량 이미지-텍스트 쌍을 가지고 이러한 작업을 반복하다 보면 굉장히 generalization이 잘 된 image-text encoder를 얻을 수 있는 것입니다. 많은 논문들이 이렇게 사전 학습된 CLIP Encoder를 활용하여 다양하게 후속 연구를 진행하고 잇습니다.
GLIP (Grounded Language-Image Pre-training)
CLIP의 자매품 GLIP입니다. CLIP은 image-text pair 간 global 한 matching을 수행한 반면 GLIP은 region-text 간 local matching을 통해서 사전 학습을 진행하여 특히 object detection과 같은 task에 높은 zero-shot 성능을 자랑한다고 합니다.
아무래도 SGG task가 object 객체 간의 관계를 모델링하는 과정에서 이를 open-vocabulary 문제로 해결하려고 하니 CLIP 보다는 GLIP이 더 적합하여 저자도 Vision Language Model로 GLIP을 활용하고 있습니다.
Introduction
Scene Graph Generation은 이미지에 존재하는 객체와 객체들 간의 관계를 예측하는 작업으로 High-level Scene Understanding 능력을 요구로 합니다. Scene Graph의 구성 요소는 크게 세 가지로 구분이 됩니다. 1) Subject, 2) Predicate, 3) Object로 세 가지가 존재하게 됩니다.
<subject, predicate, object>
즉, 이미지를 설명할 수 있는, 주어, 서술어, 목적어로 구성된, triplet을 잘 찾는 것이 최종 목적이라 보시면 됩니다. 하지만 이 Scene Graph Generation이라고 하는 task는 상당히 어려운 task라 볼 수 있습니다. 객체를 잘 찾는 것도 어려운데, 이 객체들 간의 semantic relationship까지 예측해야 하기 때문이죠.
그 높은 난도 때문에 기존 연구들은 box annotation과 predicate annotation을 같이 활용하는 fully-supervised 환경에서 연구를 진행하였습니다. 이미지 내의 객체들의 위치와 각 객체들끼리의 관계는 어떤 것들이 있는지 모델에게 알려주고 학습을 시키는 것이죠.
당연히 annotation이 있으면 좋지만 box 좌표뿐 아니라 이 객체들과의 relation을 적절하게 할당해줘야 해서 그 비용이 더욱 크다고 볼 수 있습니다. 저자는 이러한 annotation 문제를 지적합니다.
Scene Graph Generation이라는 task가 진짜 application level에서 충분히 활용되기 위해서는 Fully Supervised가 아니라 Weakly Supervised로 가야 한다는 것이죠.
Fully Supervised의 경우는 <subject, predicate, object>에서 subject와 object를 나타내는 box 좌표들을 제공하고 그들 간의 관계 정보인 predicate까지 모델에게 알려줍니다. Weakly Supervised의 경우 박스 좌표와 predicate는 제공되지 않습니다. 대신에 이미지를 설명하는 caption이 제공됩니다. 그리고 이 caption을 가지고 <subject, predicate, object>를 잘 생성해야 합니다. 따라서 난이도가 더 어렵다고 볼 수 있지만 나아가야 할 방향이기도 하지요.
또한 저자는 기존 연구들이 closed-set 환경에서만 문제를 푸는 것에 대해서 한계를 지적합니다. 실제 application level에서 학습 단계에서 보지 못한 객체들이 존재할 수 있지만 기존 연구들은 이런 open 시나리오에 대한 고려가 거의 없었습니다.
따라서 저자는 기존 연구들이 집중하지 못했던 부분인 Weakly Supervised + Open Vocabulary 시나리오 상황에서 Scene Graph Generation 문제를 해결하려고 합니다.
논문에서도 본 연구의 포지셔닝을 위해 위와 같이 테이블을 정리하여 만들었습니다.
- Fully Supervised + Closed-set : 초창기의 연구들이라 볼 수 있습니다. 물론 현재에도 많은 어려움이 존재해서 해당 세팅에서의 연구도 활발하게 이루어지고 있습니다.
- Weakly Supervised + Closed-set : Language description을 가지고 Scene Graph Generation 모델을 학습시킬 수 있는 Weak Supervision 잘 정의하는 것이 핵심입니다. 이미 여러 연구가 있고 본 연구도 이러한 Weakly Supervised 세팅이라 볼 수 있습니다.
- Fully Supervised + Open-vocabulary : 2022년 ECCV에 Towards Open-vocabulary Scene Graph Generation with Prompt-based Finetuning 개제 된 논문이 바로 이 문제를 해결하기 위해 등장했습니다. 결국 Vision Language Model (VLM)에 의존적인 연구들이라 CLIP의 등장 이후 연구가 본격적으로 시작되었다고 볼 수 있겠네요.
- Weakly Supervised + Open-vocabulary : 새롭게 본 논문에서 해결하려는 문제라고 볼 수 있습니다. 가장 어려운 세팅이라고도 볼 수 있을 거 같습니다.
그렇다면 일단 저자가 어떠한 문제를 해결하려고 하는지는 충분히 설명이 됐을 거 같습니다.
보통 Open-Vocabulary 연구들은 Vision Language Model (e.g., CLIP)을 많이 활용합니다. 처음 보는 물체에 대해서 general representation을 제공할 수 있기 때문입니다. 여기서 Scene Graph Generation은 object 객체와 대응되는 phrase 간의 feature alignment가 중요하다고 볼 수 있습니다.
그래서 global 하게 image-text pair 간 사전 학습을 진행했던 CLIP 보다는 region-text pair간 사전 학습을 진행했던 GLIP이 조금 더 적절하다고 판단되어 저자는 GLIP을 활용하려고 합니다.
그러고 나서 Weak Supevision을 위해서는 WordNet이라는 것을 활용합니다. WordNet은 프린스턴 대학교에서 구축한 유의어 DB인데, 유의어 사이의 관계를 그래프로 정의하고 있는 방대한 데이터라고 합니다. 이 WordNet을 이용하여 유사한 단어를 파악할 수 있고, 각 단어의 유사도를 계산할 수 있다고 하네요.
아래의 그림처럼 "A man holds a baseball bat on the ground."라는 문장이 돌아오면 우선 명사와 서술어를 구분하고 명사는 node 서술어는 edge로 표현하되, WordNet을 기반으로 유사도를 계산하고 그래프로 만들어주는 것이죠.
정리하면 Language description이 들어오면 명사, 서술어 구분해서 WordNet을 태워주고 그래프에 대한 Weak Supervision을 정의합니다.
학습 과정에서는 GLIP을 이용하여 visual + text feature을 뽑아내고 Weak Supervision을 가지고 최적화를 진행합니다.
추론 단계에서는 처음 보는 객체에 대한 text prompt를 던지고 학습된 feature와의 유사도를 비교하여 open-vocabulary 상황에서의 예측을 수행합니다.
방법론 자체는 기존의 연구들을 사용한 느낌이 들지만, 아직 학계에서 연구되지 않은 어려운 세팅에서의 베이스라인을 잘 잡아준 논문이라 생각이 드네요.
본격적으로 제안하는 방법론에 대해서 좀 더 자세히 알아보도록 하겠습니다.
Method
The Proposed VS3 Model
GLIP
저자는 앞서 설명했듯 Scene Graph를 구성하는 relation predict을 위해 GLIP을 활용했습니다. GLIP은 Image Encoder와 Text Encoder 가 각각 구성이 되어 있습니다.
우선 Image Encoder EncI 는 Swin Transformer 기반으로 사전 학습이 되었고, region/box feature ¯O∈R¯N×D 를 추출한다고 합니다. 즉, 입력 이미지가 들어왔을 때 ¯N개의 영역 후보군을 생성합니다.
다음으로 Text Encoder EncL 는 BERT 기반으로 사전 학습이 되었고, word/token embedding ¯P∈R¯T×D 를 추출한다고 합니다. Text prompt는 "name(c1). name(c2). ⋯name(c|Co|)."와 같이 사용합니다.
그리고 GLIP은 cross modal fusion module을 활용하여 두 모달리티의 context를 고려하여 표현력이 강화된 feature (¯O→˜O,¯P→˜P)를 사용합니다.
그리고 region feature와 text feature를 내적 하여 region-word alignment score ˆSground=˜O⋅˜PT∈R¯NׯT를 얻을 수 있습니다.
Bounding Box ˆB=boxpredictor(˜O)∈R¯N×4는 강화된 region feature에 box_predictor를 활용하여 예측을 수행합니다.
Relation embedding module
GLIP 방식을 Scene Graph Generation에 맞게 relation recognition을 할 수 있도록 하기 위해 저자는 relation embedding module을 제안합니다. 예측된 region 중에서 top-N개의 region 만을 사용하여 비교적 확실한 영역을 사용하고 그것들 중에서도 NMS를 통해 한번 더 필터링을 해줍니다.
이렇게 검출된 region은 각각 하나의 object를 표현할 수 있습니다.
임의의 subject-object pair가 존재한다고 했을 때 relation representation은 아래와 같이 표현할 수 있습니다.
- pairi→j=cat[pairvisuali→j,pairspatiali→j]
확인해 보면 visual feature와 spatial feature의 concat 연산을 통해 정의되고 있습니다.
우선 visual feature는 아래와 같이 정의됩니다.

여기서 fdiff와 fsum은 2-layer MLP로 구성된 mapping function이라고 합니다. 보면 object feature의 차이(diff)와 합(sum)을 입력으로 넣어 새롭게 projection을 시키고 있습니다.
다음으로 spatial feature는 아래와 같이 정의됩니다.
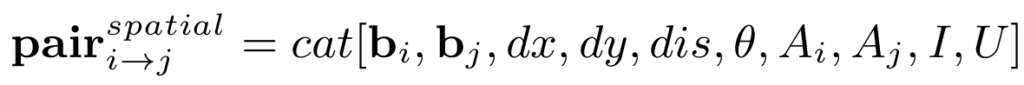
임의의 두 object oi,oj 에 대해서 normalize 된 박스 좌표의 중심점을 ctxi,ctyi 그리고 ctxj,ctyj 이렇게 정의하도록 하겠습니다.
이때
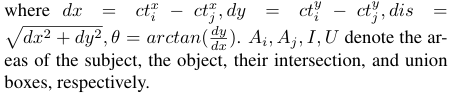
박스 좌표로부터 발생하는 위치 차이, arctan, 합집합, 교집합 등 다양한 spatial 정보를 취합하여 spatial feature를 정의해주고 있습니다.
Relation Prediction
Relation Prediction은 두 가지의 손실 함수를 통해서 학습됩니다.
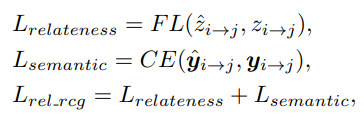
우선 objectness와 비슷하게 relateness를 측정합니다. 두 object 간 관계가 있는지 없는지 예측을 수행하는 것이죠.
- ˆzi→j=frelateness(pairi→j)∈[0,1]
여기서 relateness는 focal loss를 가지고 최적화를 시키네요. 특별한 이유가 있는 건 아니고 hard example에 좀 더 집중하기 위해 사용하는 디테일인 것 같습니다.
다음으로는 관계가 존재한다고 했을 때 무슨 관계인지도 예측을 수행해야겠죠.
- ˆyi→j=fsemantic(pairi→j)∈[0,1]|Co|
여기서 fsemantic 이나 frelateness는 MLP로 구성된 predictor라고 보시면 됩니다.
잠시 정리해 보면 크게 복잡한 부분은 없었으며 GLIP을 가지고 기본적으로 region feature를 정의했고 이를 바탕으로 relation representation인 pairi→j를 정의했습니다. Relation Prediction을 위한 예측 값을 어떻게 생성했는지 알아보았습니다.
이제는 학습 라벨을 language description로부터 어떻게 생성하는지 확인해 볼 차례이네요.
Obtaining Language Scene Graph Supervision
본 논문은 앞서 계속 설명한 것처럼 Fully Supervised가 아닌 Language description만을 활용하는 Weakly Supervised 방법입니다. 사실 저자가 제안하는 Weak Supervision을 얻는 방식이 제가 봤을 때는 그렇게 novel 하다고는 볼 수 없지만, simple한 것은 맞습니다. 정확히 어떻게 수행하는지 같이 확인해 보도록 하겠습니다.
기본적으로 text description이 들어오면 Scene Graph Parser를 가지고 명사와 동사를 구분합니다 SGtext=[Otext,Rtext]. 여기서 Scene Graph Parser는 저자가 제안하는 것이 아니라 기존에 잘 구현된 library입니다.
결국 기존에 구현된 language parsing tool을 사용하여 명사와 관계를 분리하는 작업을 먼저 진행했다고 보면 됩니다.
"Rock near the track under the train, in front of the mountain"
- 명사(object) : Rock, track, train, mountain + "no object"
- 관계(relation) : near, under, in front of + "no relation"
하지만 이렇게 parsing 된 object, relation 단어들이 굉장히 free 한 형식을 가지기 때문에 우리가 target으로 하는 데이터 셋과는 연관이 없을 수도 있습니다. 따라서 기존에 잘 정의된 데이터 베이스인 WordNet을 활용하여 VG150에 존재하는 유의어들로 matching 시켜주는 작업을 진행했다고 합니다.
위에서 SGtext=[Otext,Rtext]를 VG150에 맞게 잘 parsing 했다면 이제는 사전 학습된 GLIP에 입력으로 triplet 형식의 text prompt를 넣어주고 box를 검출합니다.
이때 box의 퀄리티를 보장하기 위해 가장 높은 score의 box를 활용하고 NMS를 태워 Weak Supervision으로 제공하는 것이죠.
사실 이게 전부입니다. Description을 Scene Graph Parser를 통해 object와 relation을 구분해 주고 WordNet을 통해 한번 유의어로 필터링을 해줍니다. 그다음에는 GLIP과 thresholding 연산을 통해 pseudo label을 정의해주고 있습니다.
Transferring to Open-vocabulary SGG
새로운 object를 예측하는 방법은 단순합니다. 입력으로 같이 던져주는 text prompt에 추가하면 됩니다.
name(c1). name(c2). ⋯name(c|Cbase|).
위의 text prompt는 base category만 대응할 수 있다면
name(c1). name(c2). ⋯name(c|Ctarget|).
아래의 text prompt는 우리가 원하는 target category까지 대응할 수 있습니다.
이때 우리가 relation representation을 class-agnostic 하게 정의했기 때문에 굉장히 일반화된 성능을 기대할 수 있다고 하네요. 이를 위한 ablation 실험도 준비되어 있다고 합니다.
네 이렇게 해서 방법론은 다 설명을 드렸습니다. 방법론 자체는 굉장히 단순하게 구현을 한 것 같습니다. 이제 실험 결과 확인 해보도록 하겠습니다.
Experiments
Datasets and Experimentals Settings
여기서 활용되는 데이터 중에서 VG caption은 이미지 당 50개 정도의 dense 한 caption이 있어 비교적 학습이 잘 되었을 것이고 CoCo caption은 이미지 당 5개밖에 존재하지 않아 inference 성능이 조금 떨어질 수 있습니다. 이러한 사실음 감안하고 실험 결과를 보면 좋을 것 같습니다.
본 논문에서 하는 실험은 기본적으로 SGDet 세팅을 따르고 있습니다. 가장 어려운 SGG sub-task라 볼 수 있는데 쉽게 얘기하면 box부터 category 정보 모두 scratch 방식으로 예측하고 Scene Graph를 예측하는 것입니다.
GLIP의 pretraining 과정에서 VG150 test split과 겹치는 데이터가 존재하여 해당 데이터는 평가 시 제외를 했다고 합니다.
마지막으로 GPU는 2080 8대를 활용했다고 하네요.
Fully Supervised SGG
Fully Supervised SGG 세팅은 위에서 Description 받고 Scene Graph Parser 사용해서 pseudo label 정의하는 방식으로 학습하는 것이 아니라 그냥 라벨 다 써서 학습한 것으로 보면 됩니다. 즉, method 부분에서 Obtaining Language Scene Graph Supervision 이 사라졌다고 보시면 됩니다.
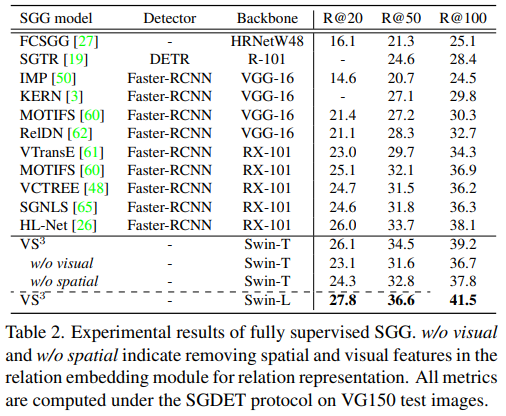
테이블을 보시면 기존의 방법들은 무거운 Detector (e.g., Faster R-CNN or DETR)에 의존적인 모습이었지만 제안하는 방식은 그러한 detector 없이 비교적 가벼운 추가 MLP만을 활용하여 가장 높은 성능을 보여주고 있습니다. 물론 백본의 차이가 존재하고 있지만 GLIP을 활용했으니 이건 어쩔 수 없는 부분인 것 같습니다.
parameter나 flops를 보통은 리포팅을 하지 않기 때문에 이러한 차이는 감안하고 보시면 될 거 같습니다.
Language Supervised SGG
Language Supervised SGG 세팅은 저자가 제안하는 방식으로 Weak Supervision을 활용했을 때의 성능입니다.
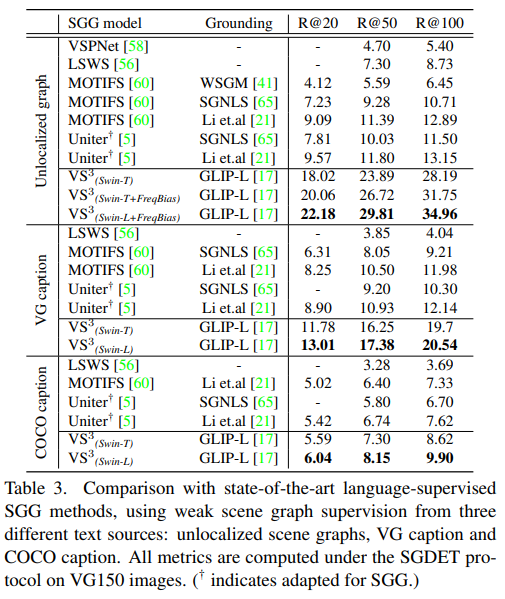
여기서 unlocalized graph 세팅은 GT triplet을 활용했을 때의 실험 결과라고 합니다. 결국 모든 세팅에서 가장 높은 성능을 보여주고 있습니다. COCO caption의 경우는 이미지 당 5개의 caption만 존재하기 때문에 꽤나 어려운 task라 볼 수 있고 그래서 성능 향상 폭도 그렇게 크지 않는 것을 확인할 수 있습니다.
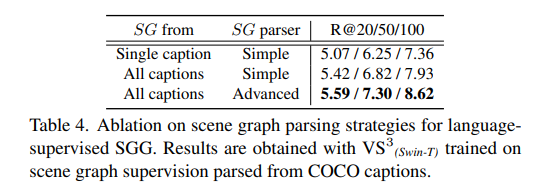
다음은 parsing 과정에서의 ablation입니다. 당연히 하나의 caption만 활용하는 것보다는 모든 caption을 활용해서 정보를 많이 사용하는 것이 성능이 높고 SG parsing 과정에서 simple과 advanced가 있는데 (이거에 대한 설명은 안 나와있네요) advanced가 더 좋더라... 이렇게 서술되어 있네요.
Open vocabulary SGG\
다음으로는 Open-vocabulary 상황에서의 실험입니다.
Ov-SGG는 base category 70%로 학습시키고 평가 과정에서는 base (70%) + novel (30%)로 평가한 것이고
ZsO-SGG는 base category 70%로 학습시키고 평가 과정에서는 novel (30%)만 평가한 것입니다.
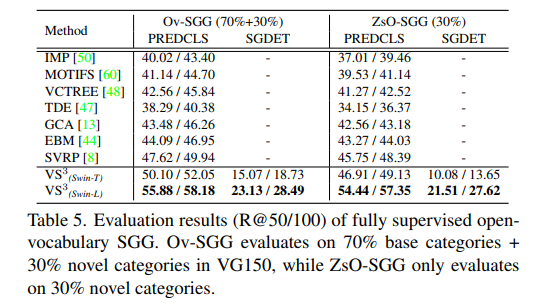
기본적으로는 성능이 가장 높지만 사실 저기 보이는 SVRP랑 직접적으로 비교를 하는 것이 맞습니다. 그렇게 비교했을 때는 백본이 Swin-T 일 때는 성능 차이가 그렇게 많이 나는 거 같지는 않네요.
이게 백본이 달라질 때 성능 차이가 심한 걸 보면 어쩌면 백본 차이로 인한 성능 차이 일 수도 있겠다는 생각이 듭니다.
암튼 정리하면 PredCLS 세팅에서는 가장 높은 sota를 보여주고 있고 SGDet 세팅에서는 한 번도 시행되지 않는 평가를 진행하여 새로운 베이스라인을 구축하였습니다.
Conclusion
해당 논문은 코드를 잘 공개해 줘서 아마 2024년 CVPR 논문들이 github를 본격적으로 공개하기 전까지는 제가 이 코드를 베이스로 원복 실험도 해보고 여러 가지 동작 과정을 분석해 볼 거 같습니다.
조금 걱정인 부분은 제가 다음에 리뷰할 2024년 CVPR 논문도 결국에는 BLIP이라고 하는 거대 모델에 의존적인 모습을 보여주는데 저희 연구실 레벨에서 실험을 돌릴 수 있을지가 조금 걱정이 되네요.
리뷰 읽어주셔서 감사드립니다.



