CS231n의 시작은 컴퓨터 비전 분야에서 가장 흔하면서도 중요하게 여겨지는 Image Classification에 대한 내용으로 시작합니다.
컴퓨터에게 있어서 이미지 분류는 왜 어려운 걸까요? 인간이 사진을 보고 받아들이는 정보와 컴퓨터가 받아들이는 정보는 의미론적 차이(Semantic Gap)가 존재합니다.

우리가 고양이 사진을 보면 우리의 뇌는 어떠한 복잡한 처리를 거쳐서 판단을 내립니다. 이건 고양이다!! 하지만 컴퓨터가 보는 고양이 사진은 단순한 픽셀 정보만 담긴 행렬만을 받아들이게 됩니다.
더군다나 이미지 분류에 있어 컴퓨터가 다양한 변화에 강인하도록 설계하는 것은 더더욱 어려운 일입니다.

위의 사진을 보면 다양한 변화에 대해 인간은 쉽게 쉽게 구별을 할 수 있지만 이 작업은 컴퓨터에게 쉽지 않은 작업이 될 것 같습니다.
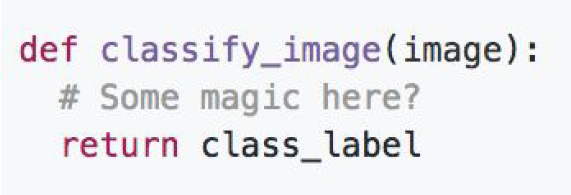
예를 들어 컴퓨터가 잘하는 정렬 알고리즘이나 그래프 알고리즘 이런 것들은 명확한 Solution이 존재합니다. 하지만 이미지를 보고 종류를 분류해라 하는 작업에 대해서는 명확한 Solution이 존재하지 않습니다.
그래서 고안이 된 방법은 Data-Driven Approach라고 해서 우선 dataset을 모은 뒤, 어떤 데이터의 분포를 이해하고 분류할 수 있는 Machine Learning 알고리즘을 설계하고, 새로운 데이터에 대해서 평가를 해보자! 이러한 흐름으로 진행이 됩니다.
이미지를 분류하기 위해 이제는 학습과 예측이라는 두 가지의 흐름으로 나뉘었다고 생각하시면 됩니다. 데이터를 통해 무엇인가 학습을 진행합니다. 학습을 한다는 것은 결국 학습 데이터의 분포를 이해하는 과정이라 생각하면 됩니다. 그리고 난 뒤 새로운 데이터를 가지고 평가를 진행하게 되는 것이죠.
머신러닝이라고 불리는 방법론의 큰 틀은 학습 데이터를 통해 일반적인 데이터의 분포를 학습하고 평가 데이터를 통해 방법론의 성능을 평가하는 식으로 진행이 됩니다. 그렇다면 가장 간단한 Nearest Neighbor classifier 알고리즘에 대해서 알아보면서 본격적인 이야기를 시작해보도록 하겠습니다.
Nearest Neighbor
나중에 더 자세히 설명하겠지만 결국 머신러닝/딥러닝 방법론은 데이터를 설명하는 특징(Feature)을 기술하게 됩니다. 머신러닝 방법론에서는 데이터의 특징을 추출하기 위해 전통적인 알고리즘(Hand-crafted) 방식을 사용하며 딥러닝 방법론에서는 신경망(Neural net) 기반의 방식을 사용하여 특징을 추출합니다.
특징들은 결국 어떠한 벡터로 표현되기 때문에 어떠한 벡터 공간(Vector Space) 내에서 정의된다고 생각할 수 있습니다. 이를 특징 공간(Feature Space)라고도 표현을 하는데요 Nearest Neighbor 방법은 특징 공간 내 정의된 특징들끼리의 distance 기반으로 회귀나 분류 문제를 해결한다고 보면 됩니다.
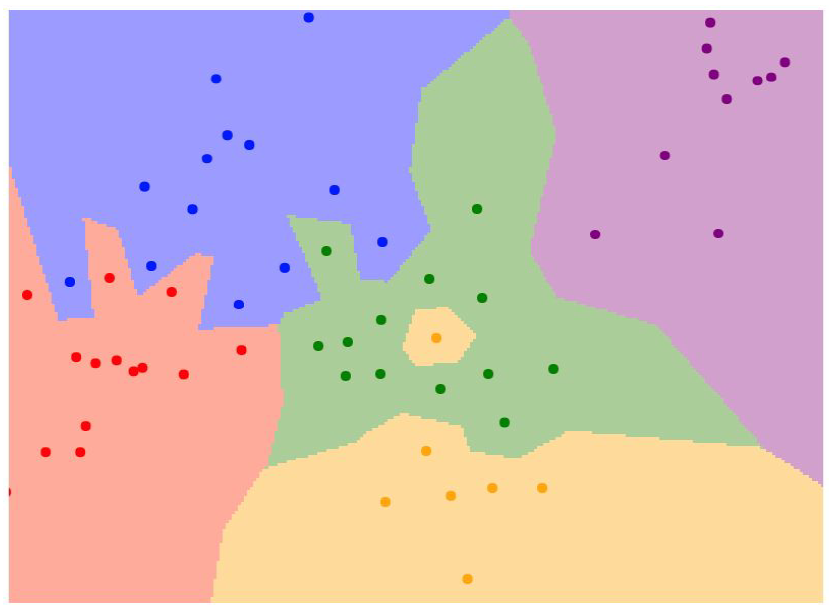
우리가 어떠한 특징 공간을 2차원으로 가정을 한다면 이런 식으로 각 데이터의 특징들의 분포를 시각화할 수 있을 것 같습니다. 대충 보면 거리가 가까운 점들끼리 비슷한 색깔로 묶여있는 그림을 볼 수 있는데 이게 K-NN 알고리즘의 결과라 볼 수 있습니다.
좀 더 자세히 설명을 해보자면 학습 데이터를 우선 Feature로 잘 기술을 한 뒤, 이를 모두 특징 공간에 뿌려줍니다. 특징 공간 내에서는 주변 feature들 중에서 distance가 가까운 k개의 후보군을 살펴보고 voting을 진행합니다. voting을 진행해서 가장 많은 클래스로 feature를 할당시킨다 보면 됩니다.
따라서 학습 데이터가 자체가 모델이며 어떠한 추정 방법도 모형도 존재하지 않습니다. 즉, 데이터의 분포를 표현하기 위한 모델의 파라미터를 추정하지 않는다는 이야기입니다.
심플한 방법이지만 특징의 차원이 낮은 경우에는 성능이 또 낮지만은 않아서 feasibility 확인하기에 적당한 방법론입니다.

넘 파이로 구현된 NN 알고리즘이 있습니다.
train은 그냥 데이터를 담아 놓는 과정이 끝이네요. 데이터 자체가 저희의 모델이 되는 것입니다.
predict은 새로 들어온 X에 대하여 학습 데이터와 distance를 측정하여 낮은 순으로 sorting 하여 label을 저장해주고 있습니다.
return으로 받는 Ypred 배열에서 top-k 개만큼 참조해서 voting을 진행한다면 예측을 수행할 수 있을 것 같네요.
그렇다면 고려해야 할 점이 무엇이 있을까요?
1. 거리를 어떠한 지표로 측정할 것인가?
거리를 어떻게 계산하는 지도 KNN 알고리즘의 예측 성능에 꽤 영향을 끼칩니다.

어떤 metric을 사용할지는 problem 마다 다르기 때문에 왕도가 없지만 일반적으론 L2가 General 하게 작동한다고는 합니다.
2. 예측값을 산출하는 데 필요한 Top-K의 개수는 어떻게 설정할 것인가?
몇 개의 후보군을 가지고 voting 하게 될지도 예측 성능에 중요한 요소입니다.

K가 작을수록 좁은 영역만 보기 때문에 학습 데이터에 overfitting 될 가능성이 높습니다. 반대로 K가 너무 클수록 모델이 과하게 underfitting 될 가능성이 높습니다.
방금 위에서 설명한 두 가지의 요인인 1) 거리 측정 방법 , 2) 후보군 개수는 사용자가 임의로 설정해야 하는 파라미터로 하이퍼 파라미터(hyperparameter)라 부릅니다. 최적의 거리 측정 방식과 후보군 개수는 데이터마다 다르기 때문에 보통은 Grid Search 방식으로 best parameter를 찾곤 합니다.
KNN은 하이퍼 파라미터를 찾아야 하는 것 말고 또 다른 한계점을 가지고 있습니다.
우선 KNN 알고리즘의 계산 복잡도는 어떻게 될까요?
Computational Complexity : $O(n)$
N개의 데이터에 대해서 모두 거리를 비교해야 하니 N번만큼의 연산이 필요로 하며 이는 학습 데이터의 양이 많아질수록 한계점이 될 수 있습니다.
또 다른 하나는 차원의 저주(curse of dimension)입니다.

간단하게 하나의 차원을 덮기 위해 필요한 data가 4개라고 가정해보겠습니다. 특성 공간이 2차원이 된다면 이 특성 공간을 모두 덮기 위해서는 16개의 data가 필요합니다. 다시 3차원이 된다면 64개의 data가 필요하고 결국 feature의 차원이 증가할수록 feature가 정의되는 특정 공간의 부피는 기하급수적으로 증가하며 동일한 데이터의 밀도는 차원이 증가할수록 급속도로 sparse 해지게 됩니다.
이미지 같은 경우는 픽셀 단위로 처리하게 된다면 차원의 수가 몇백, 몇천으로 굉장히 커지기 때문에 실제 이미지 분류를 해결하는 데 있어서 KNN은 적합하지 않습니다.
여기까지 해서 우선 간단한 머신러닝(?) 알고리즘인 Nearest Neighbor에 대해서 알아보았습니다. 직관적이기 때문에 이해하는 것에 있어서는 어려움이 없었을 것 같고, 이 방법론의 한계점까지 알아보았습니다.
Linear Classifier
이제는 또 다른 방법인 선형 분류기(Linear Classifier)라는 것에 대해서 알아보도록 하겠습니다.
선형 분류기도 간단합니다. 특징 공간 내에서 특징 간의 경계를 Linear Boundary로 정의해서 데이터를 이해해보겠다 이렇게 정리할 수 있겠습니다. 선형 대수학을 공부하였다면 이해가 쉬울 것 같습니다.
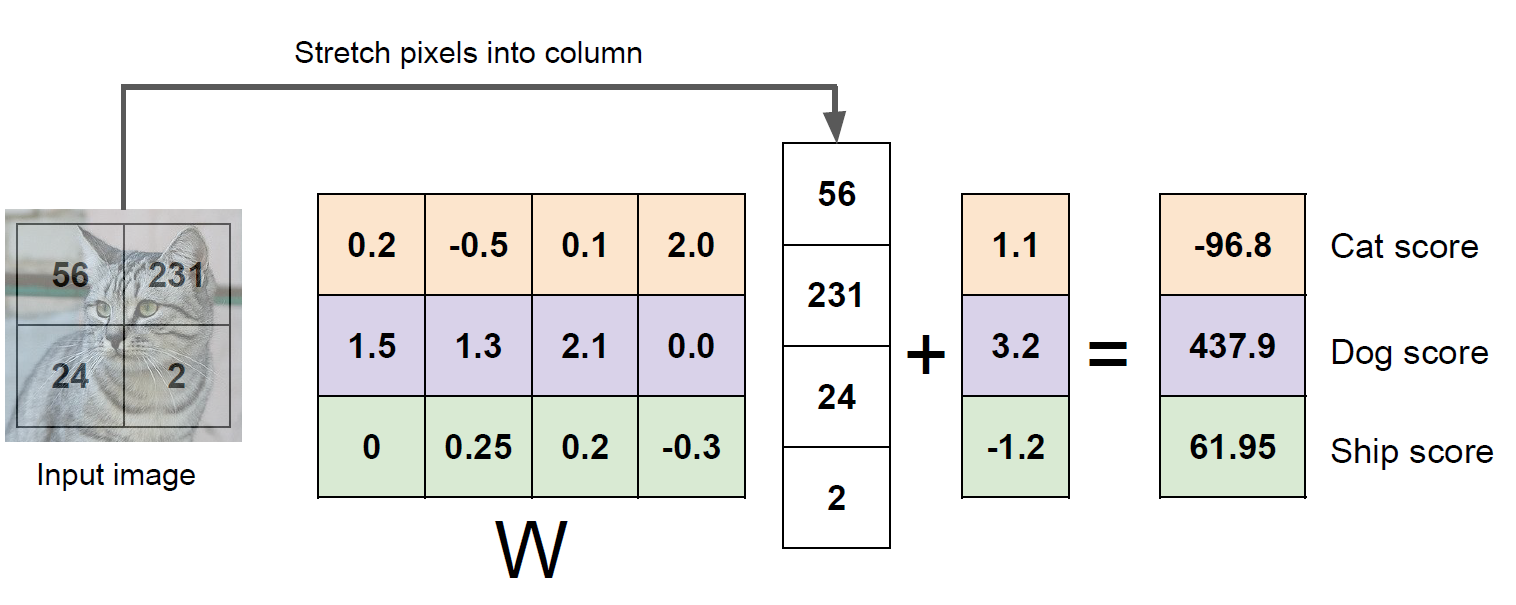
대부분 이미지의 픽셀 값을 특징으로 바로 사용하진 않겠지만 간단히 설명을 위해 여기서는 픽셀 정보를 이미지의 특징으로 사용하였네요. 자 위의 사진을 보면 뭔가 가중치 행렬을 feature에 곱하고 bias 벡터를 더해주었더니 결과를 score 벡터라고 표시하고 있네요. 선형 분류기의 아이디어는 저기서 score가 가장 높은 class를 예측 값으로 정의하겠다 이것인데
좀 더 자세하게 한번 이해해보도록 하겠습니다.
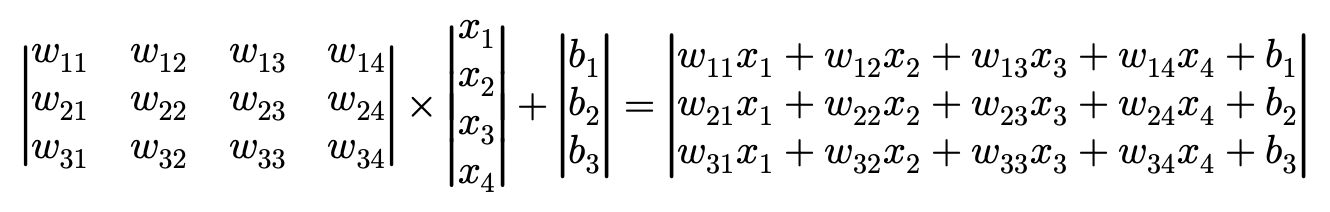
이렇게 일반적인 formulation 형태로 바꿔보았습니다. 결국 저 score는 어떻게 구해지는 걸까요? parameter와 feature 간 Linear Combination으로 정의됩니다.
- $score_{cat}=w_{11}x_{1}+w_{12}x_{2}+w_{13}x_{3}+w_{14}x_{4}+b_{1}$
저렇게 Linear combination으로 정의된 저 표현은 고차원 벡터 공간상의 hyper plane을 의미합니다. 2차원이라면 직선의 형태를 띨 것이고, 3차원이라면 평면...

그래서 결국 저 hyper plane은 A라는 클래스와 그 외 다른 클래스를 특징 공간 내에서 구분 지어주는 Decision Boundary라 생각할 수 있습니다. 다만 그 Decision Boundary가 Linear 하게 정의되므로 Linear Classifier라고 부르는 것입니다.
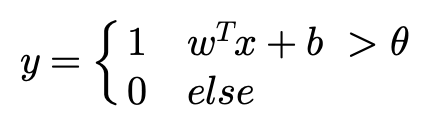
즉 A라는 클래스와 그 외 Other를 구분하는 일종의 Threshold인 $\theta$ 를 가지고 분류가 진행됩니다.
결정 경계가 Linear 하다 보니 직관적이지만 또 너무 단순하다고 생각할 수 있습니다. XOR이라는 문제도 Perceptron으로 해결할 수 없었던 이유가 Perceptron이 만들어내는 결정 경계는 Linear 하기 때문에 Non Linear 한 문제를 풀 수 없었습니다.
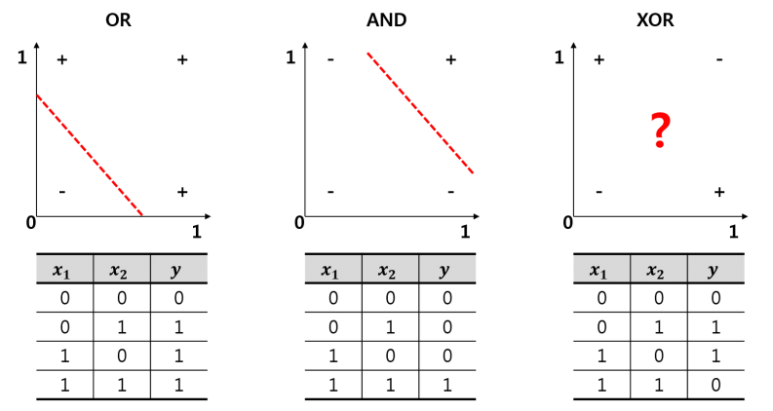
OR이나 AND 문제는 Linear 한 경계를 기준으로 두 가지의 상태가 분류할 수 있었지만 XOR 문제는 어떻게 그어도 제대로 분류를 할 수가 없습니다.
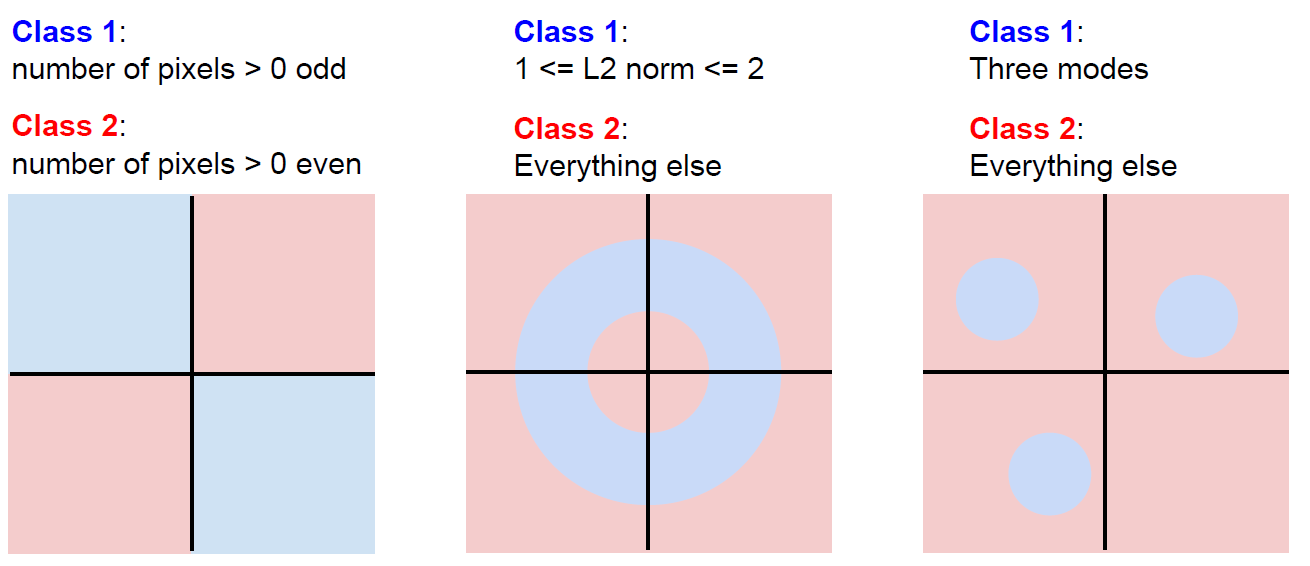
XOR 뿐만 아니라 복잡한 case에 대응할 수 없기에 Linear Classifier는 나름대로의 한계점을 가지고 있습니다.
나중에 다루겠지만 이러한 문제를 해결하기 위해선 Decision Boundary를 Non-Linear 하게 만들어야 할 것 같습니다. 이를 위해 등장한 것이 Activation Function이지요. 그 부분은 차차 알아가는 것으로 하고 우선적으로 Linear Classifier는 결국 복잡한 특징 공간 내에서 클래스와 클래스 간의 구분을 지을 수 있는 선형 경계를 만드는 것이 목적이다 이렇게 정리할 수 있을 것 같습니다.
Conclusion
컴퓨터 비전에서 기본이라고 볼 수 있는 이미지 분류의 Pipeline에 대해서 간단히 알아보았습니다.
KNN 분류기와 선형 분류기에 대해서 알아보았고 각 방법론에 한계점에 대해서도 살펴볼 수 있었습니다.
다음 포스팅에서는 손실 함수(Loss Function)와 간단한 최적화(Optimization)에 대해서 알아보도록 하겠습니다.
'Deep Learning' 카테고리의 다른 글
| [CS231n] 03. Backpropagation and Neural Networks (0) | 2022.03.06 |
|---|---|
| [CS231n] 02. Loss Functions and Optimization (0) | 2022.01.26 |

